口碑撲街?Python告訴你《囧媽》到底囧在哪里?
“2020 年的春節檔之前被譽為神仙打架,各顯神通,可以說是史上最強的春節檔,不料一場疫情,就換了另一個局面。為配合疫情的防控,春節檔電影全部撤檔。
本以為就這樣沒下文了,結果徐崢打出一張牌:線上免費看《囧媽》,作為發行方的歡喜傳媒股票當天也應聲上漲 42%。今天我們就來聊聊另類春節檔的唯一一部電影《囧媽》。
《囧媽》繞過院線,全網免費看
在《姜子牙》《唐人街探案 3》等片紛紛撤出春節檔之時,《囧媽》突然宣布將于大年初一零點起,在抖音、西瓜視頻、今日頭條、歡喜首映等 App 上免費上映,成為史上首部繞過院線直接網播的春節檔電影。
《囧媽》主要講的是小老板伊萬纏身于商業糾紛,卻意外同母親坐上了開往俄羅斯的火車。在旅途中,他和母親發生激烈沖突,同時還要和競爭對手斗智斗勇。
為了最終抵達莫斯科,他不得不和母親共同克服難關,并面對家庭生活中一直所逃避的問題。
徐崢這次把《囧媽》免費讓觀眾看的舉措,讓《囧媽》在慘淡的春節檔賺足了足夠的熱度,字節跳動也收獲了大量的流量。該片三天總播出量超過 6 億人次,觀眾總數為 1.8 億人次。
敢做第一個吃螃蟹的人
回望中國電影「大票房」時代,國內首部票房破 10 億的國產電影就是徐崢在 2012 年的作品《人再囧途之泰囧》,達到 12.67 億,之后國產電影就像打了雞血一樣,一個又一個破新高。
當然這里面有 50% 的功勞要算在 2010 年前作《人在囧途》的精彩上,讓影迷們覺得囧系列和徐崢是品質保證。
記得當時看完《人在囧途》,就說下次徐崢再拍囧系列一定要去電影院支持,這種口碑效應在電影里面特別明顯。可能正是這樣的藝高,所以才膽大。
這次《囧媽》直接選擇線上首映,同時還把錢給掙了,弄的電影院聯名聲討,了解一下過程,你就懂了。
原來的形式是發行方歡喜傳媒拍好了電影,賣給橫店影視,保底 24 億票房。
然后橫店影視去找全國的電影院,你們幫我放這部電影,最后我們肯定至少能收入 24 億票房,咱們一起分。給發行方歡喜傳媒 6 個多億,然后我們再分剩下的 18 億,是個不錯的生意。
而現在,是今日頭條直接取代了橫店影視的位置,我給你 6 個多億,我不用電影院放,我自己上億裝機量的 App 上就可以看,大家拿手機免費看,我的 App 打開率高了,錢就掙回來了,說不定還能培養出大家用 App 看電影首映的習慣。
發行方歡喜傳媒,徐崢沒啥損失。電影院被今日頭條系給取代了,你說能不聲討嗎?
觀眾看完之后是什么反應
雖然《囧媽》賺足了流量,但口碑究竟如何呢?目前《囧媽》在豆瓣上的評分僅為 5.9 分,負面的評論居多。我們搜集整理了豆瓣上的評論數據,用 Python 進行分析。
整個數據分析的過程分為三步:
- 獲取數據
- 數據預處理
- 數據可視化
以下是具體的步驟和代碼實現:
獲取數據
豆瓣從 2017 年 10 月開始全面限制爬取數據,非登錄狀態下最多獲取 200 條,登錄狀態下最多為 500 條,本次我們共獲取數據 698 條。
為了解決登錄的問題,本次使用 Selenium+BeautifulSoup 獲取數據。
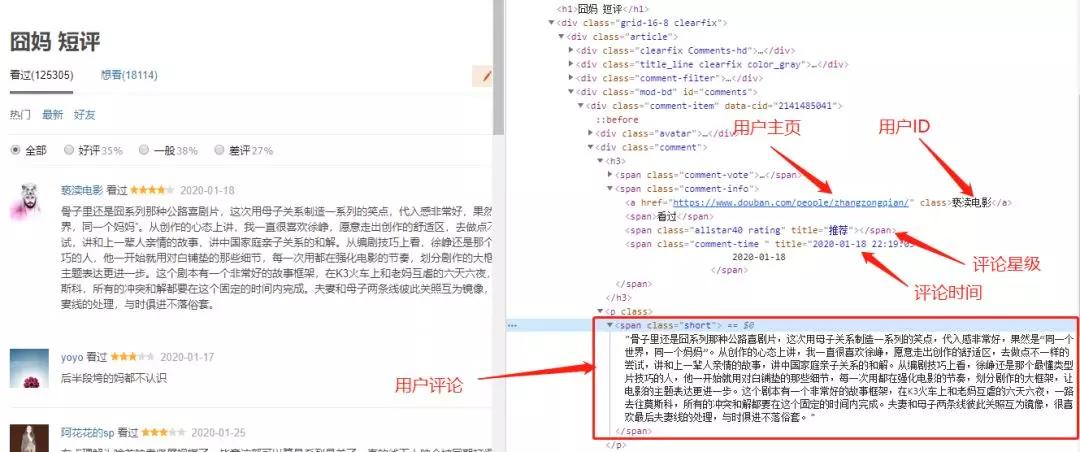
如下圖所示,本次數據爬取主要獲取的內容有:
- 評論用戶 ID
- 評論用戶主頁
- 評論內容
- 評分星級
- 評論日期
- 用戶所在城市
代碼實現:
- # 導入所需包
- import requests
- from bs4 import BeautifulSoup
- import numpy as np
- import pandas as pd
- import time
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- from selenium.webdriver.common.keys import Keys
- from selenium.webdriver.chrome.options import Options
- # 定義登錄函數
- def login_douban():
- '''功能:自動登錄豆瓣網站'''
- global browser # 設置為全局變量
- browser = webdriver.Chrome()
- # 進入登錄頁面
- login_url = 'https://accounts.douban.com/passport/login?source=movie'
- browser.get(login_url)
- # 點擊密碼登錄
- browser.find_element_by_class_name('account-tab-account').click()
- # 輸入賬號和密碼
- username = browser.find_element_by_id('username')
- username.send_keys('18511302788')
- password = browser.find_element_by_id('password')
- password.send_keys('12349148feng')
- # 點擊登錄
- browser.find_element_by_class_name('btn-account').click()
- # 定義函數獲取單頁數據
- def get_one_page(url):
- '''功能:傳入url,豆瓣電影一頁的短評信息'''
- # 進入短評頁
- browser.get(url)
- # 使用bs解析網頁數據
- bs = BeautifulSoup(browser.page_source, 'lxml')
- # 獲取用戶名
- username = [i.find('a').text for i in bs.findAll('span', class_='comment-info')]
- # 獲取用戶url
- user_url = [i.find('a')['href'] for i in bs.findAll('span', class_='comment-info')]
- # 獲取推薦星級
- rating = []
- for i in bs.findAll('span', class_='comment-info'):
- try:
- one_rating = i.find('span', class_='rating')['title']
- rating.append(one_rating)
- except:
- rating.append('力薦')
- # 評論時間
- time = [i.find('span', class_='comment-time')['title'] for i in bs.findAll('span', class_='comment-info')]
- # 短評信息
- short = [i.text for i in bs.findAll('span', class_='short')]
- # 投票次數
- votes = [i.text for i in bs.findAll('span', class_='votes')]
- # 創建一個空的DataFrame
- df_one = pd.DataFrame()
- # 存儲信息
- df_one['用戶名'] = username
- df_one['用戶主頁'] = user_url
- df_one['推薦星級'] = rating
- df_one['評論時間'] = time
- df_one['短評信息'] = short
- df_one['投票次數'] = votes
- return df_one
- # 定義函數獲取25頁數據(目前所能獲取的最大頁數)
- def get_25_page(movie_id):
- '''功能:傳入電影ID,獲取豆瓣電影25頁的短評信息'''
- # 創建空的DataFrame
- df_all = pd.DataFrame()
- # 循環追加
- for i in range(25):
- url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&sort=new_score&status=P".format(movie_id,i*20)
- print('我正在抓取第{}頁'.format(i+1), end='\r')
- # 調用函數
- df_one = get_one_page(url)
- df_all = df_all.append(df_one, ignore_index=True)
- # 程序休眠一秒
- time.sleep(1.5)
- return df_all
- if __name__ == '__main__':
- # 先運行登錄函數
- login_douban()
- # 程序休眠兩秒
- time.sleep(2)
- # 再運行循環翻頁函數
- movie_id = 30306570 # 囧媽
- df_all = get_25_page(movie_id)
爬取出來的數據以數據框的形式存儲,結果如下所示:
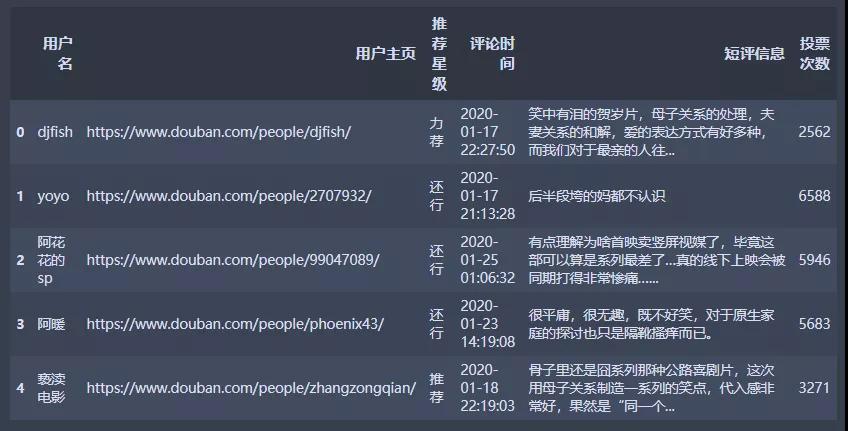
從用戶主頁的地址可以獲取到用戶的城市信息,這一步比較簡單,此處的代碼省略。
數據預處理
對于獲取到的數據,我們需要進行以下的處理以方便后續分析:
- 推薦星級:轉換為 1-5 分。
- 評論時間:轉換為時間類型,提取出日期信息。
- 城市:有城市空缺、海外城市、亂寫和 pyecharts 尚不支持的城市,需要進行處理。
- 短評信息:需要進行分詞和提取關鍵詞。
代碼實現:
- # 定義函數轉換推薦星級字段
- def transform_star(x):
- if x == '力薦':
- return 5
- elif x == '推薦':
- return 4
- elif x == '還行':
- return 3
- elif x == '較差':
- return 2
- else:
- return 1
- # 星級轉換
- df_all['星級'] = df_all.推薦星級.map(lambda x:transform_star(x))
- # 轉換日期類型
- df_all['評論時間'] = pd.to_datetime(df_all.評論時間)
- # 提取日期
- df_all['日期'] = df_all.評論時間.dt.date
- # 定義函數-獲取短評信息關鍵詞
- def get_comment_word(df):
- '''功能:傳入df,提取短評信息關鍵詞'''
- # 導入庫
- import jieba.analyse
- import os
- # 去停用詞
- stop_words = set()
- # 加載停用詞
- cwd = os.getcwd()
- stop_words_path = cwd + '\\stop_words.txt'
- with open(stop_words_path, 'r', encoding='utf-8') as sw:
- for line in sw.readlines():
- stop_words.add(line.strip())
- # 添加停用詞
- stop_words.add('6.3')
- stop_words.add('一張')
- stop_words.add('一部')
- stop_words.add('徐崢')
- stop_words.add('徐導')
- stop_words.add('電影')
- stop_words.add('電影票')
- # 合并評論信息
- df_comment_all = df['短評信息'].str.cat()
- # 使用TF-IDF算法提取關鍵詞
- word_num = jieba.analyse.extract_tags(df_comment_all, topK=100, withWeight=True, allowPOS=())
- # 做一步篩選
- word_num_selected = []
- # 篩選掉停用詞
- for i in word_num:
- if i[0] not in stop_words:
- word_num_selected.append(i)
- else:
- pass
- return word_num_selected
- key_words = get_comment_word(df_all)
- key_words = pd.DataFrame(key_words, columns=['words','num'])
數據可視化
用 Python 做可視化分析的工具很多,目前比較好用可以實現動態可視化的是 pyecharts。
我們主要對以下幾個方面信息進行可視化分析:
- 總體評分分布
- 評分時間走勢圖
- 評論用戶城市分布
- 評論詞云圖
①總體評分分布
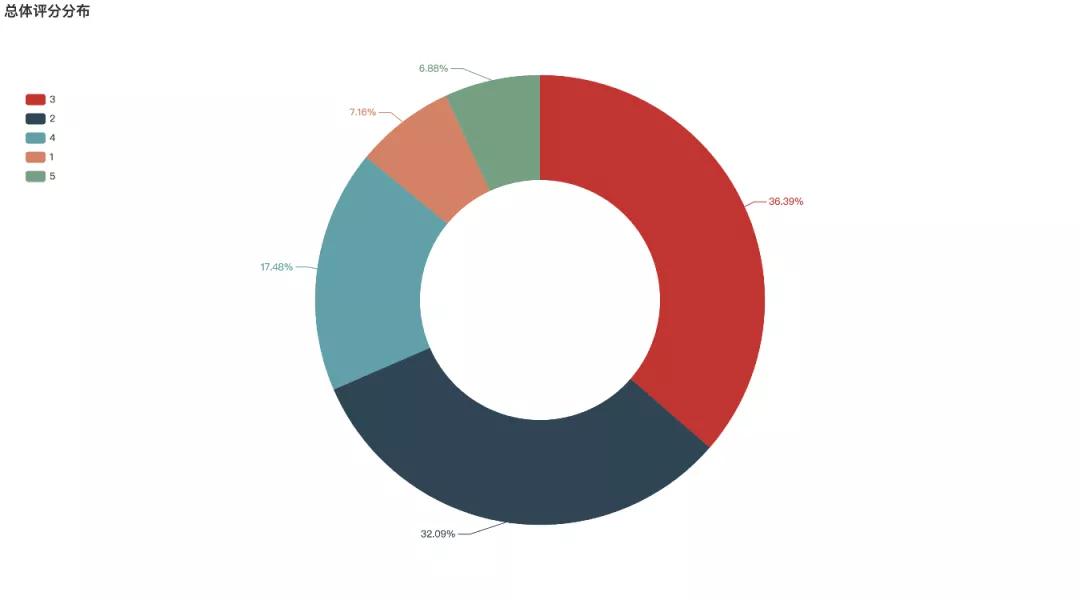
《囧媽》截止到目前在豆瓣中的總體評分為 5.9 分,僅好于 19% 的喜劇片。從評分分布來看,3 分的占比最高,有 36.39%,其次為 2 分,有 32.09%,5 分的比例最低,僅有 6.88%。
代碼實現:
- # 總體評分百分比
- score_perc = df_all.星級.value_counts() / df_all.星級.value_counts().sum()
- score_perc = np.round(score_perc*100,2)
- # 導入所需包
- from pyecharts import options as opts
- from pyecharts.charts import Pie, Page
- # 繪制柱形圖
- pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
- pie1.add("",
- [*zip(score_perc.index, score_perc.values)],
- radius=["40%","75%"])
- pie1.set_global_opts(title_opts=opts.TitleOpts(title='總體評分分布'),
- legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
- toolbox_opts=opts.ToolboxOpts())
- pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))
- pie1.render('總體評分分布.html')
②評分時間走勢圖
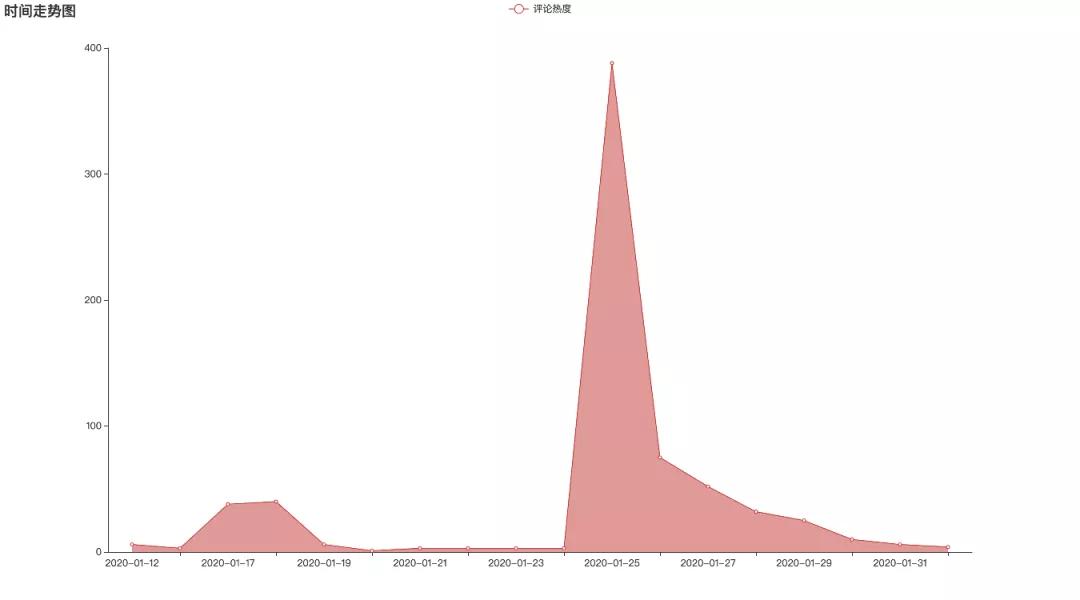
評論的時間走勢圖和電影熱度一致,在大年初一免費上映時候達到最高值。
代碼實現:
- # 時間排序
- time = df_all.日期.value_counts()
- time.sort_index(inplace=True)
- from pyecharts.charts import Line
- # 繪制時間走勢圖
- line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
- line1.add_xaxis(time.index.tolist())
- line1.add_yaxis('評論熱度', time.values.tolist(), areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False))
- line1.set_global_opts(title_opts=opts.TitleOpts(title="時間走勢圖"), toolbox_opts=opts.ToolboxOpts())
- line1.render('評論時間走勢圖.html')
③評論用戶城市分布
接下來分析了評論者所在的城市分布。
首先是用條形圖,來粗略的展示前十大熱門的影迷城市。
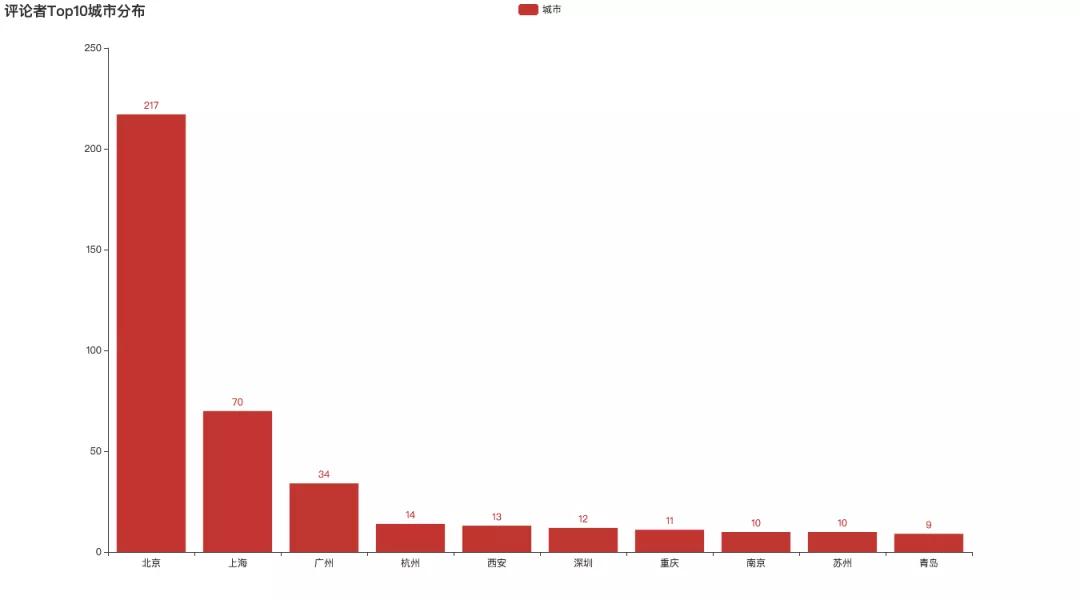
代碼實現:
- # 國內城市top10
- city_top10 = df_all.城市處理.value_counts()[:12]
- city_top10.drop('國外', inplace=True)
- city_top10.drop('未知', inplace=True)
- from pyecharts.charts import Bar
- # 條形圖
- bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
- bar1.add_xaxis(city_top10.index.tolist())
- bar1.add_yaxis("城市", city_top10.values.tolist())
- bar1.set_global_opts(title_opts=opts.TitleOpts(title="評論者Top10城市分布"),toolbox_opts=opts.ToolboxOpts())
- bar1.render('評論者Top10城市分布條形圖.html')
柱形圖的展示不是很直觀也不全面,在含有地理位置的數據中,我們常采用地圖的形式。
為大家更加直觀的進行展示,選取了觀影城市最多的前三十個城市作為動態展示,如下圖所示:
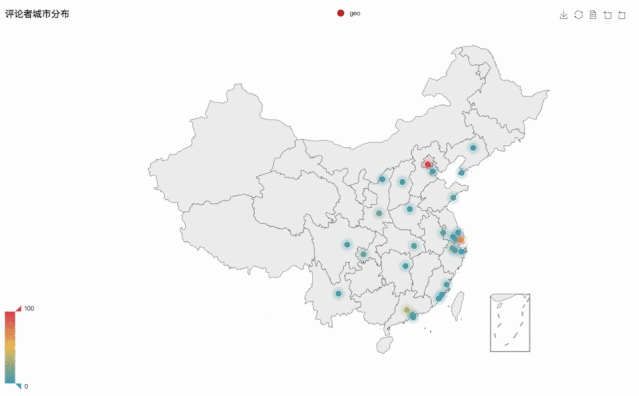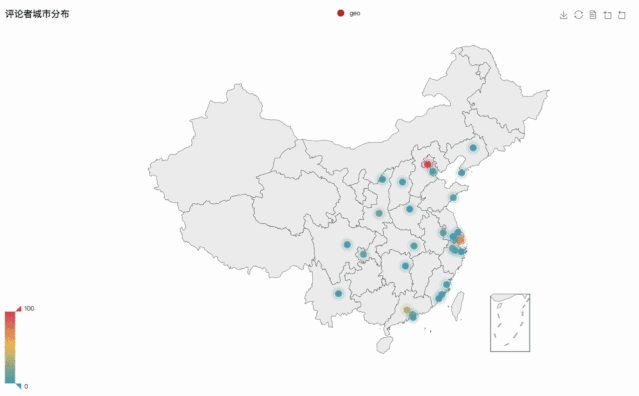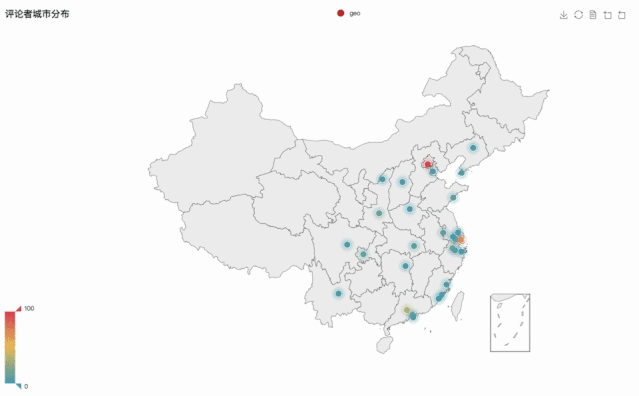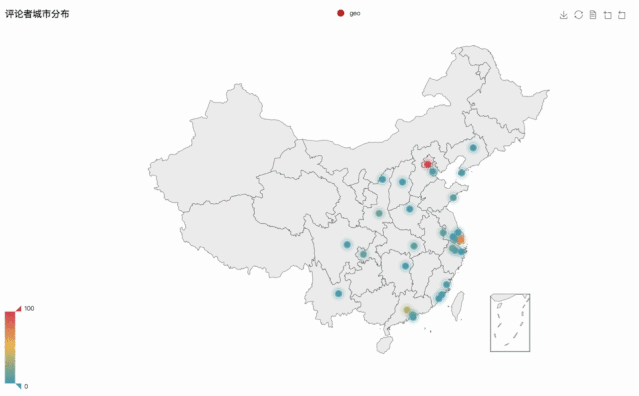
代碼實現:
- city_num = df_all.城市處理.value_counts()[:30]
- city_num.drop('國外', inplace=True)
- city_num.drop('未知', inplace=True)
- c1 = Geo(init_opts=opts.InitOpts(width='1350px', height='750px'))
- c1.add_schema(maptype='china')
- c1.add('geo', [list(z) for z in zip(city_num.index, city_num.values.astype('str'))], type_=ChartType.EFFECT_SCATTER)
- c1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
- c1.set_global_opts(visualmap_opts=opts.VisualMapOpts(),
- title_opts=opts.TitleOpts(title='評論者城市分布'),
- toolbox_opts=opts.ToolboxOpts())
- c1.render('評論者城市分布地圖.html')
④評論詞云圖

從詞云圖中可以看出,"喜劇" "和解" "母子" "笑點" "親情"等詞占較大的比重。
骨子里還是囧系列那種公路喜劇片,這次用母子關系制造一系列的笑點,讓電影的主題表達更進一步。
但也有很多觀眾反映電影強行煽情,強行上升高度,強行搞笑,強行接續劇情,強行中年婚姻危機。
代碼實現:
- from pyecharts.charts import WordCloud
- from pyecharts.globals import SymbolType, ThemeType
- word = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
- word.add("", [*zip(key_words.words, key_words.num)], word_size_range=[20, 200])
- word.set_global_opts(title_opts=opts.TitleOpts(title="囧媽電影評論詞云圖"),
- toolbox_opts=opts.ToolboxOpts())
- word.render('囧媽電影評論詞云圖.html')
在熱門評論里,用戶阿暖說道:“ 很平庸,很無趣,既不好笑,對于原生家庭的探討也只是隔靴搔癢而已。”

竟然獲得了 5560 個贊同。
同時我也查了一下:
- 2010 年《人在囧途》,豆瓣 7.7 分。主演是徐崢,導演葉偉民。
- 2012 年《人在囧途之泰囧》,豆瓣 7.4 分,徐崢自導自演。
- 2015 年《港囧》,豆瓣 5.7 分,徐崢自導自演。
- 2018 年《我不是藥神》,豆瓣 9.0 分,主演是徐崢,導演是文牧野。
- 2020 年《囧媽》,豆瓣 5.9 分,徐崢自導自演。
所以徐崢一定是個好演員,但導演嘛,就不好說了。
有人說這次徐崢這個玩法是要做中國版的 Netflix。Netflix 現在大家都知道是世界數一數二流媒體平臺,就是視頻網站,也能在電視上看。
所以從口碑上看,《囧媽》只能算在形式上開了個頭,就像當年徐崢是開啟了中國電影的大票房時代,但真正的票房王是吳京,讓我們期待一下吧。