













清華團隊再獲突破!研制出全球首款多陣列憶阻器存算一體系統
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
基于多個憶阻器陣列的存算一體系統,在處理卷積神經網絡時的能效比圖形處理器芯片高兩個數量級。
有很多童鞋可能不知道憶阻器是什么?在開始今天的話題之前,雷鋒網編輯先為大家普及下憶阻器是什么。
所謂憶阻器,全稱記憶電阻器(Memristor),是繼電阻、電容、電感之后的第四種電路基本元件,表示磁通與電荷之間的關系,這種組件的的電阻會隨著通過的電流量而改變,而且就算電流停止了,它的電阻仍然會停留在之前的值,直到接受到反向的電流它才會被推回去,等于說能“記住”之前的電流量。
簡言之,憶阻器(memristor)可以在斷電之后,仍能“記憶”通過的電荷,其所具備的這種特性與神經突觸之間的相似性,使其具備獲得自主學習功能的潛力。因此,基于憶阻器的神經形態計算系統能為神經網絡訓練提供快速節能的方法,但是,圖像識別模型之一 的卷積神經網絡還沒有利用憶阻器交叉陣列的完全硬件實現。
不過,最近雷鋒網了解到,清華大學微電子所、未來芯片技術高精尖創新中心錢鶴、吳華強教授團隊與合作者在《自然》在線發表了題為“ Fully hardware-implemented memristor convolutional neural network ”的研究論文,報道了基于憶阻器陣列芯片卷積網絡的完整硬件實現。
他們提出用高能效比、高性能的均勻憶阻器交叉陣列實現 CNN,該實現共集成了 8個 PE ,每個 PE 包含2048 個單元的憶阻器陣列,以提升并行計算效率。此外,研究者還提出了一種高效的混合訓練方法,以適應設備缺陷,改進整個系統的性能。研究者構建了基于憶阻器的五層 CNN 來執行 MNIST 圖像識別任務,識別準確率超過 96%。
除了使用不同卷積核對共享輸入執行并行卷積外,憶阻器陣列還復制了多個相同卷積核,以并行處理不同的輸入。相較于當前最優的圖形處理器(GPU),基于憶阻器的 CNN 神經形態系統的能效要高出一個數量級,且實驗證明該系統可擴展至大型網絡,如殘差神經網絡。該結果或可促進針對深度神經網絡和邊緣計算提供基于憶阻器的非馮諾伊曼(non-von Neumann)硬件解決方案,在處理卷積神經網絡(CNN)時的能效比圖形處理器芯片(GPU)高兩個數量級,大幅提升了計算設備的算力,成功實現了以更小的功耗和更低的硬件成本完成復雜的計算。
1. 首個完全基于憶阻器的 CNN
硬件實現
據介紹,當前國際上的憶阻器研究還停留在簡單網絡結構的驗證,或者基于少量器件數據進行的仿真。基于憶阻器陣列的完整硬件實現仍然有很多挑戰。
比如,器件方面,需要制備高一致、可靠的陣列;系統方面,憶阻器因工作原理而存在固有缺陷(如器件間波動、器件電導卡滯、電導狀態漂移等),會導致計算準確率降低;架構方面,憶阻器陣列實現卷積功能需要以串行滑動的方式連續采樣、計算多個輸入塊,無法匹配全連接結構的計算效率。
在這些研究成果的基礎之上,錢鶴、吳華強團隊逐漸優化材料和器件結構,制備出了高性能的憶阻器陣列。
在器件方面,該研究成功實現了一個完整的五層 mCNN,用于執行 MNIST 手寫數字圖像識別任務。優化后的材料堆棧(material stack)能夠在 2048 個單晶體管單憶阻器(one-transistor–one-memristor,1T1R)陣列中實現可靠且均勻的模擬開關行為。使用該研究提出的混合訓練機制后,實驗在整個測試集上的識別準確率達到了 96.19%。
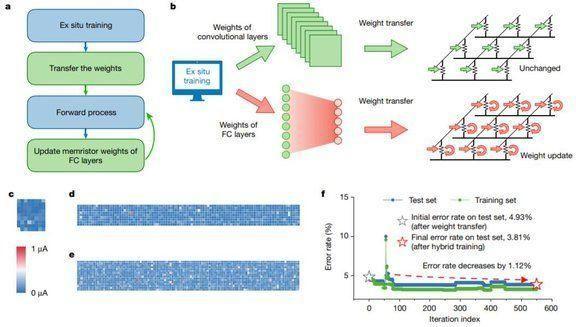
利用混合訓練方法得到 mCNN
此外,該研究在三個并行憶阻器卷積器中復制了卷積核,從而將 mCNN 的延遲降低約 2/3。該研究得到的高度集成神經形態系統彌補了基于憶阻器的卷積運算和全連接 VMM 之間的吞吐量差距,從而為大幅提升 CNN 效率提供了可行的解決方案。
架構方面,之前基于憶阻器的 demo 依賴于單一陣列,其主要原因是生成高度可重復的陣列面臨巨大挑戰。憶阻器設備的易變性和不完美特性被認為是神經形態計算應用的主要瓶頸。該研究提出了一種基于憶阻器的靈活計算架構,適用于神經網絡。
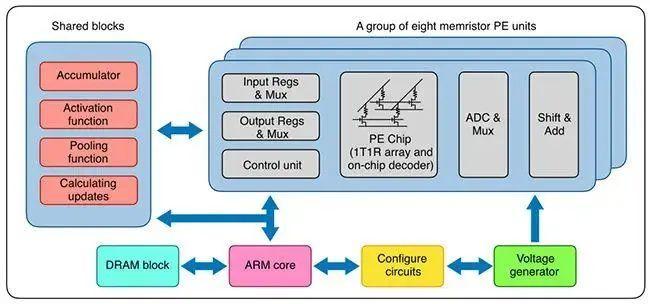
存算一體系統架構
憶阻器單元使用 TiN/TaO_x/HfO_x/TiN 的材料堆疊,通過調節電場和熱,在增強(SET)和抑制(RESET)這兩種情況下均展現出連續電導率調節能力。材料和制造流程與傳統的 CMOS 流程兼容,從而使憶阻器陣列可以方便地內置在晶圓的后段制程中,以減少流程變動,實現高復現性。得到的交叉陣列在同等的編程條件下具備均勻的模擬開關行為。因此,多憶阻器陣列硬件系統基于自定義印刷電路板(PCB)和 FPGA 評估板(ZC706, Xilinx)構建。
系統方面,該系統主要包含八個基于憶阻器的處理元件(PE)。每個 PE 集成了 2048 個單元的憶阻器陣列。每個憶阻器與晶體管的漏級端相連,即 1T1R 配置。核心 PCB 子系統具備八個憶阻器陣列芯片,每個憶阻器陣列具備 128 × 16 個 1T1R 單元。在水平方向上共有 128 條并行字線和 128 條源線,在垂直方向上共有 16 條位線。
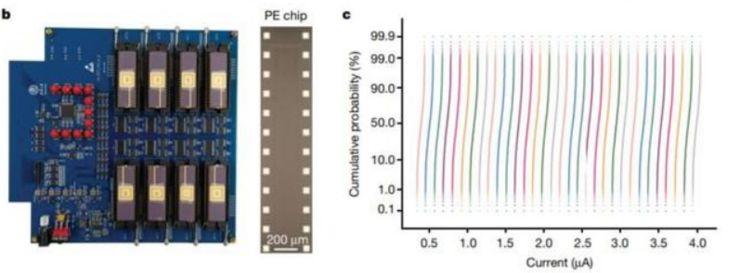
基于憶阻器的硬件系統具備可靠的多級電導率狀態
該陣列展示了極具可重復性的多級電導率狀態,成功證明了存算一體架構全硬件實現的可行性。
2. 有何優勢?
眾所周知,CNN 是最重要的深度神經網絡之一,在圖像處理相關任務中發揮關鍵作用,如圖像識別、圖像分割和目標檢測。
CNN 的典型計算步驟需要大量滑動卷積操作。從這個方面來看,CNN 需要支持并行乘積累加運算(MAC)的計算單元。而這需要重新設計傳統的計算系統,以便以更高的性能、更低的能耗來運行 CNN,這些計算系統包括通用應用平臺(如 GPU)、應用特定的加速器等。
但是,計算效率的進一步提升最終受限于系統的馮諾伊曼架構,該架構中的內存和處理單元是物理分離的,從而導致大量能耗,以及不同單元之間數據搬運的高延遲。
與之相反,基于憶阻器的神經形態計算可以提供非馮諾伊曼計算范式,即存儲數據,從而消除數據遷移的消耗。憶阻器陣列直接使用歐姆定律進行加法運算,使用基爾霍夫定律(Kirchhoffs law)進行乘法運算,因而能夠實現并行存內(in-memory)MAC 運算,從而模擬存內計算(in-memory computing),并實現速度和能效的大幅提升,減小誤差。





















