如何找到好的主題模型量化評價指標?這是一份熱門方法總結
基于統計學的主題模型諸如 LDA(Latent Dirichlet Allocation),Biterm 的應用使得針對大量文本進行信息的總結提取成為可能。但是提取的主題到底質量如何,如何進行量化分析和評價,仍然沒有確定的標準。
同時,隨著神經網絡的發展,encoding-decoding, GAN 這種非監督模型開始進入到主題模型的應用中來,如何判斷這些模型產生的主題有效性就更顯得重要了。同時,這些神經網絡本身也可以作為評測的方法之一。
本文就主題模型的評價指標進行討論,對當下比較熱門的評價方法進行總結,并對未來這一領域可能的發展方向進行展望。
1. 主題模型
宏觀上講,主題模型就是用來在一系列文檔中發現抽象主題的一種統計模型,一般來說,這些主題是由一組詞表示了。如果一篇文章有一個中心思想,那么一些特定詞語會更頻繁的出現。比方說,如果一篇文章是在講狗的,那「狗」和「骨頭」等詞出現的頻率會高些。如果一篇文章是在講貓的,那「貓」和「魚」等詞出現的頻率會高些。而有些詞例如「這個」、「和」大概在兩篇文章中出現的頻率會大致相等。如果一篇文章 10% 和貓有關,90% 和狗有關,那么和狗相關的關鍵字出現的次數大概會是和貓相關的關鍵字出現次數的 9 倍。而一個主題模型則會用數學框架來體現文檔的這種特點。
如圖 1 所示,最左邊的就是各個主題(提前確定好的),然后在文中不同的顏色對應不同的主題,比如黃色可能對應狗,那么文中跟狗相關的詞都會標成黃色,這樣最后就能獲得一個各個主題可能的主題分布。
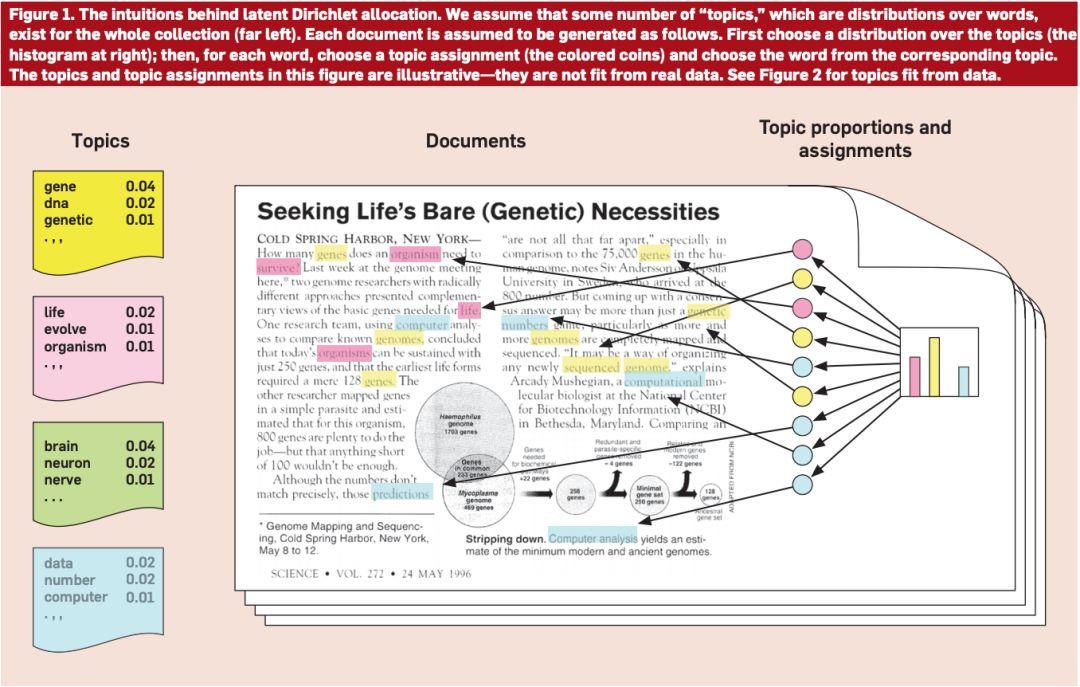
圖 1:主題模型(圖源:https://medium.com/@tengyuanchang/%E7%9B%B4%E8%A7%80%E7%90%86%E8%A7%A3-lda-latent-dirichlet-allocation-%E8%88%87%E6%96%87%E4%BB%B6%E4%B8%BB%E9%A1%8C%E6%A8%A1%E5%9E%8B-ab4f26c27184)
本文主要是介紹主題模型的量化評價指標,因此不對主題模型做過多解釋。如果對主題模型沒有什么基礎的,可以看一下機器之心發過的一篇比較適合入門的教程,有需要可以自取。同時,除了教程中提到的這些概率模型,一些深度學習模型(GAN, Encoding-Decoding 等)也開始進入這一領域,比如基于 GAN 的 ATM(Adversarial-neural Topic Model)就有不錯的表現。
觀察上文提到的那些主題模型,可以發現不管是概率模型 LDA,還是基于深度學習模型 ATM,都面臨一個問題,那就是這些模型該怎么去評價,這些模型提取出的主題真的有用嗎?換句話說,這些模型提取出的東西真的能表達一個主題嗎?舉個很簡單的例子,當主題模型提取出一個主題(很多詞)時,如果這么模型是好的,那么這些詞一定是能表達同一個主題的,如果不好的話那這些詞就是貌合神離。一般來說,主題越多,我們得到的結果就越有分辨性,但是對應的,當主題變多時,結果毫無意義的情況就更加普遍,有些主題只有幾個詞,而且根本詞不對題。除此之外,經過一些專家的實驗,發現貌合神離的情況主要有以下四種:
a. 通過詞對聯系傳遞后才聯系在一起的主題。比如說,「糖」,「甘蔗」和「糖醋排骨」,糖產生自甘蔗(主題可以是「甜食」),糖醋排骨中加了糖(主題可以是「料理」),糖醋排骨跟甘蔗卻很難組成一個主題。但是在關系傳遞中(通過「糖」聯系在一起),這三個詞被放到了同一個主題中。
b. 異常詞。由于算法錯誤或其他什么原因導致完全不相干的詞出現在這個主題中。
c. 關系不明。詞之間沒有很明確的聯系。
d. 不平衡。詞之間的聯系都很明確,但是詞的意義都很寬泛,比如「學科」和「作業」,很難確定一個很明確的主題。
本文剩下的部分首先對兩類評價模型進行介紹,然后分析了這些評價模型的效果,最后對評價模型的發展進行了展望。
2 利用模型中的知識評價主題模型
目前評價的方法大部分都利用了一些參數或者是詞之間的聯系來確定模型的優劣,很少有直接利用模型中獲得的東西來衡量主題模型的。Xing [4] 最近提出了幾種基于 Gibbs Sampling 過程中估算出的分布進行評價的方式。
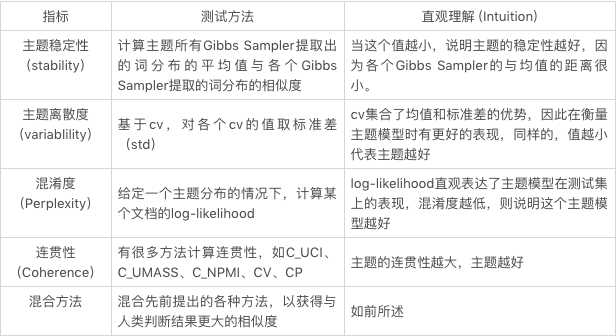
2.1 主題穩定性
在 LDA 的 Gibbs Sampling 的過程中會產生(估算)兩個分布——一個是給定文檔時主題的分布,另一個是給定主題時詞的分布 (Φ),而主題穩定性主要考慮的就是第二個分布。
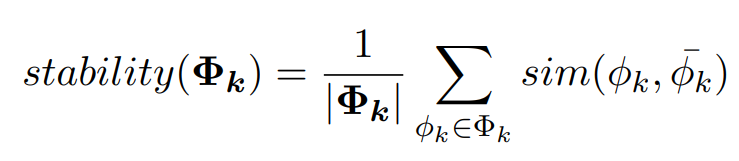
如公式所示,對于一個給定的主題 k,要計算其所有 Gibbs Sampler 提取出的詞分布的平均值與各個 Gibbs Sampler 提取的詞分布的相似度 (原論文 [4] 中使用了 cosine similarity, Euclidean distance, KL-divergence 以及 Jaccard similarity 來計算這個相似度),取和后就得到了這個主題的主題穩定度。
通過公式可以很清晰的看出,相較于前面的計算方式,主題穩定性并不需要參數和多余的語料庫。然而,有些常用詞的詞頻很高,因此出現在主題中時主題的穩定度會很高,但是它們跟主題卻并不相關,這也就導致一些很差的主題有很高的主題穩定度。
2.2 主題離散度
在前一節中提到過,Gibbs Sampling 產生了兩個分布,主題穩定性使用了第二個分布,也就是通過詞的角度來判斷主題的優劣。而本節的離散度使用的則是第一個分布,也就是說我們的目光轉向了文檔這一層次。通常來說,這個的參數是通過對多個 Gibbs Sampler 的結果取平均而得到的。同時,從這些 Gibbs Sampler 的結果中,我們還可以得到他們的標準方差(standard deviation)。但是標準方差太過敏感,于是為了能夠獲得一個更穩定的結果,我們還可以用平均值除以偏差,以得到變異系數(coefficient of variance,cv)。按常理說,均值和變異系數都可以用來辨別一個主題的好壞,好主題的均值和 cv 應該相對較小,反之則應該較大。在 NYT 語料庫的測試中,這三個評判標準的效果如下圖所示。
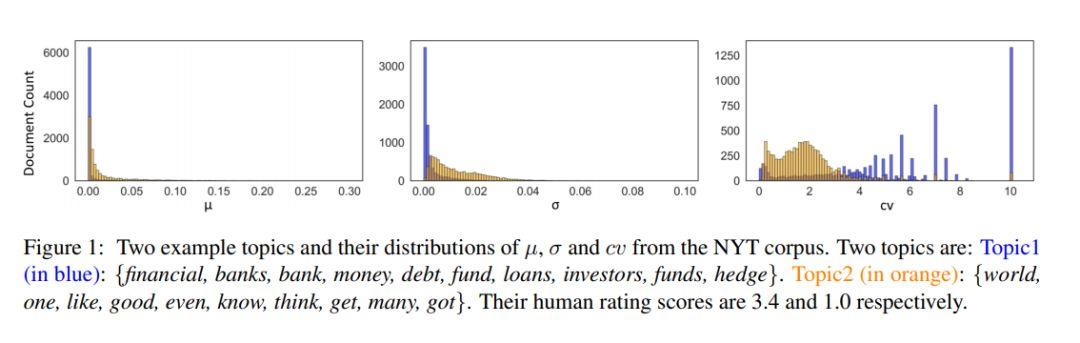
圖 2:通過的得到的三種評測結果(圖源:https://arxiv.org/abs/1909.03524)
圖 2 中,藍色代表好主題(3.4 分),橘色代表差主題(1 分),可以看到只有 cv 對于兩個主題的區分度最大,而平均值(mu)和標準方差(sigma)中,藍色和橘色的區分度并不大,也就是說很難分辨出好主題和差主題。
因此,cv 是表征主題離散度最好的方式,所以某個主題 k 的主題離散度的計算公式可以表達為:

D 表示第 D 篇文章,k 則表示主題 k。
3. 模擬人工評測結果
在第一節中提到了主題模型常出現的各種誤差,基于這些誤差,很多人提出了不同的方法,這些方法(包括本文后面提到的)都是為了解決上述一個或多個問題。目前傳統的方法大都是使用了目測或是先驗知識,常見的方法有很多。最直觀的方法就是讓人來判斷提取出的主題好還是不好,但是很明顯,這個方法需要大量的人力物力和時間。因此,人們開始探索如何用公式或是算法來模擬、估計人為判斷的結果。人為判斷的方法主要分為直接方法和間接方法(后文詳述),因此那些模擬人為判斷的算法也就大致可以被分為這兩類。當然這些方法的分類很多,但在本節中介紹的主要是模擬人工測評結果的那一部分,所以分類就按照直接方法和間接方法來分。
有些方法被稱為直接方法,這些方法主要基于語言的內部特性進行判斷,比如說 Newman et al. (2010) 提出的主題連貫性(Topic Coherence)就利用 PMI(Pairwise Pointwise Mutual Information)對主題詞間的連貫性進行計算,后面其他人也對這種連貫性的計算方式進行了改進,但是本質上還是在計算連貫性(會在后文詳述);還有一些方法被稱為間接方法,這些方法不是直接通過語言內部特性進行判斷的,而是采用一些其它的方式,比如在下游任務中的表現,或是在測試集中的表現(混淆度,perplexity)。就包括。本節剩下的部分就會對這些方法進行詳述。
3.1 混淆度 (perplexity)
簡單來說,混淆度就是利用概率計算某個主題模型在測試集上的表現,混淆度越低,則說明這個主題模型越好。具體來說,就是在給定一個主題分布的情況下,計算某個文檔的 log-likelihood。在下面這個式子里,Phi 代表給定的主題矩陣,α參數確定主題的分布,w 則指代我們要預測的文章(d,與訓練得到和α的文章的主題相同)。
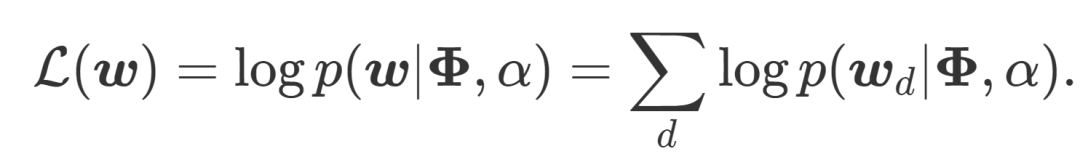
得到了 log-likelihood 后,perplexity 就很好計算了,公式如下(這里的分母一般來說就是文章的單詞數):
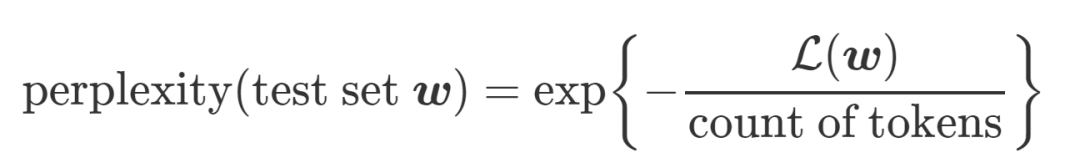
根據定義可以看出,log-likelihood(log-可能性)越高,也就意味著提取出的主題能表達特定主題的能力越好,這個提取出的主題質量也就越高,混淆度也就越小。但是這里的 log-likelihood 是沒辦法求的,Wallach09a (http://dirichlet.net/pdf/wallach09evaluation.pdf)中提出了一些對 likelihood 進行估計的方法,感興趣的可以自己看一下,因為其效果并不很好(下面會介紹原因),故而這里對其計算方法就不做詳述了。
但是為了測試這個方法的有效性,有人在 Amazon Mechanical Turk 平臺上進行了一個大規模實驗。他們在每個話題中找到了基于 perplexity 確定的最有可能的 5 組詞,然后隨機加入了第六組詞,讓參與者找出這組隨機加入的詞。
如果每個參與者都能識別出異常詞,那么我們可以認為這個提取出的主題是優秀的,可以描述出一個特定的主題。然而,如果許多人把正常的 5 組詞中的一組認成異常詞,這就意味著他們看不出這些詞之間的聯系有什么邏輯,我們也就可以認為這個主題不夠好——因為它描述的主題并不明確。這個實驗證明了混淆度的結果與人為判斷的結果不太相關。
3.2 主題連貫性(Coherence)
由于混淆度在很多場景的應用效果不佳,本部分將著重介紹最后一個方法,也就是主題連貫性。主題連貫性主要是用來衡量一個主題內的詞是否是連貫的。那么這些詞怎么就算是是連貫的呢?如果這些詞是相互支撐的,那么這組詞就是連貫的。換句話說,如果把好多個主題的詞放在一起,用完美的聚類器做聚類,那么同一個主題的詞應該在同一個類別中。根據定義可以發現,第一節中提到的四個問題中的前三個,都可以通過主題連貫性解決。
Newman et al. (2010) 提出使用 PMI 計算主題連貫性后,Mimno et al. (2011) 基于主題連貫性的理念,又使用了一種基于條件概率的方式對連貫性進行計算,Musat et al. (2011) 也在同年提出利用 WordNet 的層級概念來獲取主題間的聯系;然后,Aletras and Stevenson (2013a) 也提出了一種基于分布相似度的方法來求連貫性。目前來說,比較常見的幾種方法(Roder et al. (2015) 中整理的,在 Gensim 中有打包好的函數,可以直接調用)如下所示(假設有一個主題,包含 {game, sport, ball, team}):
PMI:為了了解其他幾種方式的計算方法,首先要先看一下 PMI 的計算方法(如下圖所示)。在后面的兩個方法中,這里epsilon 的越小,將會得到越小的結果。這個公式可能看起來有些費解,不過沒關系,可以先放一下,在后面看到例子之后,這個公式就很好理解了。
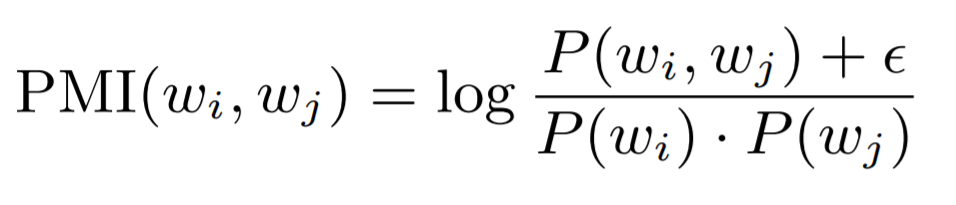
C_uci:本方法由 University of California Irvine(UCI)的 David Newman 提出,故而稱其為 UCI 方法。本方法的基本原理是基于滑動窗口,對給定主題詞中的所有單詞對(one-set 分割)的點態互信息 (point twise mutual information, PMI) 進行計算。





C_v (Coefficient of variance):本方法基于滑動窗口,對主題詞進行 one-set 分割(一個 set 內的任意兩個詞組成詞對進行對比),并使用歸一化點態互信息 (NPMI) 和余弦相似度來間接獲得連貫度。
C_p:本方法也是基于滑動窗口,但分詞方法為 one-preceding(每個詞只與位于其前面和后面的詞組成詞對),并利用 Fitelson 相關度來表征連貫度。
3.3 模擬人工判別結果
3.3.1 間接方法
如前文所述,人工判別方法也被分為兩類,一類是直接方法,一類是間接方法。人工判別的間接方法被稱為異常詞檢測,主要就是在主題模型提取出的各個主題中加入一個異常詞,然后讓人來找出這個異常詞。
為了模擬這種間接人工判別的結果,Jey Han Lau(2014)從那些發給人工做判別的主題詞中提取了詞之間的聯系特征,提取的方法為以下三種:
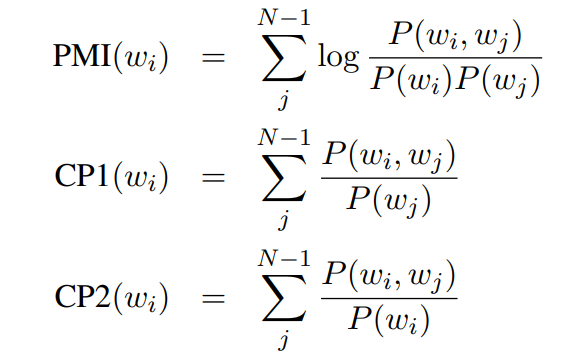
然后將這些特征進行合并,利用 Ranking SVM Regression 來找到異常詞。同時,Jey 還利用了 NPMI 進行詞之間的聯系特征進行提取。最終的結果如下圖所示:
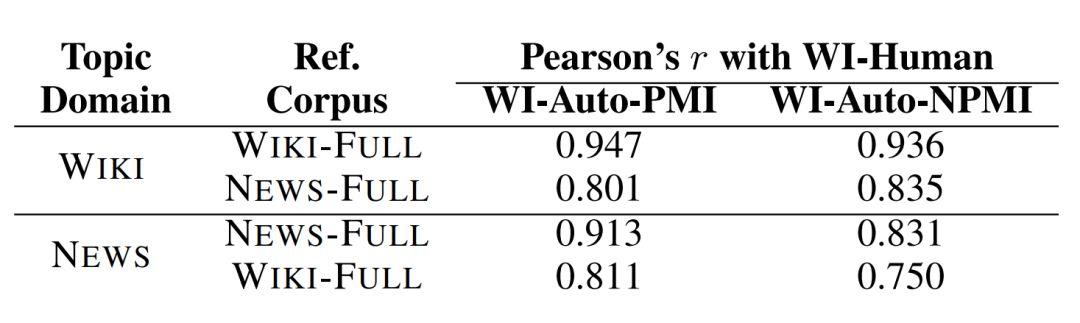
相關度比較結果(圖源:https://www.aclweb.org/anthology/E14-1056.pdf)
圖中顯示的是 Jey 的方法(WI-Auto-PMI, WI-Auto-NPMI)與人工判別(WI-Human)的關聯度,可以看到這些方法與人工判別得到的結果還是比較一致的。
3.3.2 直接方法
另外一種人工方法叫直接方法,這種方法就比較簡單粗暴,就是讓人直接對各個主題進行評分。對于這種直接方法,Jey 使用了以下 4 中方法對主題進行評分:
OC(Observed Coherence)-Auto-PMI:對一個主題內的詞計算 PMI,計算方法其實就是 PMI,如下圖所示:



相關度比較結果(圖源:https://www.aclweb.org/anthology/E14-1056.pdf)
由上圖可知,這些方法與人工判別的結果在大部分結果上還是很一致的,只有部分結果(PMI 等)沒能得到很好的一致性。
4. 展望與總結
本文主要介紹了主題模型存在的一些問題和當前比較流行的主題模型評價方法,也對主流的主題模型評價方法進行了簡單的分類。
對于未來,我主要有兩點想法,一是要適應時代的發展,也就是當前越來越多的數據集和越來越多的小數據集的學習模型,如何更好的利用這些數據集,或者如何找到合適的小數據集的處理方式都是很不錯的嘗試方向,甚至直接使用監督模型來對主題模型進行評價都可以;第二個就是要時刻記得本質問題,這也是為什么我要在文章的第一節就提出主題模型常見錯誤的原因,評價方法的本質還是為了找到這些錯誤,站在這些專家的肩膀上,我們可以把這些常見錯誤分而治之,利用不同的模型解決不同的錯誤,或是如何找到這些錯誤的共同特點,從而完成一個更加通用的建模,這些都是這個領域可以探索的方向。當然這個領域的未來發展方向還有很多,我在這里也只是拋磚引玉。
希望大家喜歡這種探索的過程!