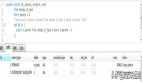
一次SQL查詢優化原理分析(900W+數據,從17s到300ms)
有一張財務流水表,未分庫分表,目前的數據量為9555695,分頁查詢使用到了limit,優化之前的查詢耗時16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms),按照下文的方式調整SQL后,耗時347 ms (execution: 163 ms, fetching: 184 ms);
- 操作: 查詢條件放到子查詢中,子查詢只查主鍵ID,然后使用子查詢中確定的主鍵關聯查詢其他的屬性字段;
- 原理: 減少回表操作;
- -- 優化前SQL
- SELECT 各種字段
- FROM `table_name`
- WHERE 各種條件
- LIMIT 0,10;
- -- 優化后SQL
- SELECT 各種字段
- FROM `table_name` main_tale
- RIGHT JOIN
- (
- SELECT 子查詢只查主鍵
- FROM `table_name`
- WHERE 各種條件
- LIMIT 0,10;
- ) temp_table ON temp_table.主鍵 = main_table.主鍵
一,前言
首先說明一下MySQL的版本:
- mysql> select version();
- +-----------+
- | version() |
- +-----------+
- | 5.7.17 |
- +-----------+
- 1 row in set (0.00 sec)
表結構:
- mysql> desc test;
- +--------+---------------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +--------+---------------------+------+-----+---------+----------------+
- | id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
- | val | int(10) unsigned | NO | MUL | 0 | |
- | source | int(10) unsigned | NO | | 0 | |
- +--------+---------------------+------+-----+---------+----------------+
- 3 rows in set (0.00 sec)
id為自增主鍵,val為非唯一索引。
灌入大量數據,共500萬:
- mysql> select count(*) from test;
- +----------+
- | count(*) |
- +----------+
- | 5242882 |
- +----------+
- 1 row in set (4.25 sec)
我們知道,當limit offset rows中的offset很大時,會出現效率問題:
- mysql> select * from test where val=4 limit 300000,5;
- +---------+-----+--------+
- | id | val | source |
- +---------+-----+--------+
- | 3327622 | 4 | 4 |
- | 3327632 | 4 | 4 |
- | 3327642 | 4 | 4 |
- | 3327652 | 4 | 4 |
- | 3327662 | 4 | 4 |
- +---------+-----+--------+
- 5 rows in set (15.98 sec)
為了達到相同的目的,我們一般會改寫成如下語句:
- mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
- +---------+-----+--------+---------+
- | id | val | source | id |
- +---------+-----+--------+---------+
- | 3327622 | 4 | 4 | 3327622 |
- | 3327632 | 4 | 4 | 3327632 |
- | 3327642 | 4 | 4 | 3327642 |
- | 3327652 | 4 | 4 | 3327652 |
- | 3327662 | 4 | 4 | 3327662 |
- +---------+-----+--------+---------+
- 5 rows in set (0.38 sec)
時間相差很明顯。
為什么會出現上面的結果?我們看一下select * from test where val=4 limit 300000,5;的查詢過程:
查詢到索引葉子節點數據。
根據葉子節點上的主鍵值去聚簇索引上查詢需要的全部字段值。
類似于下面這張圖:
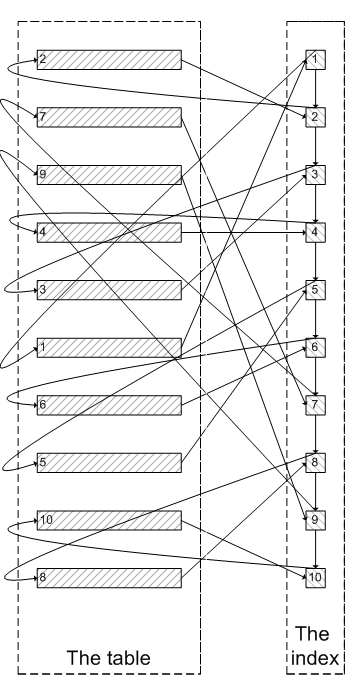
像上面這樣,需要查詢300005次索引節點,查詢300005次聚簇索引的數據,最后再將結果過濾掉前300000條,取出最后5條。MySQL耗費了大量隨機I/O在查詢聚簇索引的數據上,而有300000次隨機I/O查詢到的數據是不會出現在結果集當中的。肯定會有人問:既然一開始是利用索引的,為什么不先沿著索引葉子節點查詢到最后需要的5個節點,然后再去聚簇索引中查詢實際數據。這樣只需要5次隨機I/O,類似于下面圖片的過程
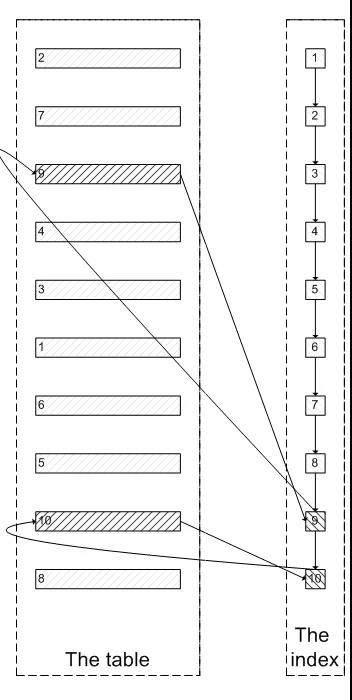
其實我也想問這個問題。
證實
下面我們實際操作一下來證實上述的推論:為了證實select * from test where val=4 limit 300000,5是掃描300005個索引節點和300005個聚簇索引上的數據節點,我們需要知道MySQL有沒有辦法統計在一個sql中通過索引節點查詢數據節點的次數。我先試了Handler_read_*系列,很遺憾沒有一個變量能滿足條件。我只能通過間接的方式來證實:InnoDB中有buffer pool。里面存有最近訪問過的數據頁,包括數據頁和索引頁。所以我們需要運行兩個sql,來比較buffer pool中的數據頁的數量。預測結果是運行select * from test a inner join (select id from test where val=4 limit 300000,5); 之后,buffer pool中的數據頁的數量遠遠少于select * from test where val=4 limit 300000,5;對應的數量,因為前一個sql只訪問5次數據頁,而后一個sql訪問300005次數據頁。select * from test where val=4 limit 300000,5
- mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.04 sec)
可以看出,目前buffer pool中沒有關于test表的數據頁。
- mysql> select * from test where val=4 limit 300000,5;
- +---------+-----+--------+
- | id | val | source |
- +---------+-----+--------+|
- 3327622 | 4 | 4 |
- | 3327632 | 4 | 4 |
- | 3327642 | 4 | 4 |
- | 3327652 | 4 | 4 |
- | 3327662 | 4 | 4 |
- +---------+-----+--------+
- 5 rows in set (26.19 sec)
- mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
- +------------+----------+
- | index_name | count(*) |
- +------------+----------+
- | PRIMARY | 4098 |
- | val | 208 |
- +------------+----------+2 rows in set (0.04 sec)
可以看出,此時buffer pool中關于test表有4098個數據頁,208個索引頁。select * from test a inner join (select id from test where val=4 limit 300000,5) ;為了防止上次試驗的影響,我們需要清空buffer pool,重啟mysql。
- mysqladmin shutdown
- /usr/local/bin/mysqld_safe &
- mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
- Empty set (0.03 sec)
運行sql:
- mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
- +---------+-----+--------+---------+
- | id | val | source | id |
- +---------+-----+--------+---------+
- | 3327622 | 4 | 4 | 3327622 |
- | 3327632 | 4 | 4 | 3327632 |
- | 3327642 | 4 | 4 | 3327642 |
- | 3327652 | 4 | 4 | 3327652 |
- | 3327662 | 4 | 4 | 3327662 |
- +---------+-----+--------+---------+
- 5 rows in set (0.09 sec)
- mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
- +------------+----------+
- | index_name | count(*) |
- +------------+----------+
- | PRIMARY | 5 |
- | val | 390 |
- +------------+----------+
- 2 rows in set (0.03 sec)
我們可以明顯的看出兩者的差別:第一個sql加載了4098個數據頁到buffer pool,而第二個sql只加載了5個數據頁到buffer pool。符合我們的預測。也證實了為什么第一個sql會慢:讀取大量的無用數據行(300000),最后卻拋棄掉。
而且這會造成一個問題:加載了很多熱點不是很高的數據頁到buffer pool,會造成buffer pool的污染,占用buffer pool的空間。遇到的問題為了在每次重啟時確保清空buffer pool,我們需要關閉innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,這兩個選項能夠控制數據庫關閉時dump出buffer pool中的數據和在數據庫開啟時載入在磁盤上備份buffer pool的數據。