機器學習模型太大難部署?這里有 3 個解決方案
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
雖然因“疫情”的影響,讓技術人群放棄了聚會,減少了面對面溝通,但他們對于學習和交流的渴望從未停歇過。為此華為特別推出了#Σco時間#系列欄目,以線上直播+互動的形式,共話技術變革與行業轉型。
3月4日下午3點,本期#Σco時間#聚焦的話題是“大數據存算是‘分’還是‘合’,您做對了嗎?”——華為智能數據與存儲分布式存儲高級營銷專家崔玉祥來到了華為“智能數據基礎設施「學數派」”直播間,分享了華為如何看待存算分離的價值,以及華為大數據的存算分離解決方案和應用實踐,并與上千位線上嘉賓探討了存算分離技術的發展趨勢和市場前景。
數字經濟時代,大數據架構走向存算分崔玉祥介紹道,在數字經濟時代,數據已經成為新的生產資料,并從數據管理走向數據運營,大數據正發揮著越來越重要的作用,數據驅動體驗、數據驅動決策、數據驅動流程的各種應用每天都在不斷上演。隨著5G和AI技術的發展,數據量必將迎來爆發式的增長,在這樣的形勢下,傳統的大數據存算一體架構,在多個行業都面臨著資源利用率不均、存儲成本高、資源共享難的挑戰。
以國內電信運營商為例,每年市場采購金額高達上億元,但是如此巨大的投資在支持電信業務的同時,也帶來了計算資源浪費,龐大的服務器設備占據機房空間導致制冷供電費用高漲等諸多挑戰,“降本增效”成為電信運營商的重要訴求。而同樣的,提升資源利用率,部署彈性靈活,按需調度計算資源這些訴求,也成為金融、政務領域用戶亟待解決的課題。

如何化解這么多挑戰?崔玉祥認為,計算存儲分離是大數據架構演進的必然趨勢,也是解決行業用戶數據痛點的一大利器。他解釋道,在Hadoop1.0時代,計算和存儲是高度融合的,僅能處理單一的MapReduce分析業務;到了Hadoop2.0時代,計算層與數據開始解耦,通過Yarn實現了獨立的資源管理,并開始支持Spark等更多的計算引擎;而如今已經到了Hadoop3.0時代,計算存儲走向分離,通過Hadoop EC來支持冷數據的存儲,逐步向數據湖架構演進。“存算分離其實更適合企業級市場,它實現了資源云化和靈活擴展,能夠讓用戶享受更專業的存儲,更佳的可靠性和利用率。”
三大優勢令華為OceanStor分布式存儲更懂用戶
在2019年,華為創新性地推出了大數據存算分離解決方案,崔玉祥向觀看嘉賓詳細講解了華為OceanStor分布式存儲,一個能夠打造更高性價比的大數據存儲方案。簡直就是為多樣式存儲和超大數據量的用戶量身定制。“簡單總結,華為OceanStor分布式存儲最鮮明的三個特點就是成本最優、效率最高、使用最簡。”
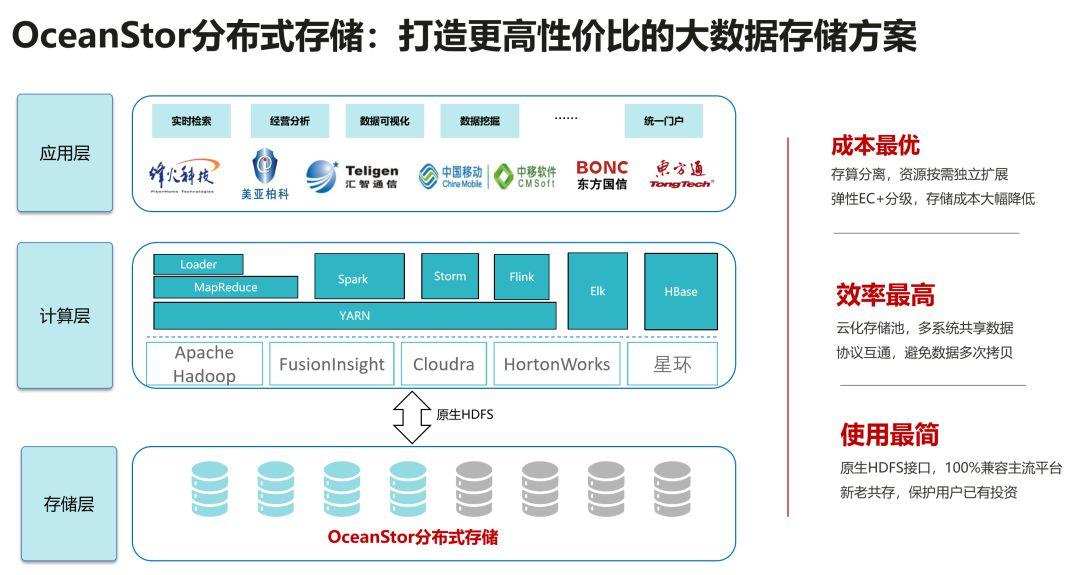
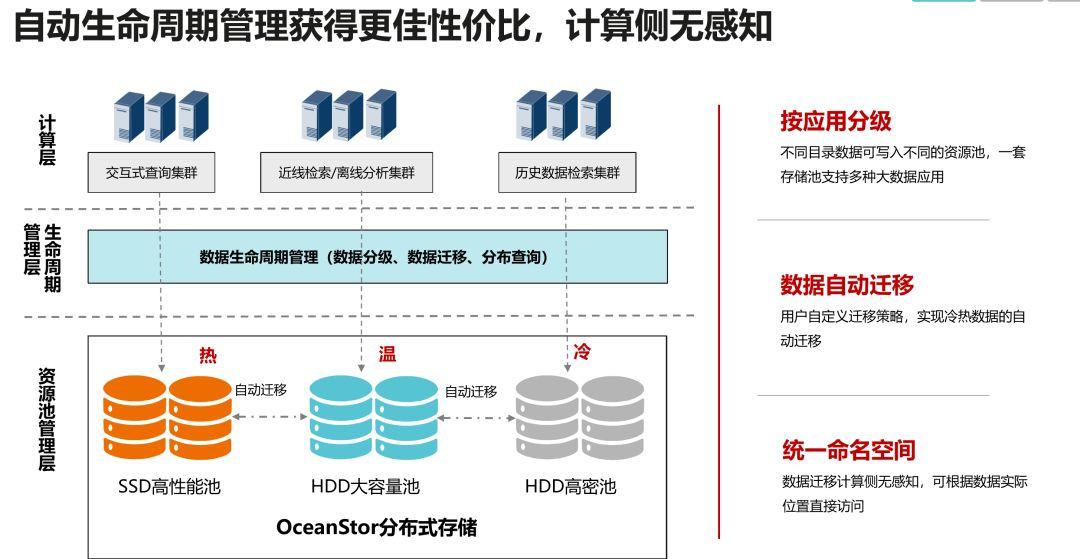
【成本最優】在成本方面,華為OceanStor分布式存儲實現存算分離,資源按需獨立擴展,彈性EC+分級,存儲成本大幅降低。“性能、可靠性和HDFS三副本相當,但是存儲利用率相比三副本提升1.75倍,”崔玉祥還特別指出,OceanStor分布式存儲可以通過自動生命周期管理獲得更佳的性價比,且計算側無感知。用戶可以定義不同的數據寫入策略,使不同類型的應用讀寫不同的存儲池,實現資源的物盡其用;用戶還可以定義數據遷移策略,實現熱、溫、冷數據的自動轉換,降低整體TCO。
他以上文中提到的電信運營商為例,運營商日志留存場景下,計算利用率為30%時,總容量需求大于256TB 時,改用存算分離方案會有TCO優勢;總容量需求大于2PB時,存算分離方案的TCO節省會達到40%以上。
【效率最高】在數據應用效率方面,華為OceanStor分布式存儲采用全對稱分布式NameNode,集群性能和支持文件數隨節點數目增加,單一命名空間支持文件數達百億級。不僅如此,華為還實現了多集群數據融合互通,提升數據共享和分析效率,協議互通更是提升了分析效率30%,降低空間占用50%。“在一家金融客戶的應用測試中,基于相同的計算和存儲硬件配置,OceanStor存儲存算分離方案在大部分測試中,性能均超過了原生HDFS三副本,部分測試項的執行時間甚至降低了70%以上。”
【使用最簡】在實際操作運維方面,華為原生HDFS接口提供了更佳性能和使用體驗,例如完整HDFS語義100%兼容主流大數據組件,用戶無需安裝插件,安裝維護簡單。更重要的是,通過ViewFS或Hbase元數據網關方式可以實現新老共存,保護用戶已有投資,系統級數據冗余保護能夠支持4節點同時失效。崔玉祥特別強調,即使發生節點故障,華為OceanStor分布式存儲也能夠自動調整EC級別,確保新寫入數據可靠性不下降,與此同時,多節點并行重構,可實現2TB/小時數據恢復效率。
存算分離,助力千行百業大數據進階
自2019年以來,華為OceanStor分布式存儲解決方案已經被廣泛應用在電信、金融、政務、大型企業各個領域中。在本次直播活動中,崔玉祥專門分享了兩個有代表性的應用案例。
在江蘇,原有的政務系統大多采用的是煙囪化部署,數據孤島比比皆是。然而隨著數據量快速增長,江蘇決定基于華為存算分離解決方案開始打造分層解耦、高效共享的大數據平臺。華為幫助江蘇政務系統打造了一個統一大數據平臺,可以同時支撐多種業務,實現部門間數據快速共享,實現政務服務“最多跑一次”。在部署中,存算分離就大顯身手,加上計算資源和存儲資源云化,實現了資源靈活分配,業務上線時間縮短90% 。同時,借助OceanStor分布式存儲的彈性EC技術,將存儲利用率從33% 提升到91.6%,從容應對數據快速增長的挑戰。
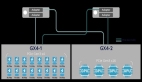
在河北電信,已部署安裝了89臺存算一體的大數據集群,整體存儲空間使用率已超80%,存儲空間不足,經常需要通過刪除數據的方式釋放存儲空間。而且現有機房空間緊張,僅能容納135臺2U服務器,按原有存算一體方式擴容,機房空間無法滿足要求。對此,華為創新性地采用存算一體+存算分離共存的方案,擴容100個計算節點+35個存儲節點,使用Hadoop數據聯邦方案(ViewFS),既解決了新老共存問題,又實現 了性能和容量的均衡擴展,相比原始方案提升60%可用容量。崔玉祥指出,存算分離方案無縫擴容,數據均衡讀寫,用戶既不需要升級現網大數據版本,也不需要遷移現網數據。
相信通過本次直播活動,及華為大咖帶來的精彩分享,行業用戶對于存算分離將會有更加深刻的認識,對于如何選擇合適自己的存算分離解決方案,也能做到心中有數了。