













如何在物聯網的邊緣計算中使用Kafka
譯文【51CTO.com快譯】在邊緣技術領域,那些從事制造業、自動化行業、航空、物流、以及零售等行業應用的開發人員經常會思考的一個問題是:到底應該在邊緣處,還是應該在“真實”的數據中心、或是在公共云基礎架構中部署Apache Kafka?
在本文中,我們將向邊緣計算領域的開發者介紹Kafka在物聯網(IoT)邊緣處的不同用例和架構用法。文末,我們還會討論Kafka作為事件流平臺,是如何在邊緣處對其他IoT框架及產品進行補充,進而實現大規模的實時數據集成與邊緣處理。
常態化的多個Kafka群集
如今,Apache Kafka的多集群和跨數據中心的部署方式,已成為了業界的某種規范。雖然“邊緣處Kafka(Kafka at the edge)”可以被部署為一個獨立的項目;但是在大多數情況下,它處于整個Kafka架構中的一部分。許多企業會根據如下原因,來創建多個Kafka集群:
- 獨立的項目需求。
- 混合式的集成方法。
- 邊緣計算。
- 組件聚合。
- 平臺移植。
- 災難恢復。
- 區域或洲際通信所需的全球架構。
- 跨企業之間的溝通。
什么是“邊緣”或“邊緣計算”?
在考慮部署邊緣處Kafka之前,讓我們先來了解一下與“邊緣技術”相關的定義。維基百科上說:“邊緣計算是一種分布式的計算范式。它通過讓計算本身和數據存儲更加靠近所需的位置,從而縮短了響應的時間并節省了帶寬”。同時,它的其他優勢還包括:降低成本,提高系統的靈活性,以及分離關注點。
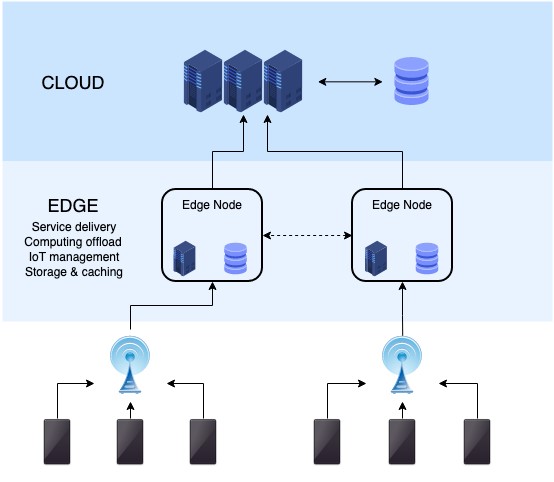
邊緣的Apache Kafka
目前,業界對如何將Kafka應用于邊緣計算有著不同的見解,其中包括:
- 僅在邊緣客戶端:Kafka客戶端運行在邊緣處;而Kafka集群則被部署在數據中心或公共云的環境中。
- 一切都在邊緣:將Kafka集群和Kafka客戶端都部署在邊緣處(例如工廠里的各種傳感器上)。
- 邊緣與遠端:Kafka集群被部署在邊緣;而Kafka客戶端(例如該地區的智能手機)則運行在接近邊緣處。
可見,邊緣處Kafka具有比較靈活且廣泛的使用范圍,其中包括:
- 工業物聯網(Industrial Internet of Things,IIoT)車間邊緣處的Kafka客戶端可以由C語言來編寫,并部署到傳感器的微控制器中。此類傳感器通常只有幾千個字節的內存,而且可以“服役”一定的年限。
- 在電信業務中邊緣處,完整的分布式Kafka集群,可以運行在StarlingX上(https://www.starlingx.io/)。StarlingX是一個基于Kubernetes的開源私有云架構棧,可被用于IIoT、電信、視頻交付、以及其他具有超低延遲等苛刻要求的應用邊緣環境中。
- 通過部署,銜接傳統銀行或保險公司的核心硬件與邊緣硬件。
可見,在大多數情況下,邊緣處Kafka就是指:部署在系統邊緣處的Kafka集群。而對應的Kafka客戶端程序既可以在本地運行,也可以在附近運行。當然在某些情況下,“附近”可能在指幾英里開外。
邊緣處Kafka的用例
下面,我們來討論一下邊緣處Kafka在許多不同企業中的運行用例。
- 工業物聯網:實時邊緣集成與處理,是現代物聯網架構成功的關鍵。在工業4.0中,此類用例比比皆是,包括:預測性維護、質量保證、流程優化、以及網絡安全等方面。其中使用Kafka來構建數字孿生(Digital Twin,譯者注:在虛擬空間中仿真、映射并反映對應的實體設備的整個生命周期過程)就是最常見的場景之一。
- 零售:無論是沃爾瑪這樣的零售商,還是星巴克之類的咖啡店,抑或亞馬遜Go之流的潮店,數字化轉型都會帶來許多方面的創新。其中包括:客戶的360度體驗,商家與消費者之間的交叉銷售,以及與其他合作供應商的協作等方面。
- 物流:大規模的實時數據關聯,是改變任何物流場景的關鍵元素。其中包括:端到端的包裹跟蹤和交付,無人機(或自動駕駛)與本地自助服務站的通信,物流中心的加速處理,共享汽車的協調和計劃,以及智慧城市中的交通信號燈管理等方面。
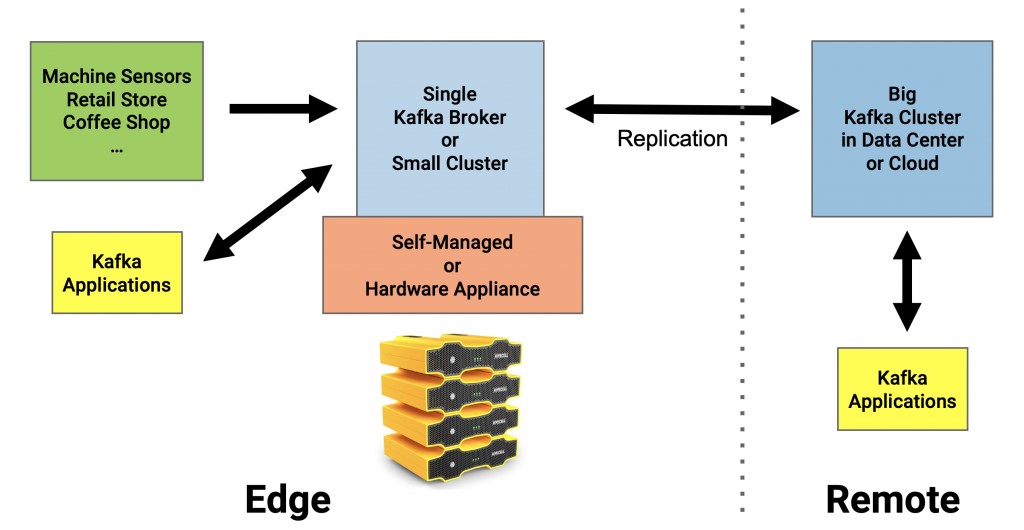
無論是上述哪種用例,邊緣處Kafka的通用架構都會如下圖所示:
邊緣計算的挑戰
在企業試圖將各種創新的實時應用引入工廠、零售店、咖啡店等場景,并將數據分發到邊緣站點時,往往會遇到如下的挑戰:
- 由于不良的網絡狀態和許多其他方面的限制,邊緣處的各種硬件、機器、以及設備難以順暢實現集成。
- 許多用例都要求進行大規模的、且實時的處理。而這些處理都必須在現場邊緣處實施,而不是在遠端的數據中心、或幾百英里開外的云端進行。
- 各種技術和協議都必須在邊緣處集成。而且各種傳統或專有的協議,必須通過隧道,與另一端的大數據工具進行通信。
- 有限的硬件資源與人員。鑒于成本的考慮,IT專家無法到達每一個邊緣站點,進行硬件的運維。
- 各種數據必須大規模地在本地進行實時存儲和處理。同時,這些數據需要被復制到數據中心或云端,以便進一步匯總、處理與分析。另外,為了實現由單一節點以發送命令或事件的方式控制各個邊緣站點,各種通信最好是雙向的。
用于邊緣計算的Kafka架構
在開始討論有哪些邊緣處Kafka的部署方案之前,我們需要事先搞清楚的一個問題是:到底是否需要高可用性的邊緣架構。
其實,邊緣計算并不一定需要具有高可用性。如果您的確需要的話,就請部署傳統的Kafka集群;而如果不需要的話,則只需在邊緣處設置一個簡單、且低成本的Kafka Broker即可。而且如果需要在上百個站點進行部署的話,那么現成的硬件設備會更加容易實現。
下圖展示了三個邊緣站點。每個站點上都部署了一個Kafka集群,而每個集群里都包括有不同的Kafka組件。

通過三個以上的Kafka Broker在邊緣實現彈性部署
Kafka及其生態系統旨在確保即使某一單個節點發生故障,也能實現系統的高可用性和零停機時間。如下圖所示,為了部署一套分布式的系統,您至少需要三個Kafka節點和三個Zookeeper節點。而其他組件則需要至少兩個節點,才能確保操作的可靠性和數據的防丟失。
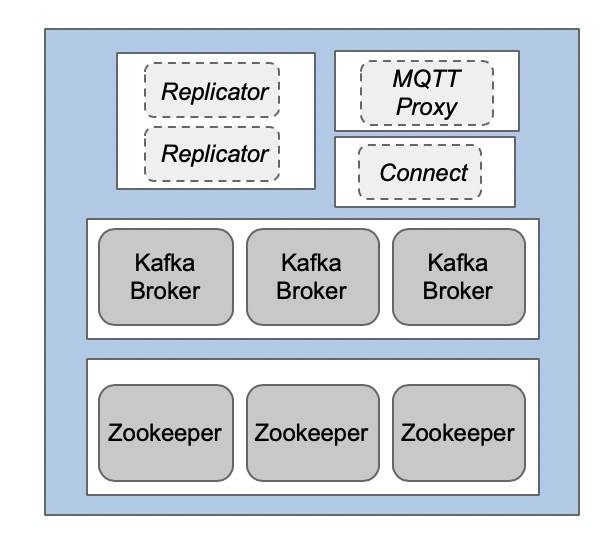
您可以參考《Apache Kafka與Confluent平臺參考架構》一文,以了解部署的最佳實踐。當然,由于流量負載和吞吐量通常在邊緣處都比較低,因此如果SLA允許的話,較少的內存與磁盤空間也就足夠了。
通過一個Kafka Broker在邊緣實現非彈性部署
如今,在邊緣處部署“輕量級的Kafka群集”,然后與更大的中央Kafka群集同步或復制數據的需求已日益增多。不過,由于硬件本身的限制、以及SLA對于高可用性的要求并不高,因此在邊緣處僅部署一個Kafka Broker加上一個Zookeeper即可。如下圖所示,您甚至可以將整個Kafka的環境只部署在一臺服務器上。
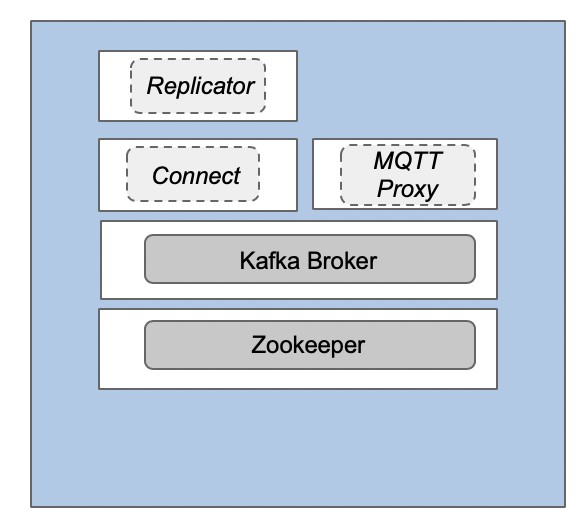
不過,該部署方案存在著一個明顯的缺陷:由于沒有數據之間的復制,當該節點或網絡出現故障而造成停機時,您的數據就有丟失的風險。當然,此類單節點式的Kafka部署方案仍具有如下方面的優勢:
- 實現了producers與consumers之間的解耦。
- 能夠有效地處理背壓(back-pressure)。
- 即使只有一個Broker,也能實現實時地處理大容量數據。
- 在磁盤上進行存儲。
- 能夠重新處理數據。
- Kafka Connect可用于集成,Kafka Streams或ksqlDB可用于流處理,Schema Registry可用于管理,真可謂Kafka本地組件的“全家桶”。
移除ZooKeeper將有助于邊緣處Kafka
和諸如Hadoop、Spark等其他分布式系統類似,由于過分依賴于ZooKeeper,因此Kafka不但在操作上有一定的難度,而且擴展性也比較差。那么對于大多數物聯網項目而言,由于整體部署的耗時較長,我們建議您通過移除ZooKeeper,而使得Kafka更輕量級,更易于操作。
將Kafka作為邊緣設備和云服務之間的網關
在某些配置中,您可能希望邊緣設備與本地的網關進行通信。此時,您就可以使用網關式的Kafka架構方案。例如,在工廠中,多臺機器或生產線被視為邊緣設備。它們需要與各自的Kafka群集相集成,實現將數據發送給作為網關的Kafka群集。據此,在Kafka集群網關上,您可以直接在本地進行分析,通過過濾或轉換數據,最終發送并聚合到遠程大型的Kafka集群中。
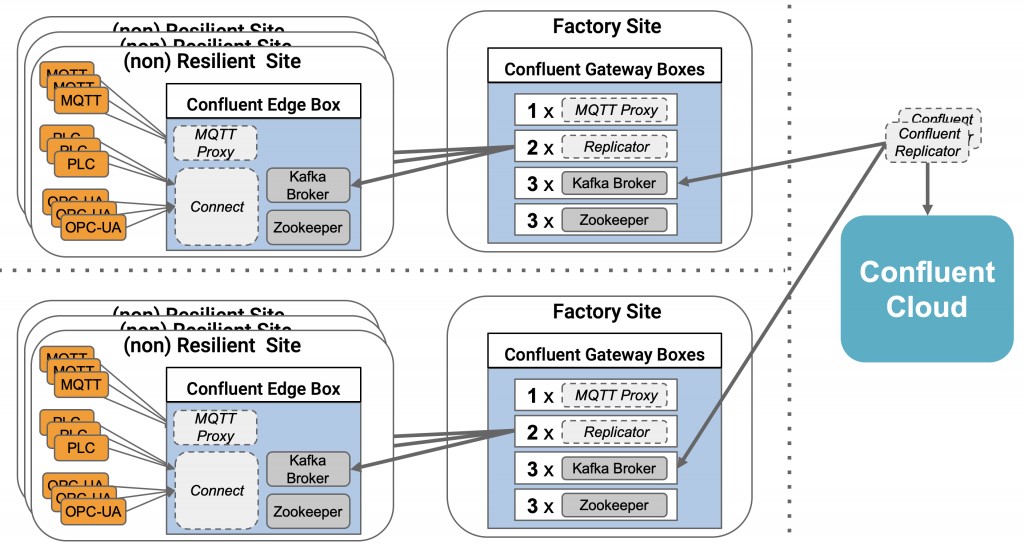
如上圖所示:首先,兩個獨立的工廠分別在各處部署了非彈性的單一Kafka Broker,以實現數據的本地處理。然后,由一個彈性Kafka群集網關聚合三個Kafka Broker,并在工廠的本地處理各項數據。接著,只有那些重要、且經過預處理的數據才會被轉發到遠程的Kafka群集中(在圖中體現為Confluent Cloud)。最終,該云中的Kafka集群聚集了來自不同工廠的數據,以便與其他業務應用或分析工具相集成。
邊緣處Kafka作為OEM或硬件組件
企業在邊緣處安裝硬件,會比在本地數據中心、或公共云端要復雜且麻煩得多。如果我們在邊緣處采用標準化的Kafka組件安裝方法,則會大幅減少工作量與潛在的風險。
目前,已有數十家硬件供應商可以協助您構建OEM的硬件設備。當然,您也可以通過遠程管理并使用某些DevOps工具,來安裝所有必需的軟件組件。
為了簡化安裝和操作邊緣處Kafka集群,以Hivecell(https://hivecell.io/)為代表,公司推出了預裝有Kubernetes、Kafka生態系統、Confluent Operator(https://www.confluent.io/confluent-operator/)工具、以及其他業務應用的產品盒子。它能夠簡化并自動化邊緣處Kafka環境中的各項操作。用戶只需將一個或多個產品盒子運到邊緣站點。在將其連接到本地WiFi之后,其他所有的操作都可以在遠程進行實現。該公司甚至號稱:能夠讓客戶不再需要技術人員,即可在邊緣部署和維護軟件。
通信、連接、集成、數據處理
正如上述各圖所展示的那樣,Kafka的環境中并不僅僅包括了Kafka Broker與Zookeeper。無論是在云端、本地、還是在邊緣處,通信、連接、集成、以及數據處理都是Kafka基礎架構中的重要組件。
具體而言,在Kafka Broker與Kafka客戶端之間,從邊緣處到遠程的通信流程為:設備->邊緣處Kafka->復制->數據中心與云端的Kafka群集->數據分析與實時處理。通常,此類通信是雙向的。那么對于Kafka原生的各個組件而言,您只需要管理一個Kafak的后臺,即可進行大規模的實時通信、集成和數據處理。其中涉及如下方面:
- Kafka Connect:包括MQTT(消息隊列遙測傳輸)、OPC-UA、FTP、CSV、PLC4X(一組傳統與專有IIoT協議,例如Modbus、Siemens S7、Beckhoff、Allen Bradley四種可編程序控制器,即PLC)。
- Mirror maker與Confluent Replicator:實現兩個Kafka群集之間的單向或雙向復制。
- Kafka客戶端(Producers/Consumers):支持Java、Python、C++、C、Go、Javascript等語言。
- 數據處理:使用Kafka Streams或ksqlDB進行流處理(包括無狀態流的ETL和其他有狀態的應用)。
- 代理:使用REST proxy進行HTTP(S)通信,使用MQTT proxy進行MQTT集成。
- 架構注冊表:負責治理與模式的實施。
可見,由于邊緣處硬件資源的受限,我們應當在開始時就規劃好整體架構和數據通信,讓Kafka全棧能夠真正滿足邊緣的需求。
混合架構
物聯網的實際需求往往是五花八門的。面對24小時/7天的實時部署,零數據量的丟失,以及無延遲的實時處理,我們光靠Kafka架構有時會力不從心。此時,我們就需要結合使用其他的IoT框架或方案,來實現與Kafka的端到端集成。
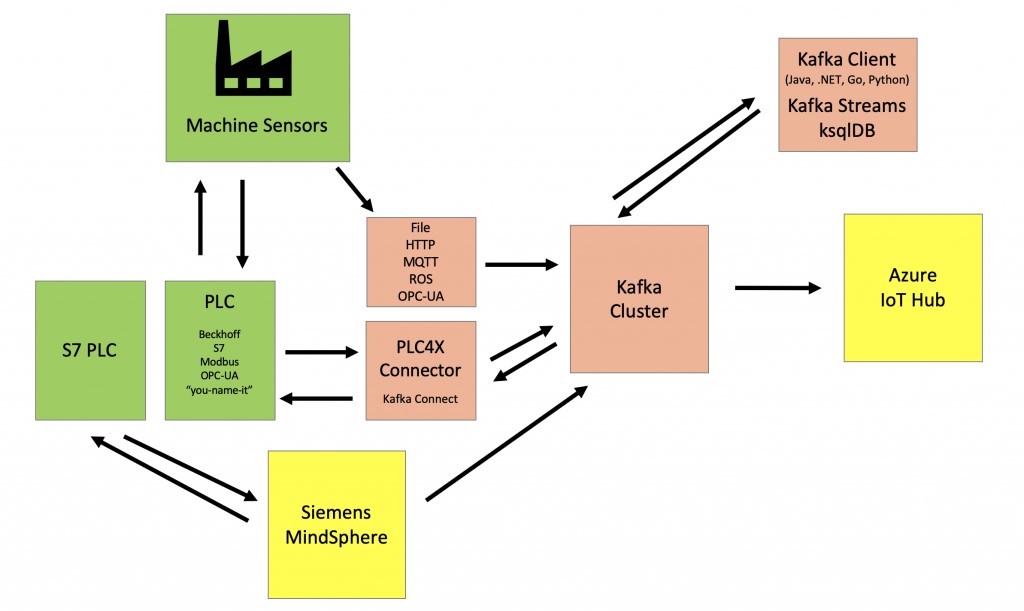
如上圖所示,我們可以在工廠車間里使用西門子的MindSphere(這是一種功能強大,適用范圍廣泛,但也復雜且昂貴的物聯網解決方案),來作為網關或代理。當然,我們可以將HiveMQ(譯者注:一種企業級的MQTT Broker)部署為可擴展的MQTT集群,以連接到機器和設備。
在某些情況下,Kafka也可以被直接用作IoT的網關或代理,以連接PLC或分布式控制系統(Distributed Control System,DCS)。同時,Kafka也可連接諸如AWS IoT或谷歌云的MQTT Bridge等IoT解決方案,實現進一步的處理和分析。
由于數據通信往往是雙向的,因此無論您選擇哪一種架構,都必須能夠從車間或其他IoT設備中提取數據,通過實時的處理與關聯,最后將控制類事件發回給機器。例如:在預測分析中,您首先需要使用TensorFlow之類的云端工具訓練分析模型,然后才能在邊緣處部署分析模型,以進行實時預測。
可見,通過與其他物聯網框架或解決方案的結合,Kafka生態系統不但得到了有效的補足,而且各自都能夠專注于不同的功能用例之中。例如:Kafka可專注于設備管理,模型訓練。主流的云提供商能夠為設備管理提供IoT服務、云端代理、以及分析工具。而開源的框架Eclipse則可以用于構建數字孿生。
慎用過多的分布式系統組合
當然,如果您想為邊緣計算和混合架構構建可擴展的、可靠的流式結構,并且達到不會造成任何宕機或數據丟失的效果,這實際上很難在集成了多種中間件工具的環境中實現。也就是說:參與組合的工具越多,服務中斷或數據丟失的風險也就越高。例如:NiFi(譯者注:Apache的NiFi項目是一種實時數據流處理系統)有著自己的分布式基礎架構,那么您必須保證從producer通過NiFi和Kafka能夠最終到達consumer,這整個過程都具有24小時/7天的端到端正常運行時間。同理,諸如Kafka Connect和Kafka Streams之類的原生工具,使用Kafka Topic在后臺提供高可用性時,您也需要保障此類24小時/7天的無宕機或數據丟失。因此,請慎用“傳感器ABC -> NiFi(捕獲) -> Kafka Topic A -> NiFi(轉換) -> Kafka Topic B -> NiFi(加載) -> 應用程序XYZ”之類的管道架構,來進行無數據丟失的大規模實時處理。
總結
邊緣計算往往只是整個體系結構的一部分,但是作為該領域的“黑馬”,邊緣處Kafka可以通過混合架構的部署方式,提高數據的處理速度,降低網絡的傳輸成本,并且能給整個系統帶來更好可擴展性、可靠性和健壯性。
原文標題:Apache Kafka Is the New Black at the Edge in IoT Projects,作者:Kai Wähner
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】

























