程序員必知必會,學會這兩點,提升系統魯棒性
很多程序員,都希望提升自己系統的擼棒性,什么是擼棒性呢?這個其實是從英文直譯過來的,就是程序員的健壯性。相信不少程序員同學都聽過服務雪崩,或者曾經使用過某款軟件雪崩過。當服務發生雪崩的時候,幾乎整個系統會處于不可用的狀態,為什么會發生服務雪崩呢?我們舉一個常見的例子。
因為新冠病毒的影響,口罩成為了稀缺物品,很多電商平臺紛紛開啟了口罩秒殺活動。一次口罩秒殺的正常流程可能是這樣的,用戶在前端發起請求,經過了復雜的網絡環境,到了后臺系統,后臺是分很多個系統的,可能需要去商品系統去校驗商品的合法性,然后去用戶系統校驗用戶的合法性,再去庫存系統校驗還有沒有庫存,最后可能還要去積分系統、優惠系統、地址系統等等等。一次簡單的秒殺,后臺竟然如此復雜。而這么多系統,只要有一個系統出現瓶頸,就可能出現雪崩。例如庫存系統,每秒本來可以處理1萬個請求,突然來了10萬個請求,他們只能夠排隊處理,可能只處理了5萬個,后面的就超時了。超時了,用戶的頁面就有可能轉菊花,用戶很難受,就有可能不停的刷新,又涌進來更多的請求。本來用戶系統可能可以處理10萬個請求,因為用戶不停的刷新,也崩潰了。而用戶系統可不只影響了秒殺,一些使用其他功能的用戶也被迫重試,最后,整個系統都趨于崩潰。
為了避免服務雪崩,我們需要做點什么,通常我們會使用限流或者熔斷機制。限流,顧名思義,就是限制流量的大小。這個在日常生活中,我們也并不陌生。例如北上廣深的地鐵站,高峰時期就經常限流。本來10分鐘只能搭乘500名乘客,這個時候我們讓2000名乘客到站臺等也是毫無意義,徒增風險,限流系統就是這種理念。預估好每個系統的容量,例如庫存系統,一秒鐘只能處理1萬個請求,那么我們就讓只有1萬個請求能夠請求到庫存系統。其他的請求直接拒絕,告訴他們,庫存已經售光了,下次再來。這就可以很好地保護到我們的系統。
另一種常見的手段,便是熔斷。熔斷就跟我們的保險絲一樣,一旦電流達到某個值,就會燒斷保險絲,從而保護到用電安全。熔斷在分布式系統中其實也比較常見,一般有著下面三種狀態。全開,表示服務運行正常,關閉,表示觸發熔斷,無法正常調用,半開,部分請求會被攔截。
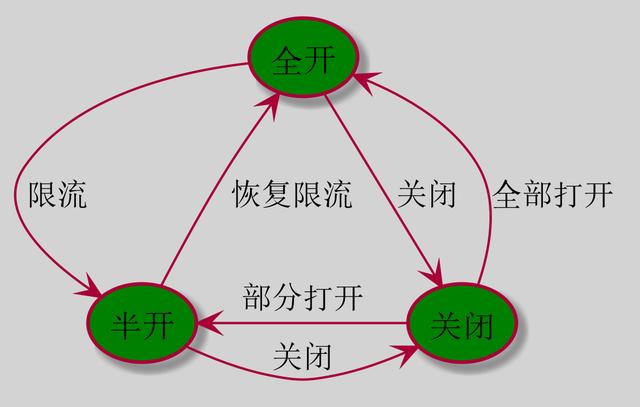
那么熔斷系統有什么用呢?我們舉一個簡單的例子,假如我們的服務是部署在多個機房的,突然有一天,某個機房的光纖被挖斷了。這個時候,使用這個機房的服務基本都會失敗了,這個時候,如果沒有熔斷系統,就會有持續不斷的請求進入這個機房,結果必然是超時或者失敗。最后引發上游業務的不斷重試,引起雪崩。如果這個時候有熔斷的存在,很快請求就會被路由到其他機房,從而達到對系統的保護。
那么,如何設計一個熔斷系統呢?只要掌握了以下幾點,相信并不困難。
- 位置 在一個分布式服務中,那些服務是瓶頸就是最有可能需要熔斷的地方。
- 錯誤類型 在一個服務中,通常有各種類型的錯誤,有些是系統失敗,像服務超時,運行時異常,有些則是邏輯失敗,像訂單重復取消,要正確的區分不同的錯誤,有些錯誤要觸發熔斷,有些則是可以跳過。
- 性能 一個好的熔斷服務,對性能的影響應該是較小的。不難因噎廢食,為了計數的準確而加了大力度的鎖,從而造成性能大幅下跌。
- 服務恢復 一般,熔斷的服務恢復有兩種模式,一是自動恢復,熔斷系統隔斷時間進行服務探測,如果探測成功會進行服務恢復。另一種則是提供手動重置,例如我們誤處理了一個錯誤碼,造成系統熔斷,那么我們需要手工重置。
- 日志 日志是必須的,特別是錯誤日志。所有的架構設計,都需要日志系統,不然就變成了薛定諤的熔斷系統了。
好了,今天我們就介紹道這里,歡迎大家關注我,整理后會和大家繼續分享。大家的支持是我繼續嘮嗑的動力。