













開發API時需要關注的十三項指標
譯文【51CTO.com快譯】在軟件產品開發的生命周期中,不同的團隊需要關注不同的API指標。無論是API產品經理、還是開發工程師,他們在進行API分析研究與報告時,都會自然而然地從自身的職能特點去考察各種關鍵性的API指標。下面讓我們從團隊角色出發,一起討論那些需要關注的十三項API性能指標。

首先我們來看看一個典型的軟件企業團隊都有哪些不同的職能角色。
基礎架構與開發運營
通過正確地分配有限的資源,確保服務器能夠正常地運轉,以供多個工程團隊使用。
應用工程與平臺
API開發人員負責根據業務邏輯,向API添加新的功能,并解決應用程序中的問題。他們交付的產品包括:API即服務(API as a Service),與合作伙伴的插件和集成,以及其他豐富的API。
產品管理
API產品經理負責通過API功能的路線圖,確保構建出正確的API節點;并通過工程的時間和人員條件的約束,來平衡(內部或外部)用戶的需求。
業務與增長
這是一個由市場營銷和銷售人員組成的,面向市場的團隊。他們并不會專注API節點,而是會緊跟客戶的興趣點,以確保他們能夠使用到已開發出的API,并從中發現新的銷售機會。
基礎架構API指標
此類指標主要是應用性能監視(Application Performance Monitoring,APM)工具(如:Datadog之類的基礎架構監視公司的產品)所獲取。它們主要關注如下方面:
1、正常運行時間(uptime)
正常運行時間是衡量服務可用性的一項最基本的指標,我們有時也稱為“黃金標準”。許多企業都會在服務水平協議(SLA)中提及,或重點標注出各種與服務相關的“正常運行時間”標準。如下圖所示,我們在某些術語表中常見的“三個九”或“四個九”等,就是用來衡量某個服務系統每年的正常運行時間、與宕機時間之間的關系。
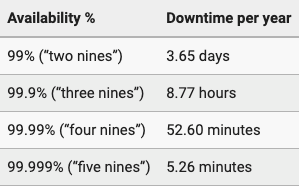
當然,從“四個九”提升到“五個九”,遠比從“兩個九”變成“三個九”要困難得多,這就是為什么除了關鍵性的(也是最昂貴的)服務之外,您在SLA中鮮少看到“五個九”的原因。話雖如此,我們仍然可以在減少某些服務的正常運行時間的同時,確保其在中斷的極端情況下,不會影響到既定的服務處理。例如:Moesif(一個美國人工智能API服務平臺)就被設計為即使其網站和儀表板出現完全中斷的情況,也能夠繼續通過各種SDK收集數據。也就是說,SDK能夠在本地排隊收集的信息,而不會中斷現有的應用。
正常運行時間通常是通過諸如Pingdom或 UptimeRobot的ping服務或綜合測試來衡量的。您可以將探測的頻率配置為每分鐘之類的固定時間間隔,來探測特定節點的/health或/status,以獲取諸如:數據備份等其他服務的基本連通性狀態。您可以通過Statuspage.io之類的工具,將這些收集到的指標發布到目標網站上。例如:Moesif就使用了基于Lambda構建的開源狀態頁面(請參見:https://github.com/ks888/LambStatus)。
當然,我們還可以設置并使用一些被稱為“綜合測試”的復雜ping服務。例如:運行特定的一套測試序列,并判定響應負載中是否包含一定的數值。盡管綜合測試可能無法代表用戶真實的流量,但是這些調試性的API對于獲悉系統的正常運行狀態還是非常有意義的。值得說明的是:綜合監控是由監控服務觸發的一組預定義的API調用,能夠檢查目標API序列是否符合預期運行狀態。
2、CPU使用率
CPU使用率也是非常經典的性能指標之一,它可以從某種程度上反應應用程序的響應能力。如果服務器CPU使用率較高,則可能意味著服務器或虛擬機已經過載,而且可能會帶來諸如:大量自旋鎖(spinlock)等應用程序的性能錯誤。
基礎架構工程師可以使用CPU使用率(包括內存使用百分比),來規劃資源,并衡量整體運行狀況。某些類型的應用程序(例如高帶寬的代理服務和API網關)本身就會比其他進程具有更高的CPU使用率,特別是在涉及到諸如視頻編碼、以及機器學習等大量浮點運算的工作負載時。
在本地調試API時,您可以通過Windows上的“任務管理器”(https://en.wikipedia.org/wiki/Task_Manager_(Windows) )或MacBook上的“Activity Monitor”,來輕松地查看系統和進程的CPU使用情況。但是在服務器上,如果您不想使用SSH或運行top命令,那么就需要用到各種APM工具了。通過APM提供的代理,您可以將其嵌入應用程序或服務器中,以捕獲諸如CPU和內存使用率之類的指標。當然,您也可以通過執行其他特定功能的應用程序監控,例如:線程分析。
我們在查看CPU使用率時,應當主要關注的是每個虛擬CPU(即物理線程)的使用率。如果出現不平衡的情況,則可能意味著應用程序沒有正確地執行進程,或者是線程池的大小配置不正確。
許多APM都能夠讓您使用不同的名稱來標記應用程序,以方便實現匯總。例如:您可能希望對諸如:my-api-westus-vm0、my-api-westus-vm1、my-api-eastus-vm0等每一個VM指標進行分組,同時將它們匯總到一個名為my-API的標簽之中。
3、內存使用
與CPU使用率類似,內存使用率也是衡量資源利用率的性能指標。較高的內存使用量可能表明服務器處于過載的狀態,因此它往往與配置有關。
通常情況下,大數據查詢、大流量處理、以及各種生產環境的數據庫,都會消耗比CPU更多的內存。因此,為了減少每個VM在批處理查詢時所花費的時間,我們應當分配更多的可用內存,以減少檢查點(checkpointing),網絡同步,以及對磁盤的分頁。
我們在查看內存的使用情況時,還應該查看頁面的錯誤數、以及I/O的操作數。常見的配置錯誤是:只為應用程序分配了一小部分的可用物理內存。這樣就很可能會導致高頁面的虛擬內存崩潰。
應用程序的API指標
4、每分鐘請求數(RPM)
每分鐘請求數(Requests per Minute,RPM)是我們在比較HTTP、或數據庫服務器時經常使用的性能指標。由于服務器無法準確地計算出諸如:第三方服務在對數據庫進行I/O操作時所引起的延遲,因此某些產品雖然會吹噓自己擁有較高的RPM,但是您的團隊仍然需要以效率為目標設法降低RPM。
通常情況下,您需要將具有多個API調用的某些業務功能,合并為更少的API調用,以減少RPM的數量。例如:您可以在單個請求中,批量處理多個請求,以確保自己具有靈活、實用的分頁方案。
與RPM相關的術語包括:每秒請求數(Requests per Second,RPS)和每秒查詢數(Queries per Second,QPS)。由于軟件產品的RPM可能會在每周、甚至是一天中的每一小時都有所不同,因此您需要靈活地調整自己的API,以適應具體的峰谷值。
5、平均與最大延遲
在跟蹤客戶的體驗時,API的延遲時間是一項非常重要的指標。雖然前文提到的CPU使用率之類的基礎架構級指標的增加,可能并不會讓用戶及時感知到響應能力的下降,但是API的延遲肯定會。有時候,單獨地跟蹤延遲可能無法使您完全理解它為什么會增加。因此,我們需要通過跟蹤API的各種變更,包括:新API版本的發布,新節點加入原有架構等方面,來找出導致延遲增加的根本原因。
由于宏觀地檢查總體延遲,可能會忽略真正有問題的慢速節點,因此我們需要按照路由、地理位置、以及細分字段來進行排查。例如:某個POST/checkout節點隨著時間的推移而延遲加劇,這很有可能是由于某個未被正確索引的SQL表在不斷增加所導致。但是,由于針對POST/checkout的調用數量非常少,因此該問題很容易被您的GET/items節點所掩蓋,畢竟該節點的調用量遠遠超過了checkout節點。同理,如果您有用到GraphQL API,那么就需要查看每個GraphQL操作的平均延遲。
盡管許多開發與架構人員也會關注延遲問題,但是他們主要是通過檢查一組VM的總體延遲,來確保VM不會過載,而不會深入地研究諸如每條路由等,針對應用程序的特定指標。因此,我們認為應用程序與工程人員更需要關注延遲的相關問題。
6、每分鐘錯誤率
與RPM相似,“每分鐘錯誤”(或簡稱錯誤率)是指每分鐘產生的帶有非200系列代碼的API調用數量。通過衡量API的錯誤率、以及易錯性,我們可以進一步了解正在發生的錯誤類型。例如:500系列錯誤意味著您的代碼存在著問題,而400系列錯誤則意味著不當的API設計和文檔。可見,我們在設計API時,使用適當的HTTP狀態代碼是非常重要的,具體請參見:https://www.restapitutorial.com/httpstatuscodes.html。
API產品指標
值得注意的是,我們在此所討論的API,不僅僅是指與微服務和SOA相關的應用接口,也包括那些獨立的產品。此類產品正在變得越來越普遍,尤其在與新的合作伙伴開辟調用通道的時候。
那些以API為產品驅動的團隊,既需要檢查諸如錯誤和延遲之類的指標,也需要了解API的使用方式,包括為何無法實現其預定的效果等方面。
7、API使用量的增長
對于許多產品經理來說,API的使用率是一項黃金標準,可以衡量API作為產品的轉換效果。一個好的API產品不僅應該沒有缺陷,而且有著與日俱增的實際使用量。通常情況下,我們可以月為單位衡量API使用量的增長。
8、API專門使用者
當然,一個月內某個API使用的增加量可能僅來自于某一個用戶賬號,因此我們需要衡量API的月活用戶(Monthly Active Users,MAU)或是API的專門使用者(unique consumers)。此類指標可以讓您獲悉用戶的“拉新”和使用量增長的整體狀況。同時,許多API平臺團隊也會將API的MAU與其網站的MAU相關聯,以獲取完整的產品態勢。
9、使用API的頭部用戶
對于一些專注于B2B業務的公司而言,了解自己的API產品有哪些頭部用戶是非常必要的。這些少數頭部用戶通常會為您的公司帶來更多的收入和轉發推薦,因此您可以據此來調用對應的節點,并對它們采取進一步的細分,以獲悉其使用特定節點的頻率,和使用時的體驗。
10、API的使用與留存
您也許正在疑惑到底是應該在產品和工程上投入更多,還是在增長上燒錢?光看用戶的留存與流失是無法給出清晰的參考依據。畢竟有些用戶雖然覺得您的API不夠友好,但是迫于已經訂閱的年度合同,而無法馬上退訂,但是他們并不會積極地使用您所提供的API。因此,我們需要跟蹤的是API作為一種產品,在用戶側的實際使用情況。
11、首次進入時間(TTFHW)
作為一項重要的KPI,首次進入時間(Time to First Hello World,TTFHW),不僅可以跟蹤API產品的運行狀況,而且可以跟蹤開發者的總體體驗(developer experience,DX)。
如果您的API是一個吸引第三方開發人員和合作伙伴來使用的開放平臺,那么您需要確保他們在首次調用時,就能夠順利流暢運用您提供的API來開發應用。TTFHW主要衡量的是:從首次訪問目標網頁到通過您的API平臺進行首次事務的MVP集成時間。該指標不但適用于API本身,也能考察您的營銷效果、以及配套的文檔和教程。
12、每種業務交易的API調用
盡管一般而言,各種產品和業務的指標往往是多多益善的,但每一種業務交易的調用次數卻是越少越好。該指標直接反映了API的設計水平。如果新的用戶需要通過三次不同的調用,才能將數據組合到一起的話,那么這可能意味著該API沒有找到正確的節點。因此在設計API時,我們應當考慮到業務交易本身、以及用戶想要達到的目標,而不僅僅是能夠提供的功能和涉及到的節點。此外,您還可能需要對API采取靈活的過濾和分頁操作,具體請參見:https://www.moesif.com/blog/technical/api-design/REST-API-Design-Filtering-Sorting-and-Pagination/?utm_source=dzone&utm_medium=paid&utm_campaign=placed%20article&utm_term=13%20api%20metrics。
13、SDK和版本的采用
許多API平臺團隊還可能需要維護大量的SDK和集成。與僅以iOS和Android為核心的移動端不同,您的平臺上可能擁有十來個、甚至上百個SDK。因此,對它們進行持續維護往往既費時又費力。那么,您可以選擇性地將一些關鍵性的功能部署到那些最受歡迎的SDK之中。同時,在棄用某些節點和功能時,您也需要詢問那些頭部用戶的意見,以做出對于API或SDK的取舍,以及版本的權衡。
結論
對于任何從事API構建和使用的人員來說,跟蹤正確的API指標是至關重要的。不同的團隊成員對于不同的API指標有著不同的關注點,也更能夠從自身專業的角度解決當前和潛在的性能問題。希望上述討論能夠給您和您的團隊提供一定的幫助。
原文標題:13 API Metrics That Every Platform Team Should Be Tracking,作者:Derric Gilling
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】

















