火爆的圖機(jī)器學(xué)習(xí),2020年將有哪些研究趨勢?
本文轉(zhuǎn)自雷鋒網(wǎng),如需轉(zhuǎn)載請(qǐng)至雷鋒網(wǎng)官網(wǎng)申請(qǐng)授權(quán)。
2019年絕對(duì)是圖機(jī)器學(xué)習(xí)(GML)大火的一年,凡是學(xué)術(shù)會(huì)議,圖神經(jīng)網(wǎng)絡(luò)的會(huì)場總會(huì)爆滿。
圖機(jī)器學(xué)習(xí)的研究之所以在2019年突然變得火熱,原因在于,在前幾年盡管深度學(xué)習(xí)在歐氏空間中的數(shù)據(jù)方面取得了巨大的成功,但在許多實(shí)際的應(yīng)用場景中的數(shù)據(jù)往往是從非歐式空間生成的。
正如阿里達(dá)摩院曾在2019年所提:“單純的深度學(xué)習(xí)已經(jīng)成熟,而結(jié)合了深度學(xué)習(xí)的圖研究將端到端學(xué)習(xí)與歸納推理相結(jié)合,有望解決深度學(xué)習(xí)無法處理的關(guān)系推理、可解釋性等一系列問題。”
在過去的一年里,圖機(jī)器學(xué)習(xí)經(jīng)過了蓬勃的發(fā)展,這從各大頂會(huì)中圖機(jī)器學(xué)習(xí)的火爆場面也可以看出。
而新的一年已經(jīng)過去了一個(gè)月,那么2020年圖機(jī)器學(xué)習(xí)的火熱還能持續(xù)嗎?又將有哪些新的研究趨勢呢? 即將于4月份在埃塞俄比亞舉辦的ICLR 2020是一個(gè)能夠很好反映這些問題的會(huì)議。
這個(gè)會(huì)議是由深度學(xué)習(xí)三巨頭之二的 Yoshua Bengio 和 Yann LeCun 牽頭創(chuàng)辦,旨在關(guān)注有關(guān)深度學(xué)習(xí)各個(gè)方面的前沿研究。
在ICLR 2020中共有150篇投稿與圖機(jī)器學(xué)習(xí)有關(guān),而其中有近1/3的論文都被錄用了,這也說明圖機(jī)器學(xué)習(xí)火熱依舊。
我們不妨將這些論文按照理論、應(yīng)用、知識(shí)圖譜、圖嵌入來劃分,從而一窺圖機(jī)器學(xué)習(xí)在2020年的研究趨勢。
注:文中涉及論文,可關(guān)注雷鋒網(wǎng)「AI科技評(píng)論」微信公眾號(hào),并后臺(tái)回復(fù)「2020年GML趨勢」下載。
1、GNN理論知識(shí)會(huì)更加扎實(shí)
從目前的形式看,圖機(jī)器學(xué)習(xí)的領(lǐng)域在成熟的康莊大道上越走越遠(yuǎn),但是圖神經(jīng)網(wǎng)絡(luò)還有很多進(jìn)步空間。過去的一年圖神經(jīng)網(wǎng)絡(luò)不斷改進(jìn),因此誕生了許多理論研究,在我們對(duì)2020年預(yù)測之前,先來簡單梳理一下圖神經(jīng)網(wǎng)絡(luò)的重要理論成果吧!
What graph neural networks cannot learn: depth vs width
https://openreview.net/forum?id=B1l2bp4YwS
洛桑聯(lián)邦理工學(xué)院 Andreas Loukas 的這篇論文,無論在影響力、簡潔性還是對(duì)理論理解的深度上,無疑是論文中的典范。
它表明,當(dāng)我們用GNN計(jì)算通常的圖問題時(shí),節(jié)點(diǎn)嵌入的維數(shù)(網(wǎng)絡(luò)的寬度,w)乘以層數(shù)(網(wǎng)絡(luò)的深度,d)應(yīng)該與圖n的大小成正比,即dW=O(n)。
但現(xiàn)實(shí)是當(dāng)前的GNN的許多實(shí)現(xiàn)都無法達(dá)到此條件,因?yàn)閷訑?shù)和嵌入的尺寸與圖的大小相比還不夠大。另一方面,較大的網(wǎng)絡(luò)在實(shí)際操作中不合適的,這會(huì)引發(fā)有關(guān)如何設(shè)計(jì)有效的GNN的問題,當(dāng)然這個(gè)問題也是研究人員未來工作的重點(diǎn)。需要說明的是,這篇論文還從80年代的分布式計(jì)算模型中汲取了靈感,證明了GNN本質(zhì)上是在做同樣的事情。
這篇文章還包含有大量有價(jià)值的結(jié)論,強(qiáng)烈建議去閱讀原文。可關(guān)注雷鋒網(wǎng)(公眾號(hào):雷鋒網(wǎng))「AI科技評(píng)論」微信公眾號(hào),后臺(tái)回復(fù)「2020年GML趨勢」下載論文。
同樣,在另外兩篇論文中,Oono等人研究了GNN的能力。第一篇文章是《圖神經(jīng)網(wǎng)絡(luò)在節(jié)點(diǎn)分類中失去了表達(dá)能力》,第二篇文章是《圖神經(jīng)網(wǎng)絡(luò)的邏輯表達(dá)》。
Graph Neural Networks Exponentially Lose Expressive Power for Node Classification
https://openreview.net/forum?id=S1ldO2EFPr
這篇論文表明:“在已知某些條件下的權(quán)重,當(dāng)層數(shù)增加時(shí),GCN除了節(jié)點(diǎn)度和連通分量以外,將無法學(xué)習(xí)其他任何內(nèi)容。”這一結(jié)果擴(kuò)展了“馬爾可夫過程收斂到唯一平衡點(diǎn)”的性質(zhì),并表明其中收斂速度由轉(zhuǎn)移矩陣的特征值決定。
The Logical Expressiveness of Graph Neural Networks
https://openreview.net/pdf?id=r1lZ7AEKvB
這篇論文展示了GNN與節(jié)點(diǎn)分類器類型之間的聯(lián)系。在這之前,我們已經(jīng)了解GNN與WL同構(gòu)檢驗(yàn)一樣強(qiáng)大。但是GNN可以獲得其他分類功能么?直觀上不行,因?yàn)镚NN是一種消息傳遞機(jī)制,如果圖的一個(gè)部分和另一個(gè)部分之間沒有鏈接,那么兩者之間就不會(huì)傳遞消息。
因此論文提出一個(gè)簡單解決方案:在鄰域聚合之后添加一個(gè)讀出操作,以便每個(gè)節(jié)點(diǎn)在更新所有要素時(shí)與圖中所有其他節(jié)點(diǎn)都有聯(lián)系。
其他在理論上的工作還有很多,包括Hou等人測量GNN的圖形信息的使用。以及 Srinivasan 和 Ribeiro提出的基于角色的節(jié)點(diǎn)嵌入和基于距離的節(jié)點(diǎn)嵌入的等價(jià)性討論。
論文鏈接如下:
Measuring and Improving the Use of Graph Information in Graph Neural Networks
https://openreview.net/forum?id=rkeIIkHKvS
On the Equivalence between Positional Node Embeddings and Structural Graph Representationshttps://openreview.net/forum?id=SJxzFySKwH
2、新酷應(yīng)用不斷涌現(xiàn)
在過去的一年中,GNN已經(jīng)在一些實(shí)際任務(wù)中進(jìn)行了應(yīng)用。例如已經(jīng)有一些程序應(yīng)用于玩游戲、回答智商測試、優(yōu)化TensorFlow計(jì)算圖形、分子生成以及對(duì)話系統(tǒng)中的問題生成。
HOPPITY: LEARNING GRAPH TRANSFORMATIONS TO DETECT AND FIX BUGS IN PROGRAMS
https://openreview.net/pdf?id=SJeqs6EFvB
在論文中,作者其提出了一種在Javascript代碼中同時(shí)檢測和修復(fù)錯(cuò)誤的方法。具體操作是將代碼轉(zhuǎn)換為抽象語法樹,然后讓GNN進(jìn)行預(yù)處理以便獲得代碼嵌入,再通過多輪圖形編輯運(yùn)算符(添加或刪除節(jié)點(diǎn),替換節(jié)點(diǎn)值或類型)對(duì)其進(jìn)行修改。為了理解圖形的哪些節(jié)點(diǎn)應(yīng)該修改,論文作者使用了一個(gè)指針網(wǎng)絡(luò)(Pointer network),該網(wǎng)絡(luò)采用了圖形嵌入來選擇節(jié)點(diǎn),以便使用LSTM網(wǎng)絡(luò)進(jìn)行修復(fù)。當(dāng)然,LSTM網(wǎng)絡(luò)也接受圖形嵌入和上下文編輯。
LambdaNet: Probabilistic Type Inference using Graph Neural Networks
https://openreview.net/pdf?id=Hkx6hANtwH
類似的應(yīng)用還體現(xiàn)在上面這篇論文中。來自得克薩斯大學(xué)奧斯汀分校的作者研究了如何推斷像Python或TypeScript此類語言的變量類型。更為具體的,作者給出了一個(gè)類型依賴超圖(type dependency hypergraph),包含了程序作為節(jié)點(diǎn)的變量以及它們之間的關(guān)系,如邏輯關(guān)系、上下文約束等;然后訓(xùn)練一個(gè)GNN模型來為圖和可能的類型變量產(chǎn)生嵌入,并結(jié)合似然率進(jìn)行預(yù)測。
Abstract Diagrammatic Reasoning with Multiplex Graph Networks
https://openreview.net/pdf?id=ByxQB1BKwH
在智商測試類的應(yīng)用中,上面這篇論文展示了GNN如何進(jìn)行IQ類測試,例如瑞文測驗(yàn)(RPM)和圖三段論(DS)。具體的在RPM任務(wù)中,矩陣的每一行組成一個(gè)圖形,通過前饋模型為其獲取邊緣嵌入,然后進(jìn)行圖形匯總。由于最后一行有8個(gè)可能的答案,因此將創(chuàng)建8個(gè)不同的圖,并將每個(gè)圖與前兩行連接起來,以通過ResNet模型預(yù)測IQ得分。如下圖所示:
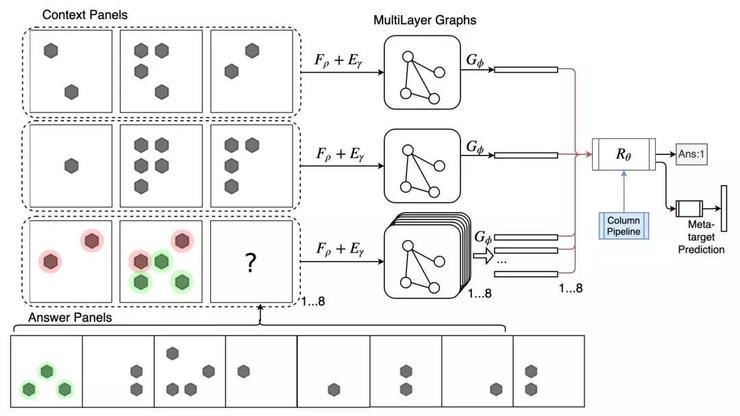
來自:https://openreview.net/pdf?id=ByxQB1BKwH
Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs
https://openreview.net/pdf?id=rkxDoJBYPBDeepMind
在上面的論文中提出了一種RL算法來優(yōu)化TensorFlow計(jì)算圖的開銷。先通過標(biāo)準(zhǔn)GNN對(duì)圖形進(jìn)行處理,然后產(chǎn)生與圖中每個(gè)節(jié)點(diǎn)的調(diào)度優(yōu)先級(jí)相對(duì)應(yīng)的離散化嵌入,最后將嵌入被饋送到遺傳算法BRKGA中進(jìn)行模型訓(xùn)練,從而優(yōu)化得到的TensorFlow圖的實(shí)際計(jì)算開銷。值得注意的是該遺傳算法決定每個(gè)節(jié)點(diǎn)的布局和調(diào)度。
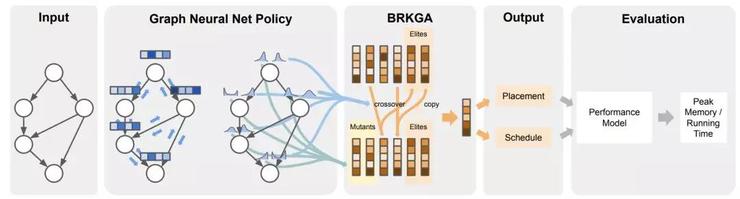
類似的炫酷應(yīng)用還有Chence Shi的分子結(jié)構(gòu)生成和Jiechuan Jiang玩游戲以及Yu Chen的玩游戲等等。
論文鏈接如下:Graph Convolutional Reinforcement Learning
https://openreview.net/forum?id=HkxdQkSYDB
Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation
https://openreview.net/forum?id=HygnDhEtvr
3、知識(shí)圖譜將更加流行
在今年的ICLR會(huì)議上,有很多關(guān)于知識(shí)圖譜推理的論文。
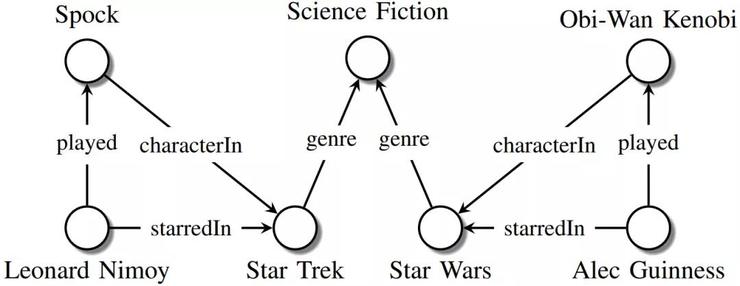
知識(shí)圖譜例子(來源:https://arxiv.org/abs/1503.00759)
從本質(zhì)上講,知識(shí)圖譜是一種結(jié)構(gòu)化的表示事實(shí)的方式。與一般的圖不同,知識(shí)圖譜的節(jié)點(diǎn)和邊實(shí)際上具有一定的含義,例如演員的名字、電影名等。知識(shí)圖譜中一個(gè)常見的問題是,如何回答一些復(fù)雜問題,例如“斯皮爾伯格哪些電影在2000年之前贏得了奧斯卡獎(jiǎng)?”,這個(gè)問題翻譯成邏輯查詢語言則是:
∨ {Win(Oscar, V) ∧ Directed(Spielberg, V) ∧ProducedBefore(2000, V) } Query2box:
Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings
https://openreview.net/forum?id=BJgr4kSFDS

Query2Box 推理框架 在斯坦福大學(xué)Hongyu Ren等人的工作中,他們建議將query嵌入到隱空間當(dāng)中,而不是作為單個(gè)的點(diǎn)(作為矩形框)。
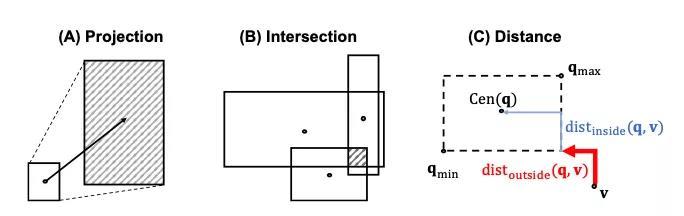
QUERY2BOX的兩種操作及距離函數(shù)的幾何示例 這種方法使得可以自然地執(zhí)行 交 操作(即合取 ∧),得到一個(gè)新的矩形框。但是對(duì)于 并 操作(即析取 ∨)卻并不那么簡單,因?yàn)樗赡軙?huì)產(chǎn)生非重疊區(qū)域。
此外,要使用嵌入來對(duì)所有query進(jìn)行精確建模,嵌入之間的距離函數(shù)(通過VC維度進(jìn)行度量)的復(fù)雜性會(huì)與圖譜中實(shí)體的數(shù)量成正比。
不過有一個(gè)不錯(cuò)的技巧可以將析取( ∨)query轉(zhuǎn)換為DNF形式,這時(shí)候只有在圖計(jì)算的最后才會(huì)進(jìn)行 并 操作,這能夠有效減少每個(gè)子查詢的距離計(jì)算。
Differentiable Learning of Numerical Rules in Knowledge Graphs
https://openreview.net/forum?id=rJleKgrKwSCMU的Po-Wei
Wang等人在類似主題的一篇文章提出了一種處理數(shù)字實(shí)體和規(guī)則的方法。
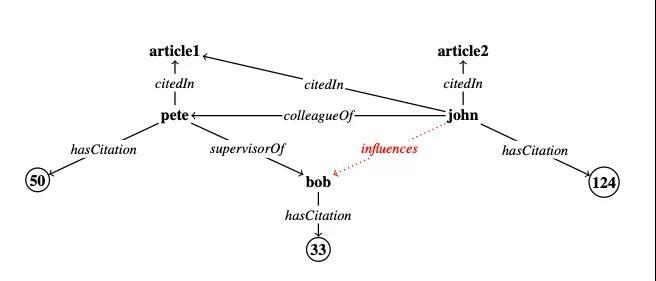
引用知識(shí)圖譜(Citation KG)示例 舉例來說,以引用知識(shí)圖譜(Citation KG),可以有一條規(guī)則: influences(Y,X) ← colleagueOf(Z,Y) ∧ supervisorOf(Z,X)∧ hasCitation>(Y,Z) 這是一個(gè)典型的情況,即學(xué)生X受到其導(dǎo)師Z的同事Y(Y有較高的引用率)的影響。
這個(gè)規(guī)則右邊的每個(gè)關(guān)系都可以表示為一個(gè)矩陣,而尋找缺失連接(missing links)的過程可以表示為關(guān)系與實(shí)體向量的連續(xù)矩陣乘積,這個(gè)過程稱為規(guī)則學(xué)習(xí)。由于矩陣的構(gòu)造方式,神經(jīng)網(wǎng)絡(luò)的方法只能在分類規(guī)則colleagueOf(Z,Y)下工作。
作者的貢獻(xiàn)在于,他們通過一種新穎的方法證明了,在實(shí)際中并不需要顯式地表示這些矩陣,從而有效地處理了類似hasCitation>(Y,Z)、求反運(yùn)算這樣的數(shù)字規(guī)則,這大大降低了運(yùn)行時(shí)間。
You CAN Teach an Old Dog New Tricks!
On Training Knowledge Graph Embeddingshttps://openreview.net/forum?id=BkxSmlBFvr
在今年的圖神經(jīng)網(wǎng)絡(luò)(或者說機(jī)器學(xué)習(xí))中經(jīng)常出現(xiàn)的一個(gè)研究方向是:對(duì)現(xiàn)有模型的重新評(píng)估,以及在一個(gè)公平環(huán)境中進(jìn)行測評(píng)。

上面這篇文章即是其中一個(gè),他們的研究表明,新模型的性能往往取決于試驗(yàn)訓(xùn)練中的“次要”細(xì)節(jié),例如損失函數(shù)的形式、正則器、采樣的方案等。
在他們進(jìn)行的大型消融研究中,作者觀察到將舊的方法(例如RESCAL模型)的超參數(shù)進(jìn)行適當(dāng)調(diào)整就可以獲得SOTA性能。 當(dāng)然在這個(gè)領(lǐng)域還有許多其他有趣的工作,Allen et al. 基于對(duì)詞嵌入的最新研究,進(jìn)一步探究了關(guān)系與實(shí)體的學(xué)習(xí)表示的隱空間。Asai et al. 則展示了模型如何在回答給定query的Wikipedia圖譜上檢索推理路徑。
Tabacof 和 Costabello 討論了圖嵌入模型的概率標(biāo)定中的一個(gè)重要問題,他們指出,目前流行的嵌入模型TransE 和ComplEx(通過將logit函數(shù)轉(zhuǎn)換成sigmoid函數(shù)來獲得概率)均存在誤校,即對(duì)事實(shí)的存在預(yù)測不足或預(yù)測過度。
論文鏈接如下:On Understanding Knowledge Graph Representation
https://openreview.net/forum?id=SygcSlHFvS
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
https://openreview.net/forum?id=SJgVHkrYDH
Probability Calibration for Knowledge Graph Embedding Models
https://openreview.net/forum?id=S1g8K1BFwS
4、圖嵌入的新框架
圖嵌入是圖機(jī)器學(xué)習(xí)的一個(gè)長期的研究主題,今年有一些關(guān)于我們應(yīng)該如何學(xué)習(xí)圖表示的新觀點(diǎn)出現(xiàn)。
GraphZoom: A Multi-level Spectral Approach for Accurate and Scalable Graph Embedding
https://openreview.net/forum?id=r1lGO0EKDH
康奈爾的Chenhui Deng等人提出了一種改善運(yùn)行時(shí)間和準(zhǔn)確率的方法,可以應(yīng)用到任何無監(jiān)督嵌入方法的節(jié)點(diǎn)分類問題。 這篇文章的總體思路是,首先將原始圖簡化為更小的圖,這樣可以快速計(jì)算節(jié)點(diǎn)嵌入,然后再回復(fù)原始圖的嵌入。
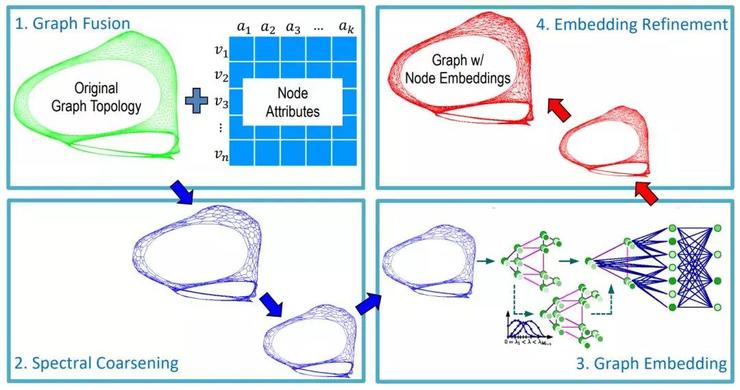
最初,根據(jù)屬性相似度,對(duì)原始圖進(jìn)行額外的邊擴(kuò)充,這些便對(duì)應(yīng)于節(jié)點(diǎn)的k近鄰之間的鏈接。 隨后對(duì)圖進(jìn)行粗化:通過局部譜方法將每個(gè)節(jié)點(diǎn)投影到低維空間中,并聚合成簇。任何無監(jiān)督的圖嵌入方法(例如DeepWalk、Deep Graph Infomax)都可以在小圖上獲得節(jié)點(diǎn)嵌入。 在最后一步,得到的節(jié)點(diǎn)嵌入(本質(zhì)上表示簇的嵌入)用平滑操作符迭代地進(jìn)行廣播,從而防止不同節(jié)點(diǎn)具有相同的嵌入。 在實(shí)驗(yàn)中,GraphZoom框架相比node2vec和DeepWalk,實(shí)現(xiàn)了驚人的 40 倍的加速,準(zhǔn)確率也提高了 10%。
A Fair Comparison of Graph Neural Networks for Graph Classification
https://openreview.net/forum?id=HygDF6NFPB
已有多篇論文對(duì)圖分類問題的研究成果進(jìn)行了詳細(xì)的分析。比薩大學(xué)的Federico Errica 等人在圖分類問題上,對(duì)GNN模型進(jìn)行了重新評(píng)估。
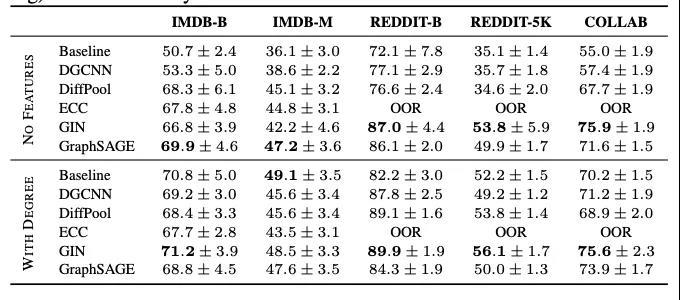
他們的研究表明,一個(gè)不利用圖的拓?fù)浣Y(jié)構(gòu)(僅適用聚合節(jié)點(diǎn)特征)的簡單基線能獲得與SOTA GNN差不多的性能。事實(shí)上,這個(gè)讓人驚訝的發(fā)現(xiàn),Orlova等人在2015年就已經(jīng)發(fā)表了,但沒有引起大家的廣泛關(guān)注。
Understanding Isomorphism Bias in Graph Data Sets
https://openreview.net/forum?id=rJlUhhVYvSSkolkovo
科學(xué)技術(shù)研究院的Ivanov Sergey等人在研究中發(fā)現(xiàn),在MUTAG和IMDB等常用數(shù)據(jù)集中,即使考慮節(jié)點(diǎn)屬性,很多圖也都會(huì)具有同構(gòu)副本。而且,在這些同構(gòu)圖中,很多都有不同的target標(biāo)簽,這自然會(huì)給分類器引入標(biāo)簽噪聲。這表明,利用網(wǎng)絡(luò)中所有可用的元信息(如節(jié)點(diǎn)或邊屬性)來提高模型性能是非常重要的。
Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification
https://openreview.net/forum?id=BJxQxeBYwH
另外還有一項(xiàng)工作是UCLA孫怡舟團(tuán)隊(duì)的工作。這項(xiàng)工作顯示如果用一個(gè)線性近鄰聚合函數(shù)取代原有的非線性近鄰聚合函數(shù),模型的性能并不會(huì)下降。這與之前大家普遍認(rèn)為“圖數(shù)據(jù)集對(duì)分類的影響并不大”的觀點(diǎn)是相反的。同時(shí)這項(xiàng)工作也引發(fā)一個(gè)問題,即如何為此類任務(wù)找到一個(gè)合適的驗(yàn)證框架。