













企業知識圖譜面臨的機遇、挑戰及解決方案
譯文【51CTO.com快譯】作為提高企業的運營效率和業務部門競爭力的必備工具,企業知識圖譜(Enterprise Knowledge Graphs,EKG)正日益被廣泛地運用在協調組織內、外部數據的不同場景中。不過,作為事物的另一面,EKG的弊端則主要體現在:業務部門可能難以對其進行開發、維護、以及擴展。本文介紹了EKG目前尚存在的各種挑戰,以及如何使用原生的多模型數據庫所提供的靈活的數據表示,來解決這些挑戰(請參見圖1)。
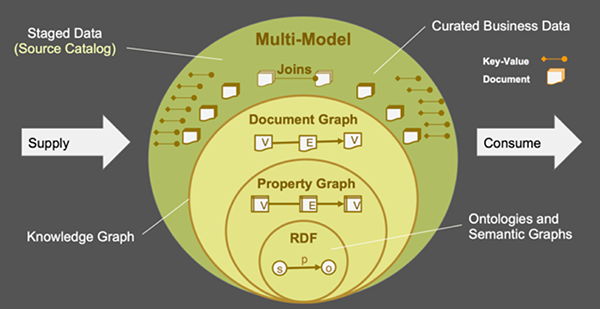
圖1:多模型知識圖譜能夠在一個系統中融合多種數據表示
什么是企業知識圖譜?
目前,知識圖譜已經為Google、Apple、Facebook、Twitter、MicroSoft、Linkedin、Ebay以及阿里巴巴等公司創造了數萬億美元的財富。它們主要是通過自行研發技術棧(technology stacks)來支持知識圖譜。相對于開源的EKG,商業化圖形數據庫產品的開發,則是根據行業或企業特定的知識模型,來協調組織的內容、數據、以及信息資產。
EKG通常表示某個組織的知識領域,以及那些可被人工和機器理解的組件。它是對本組織的知識資產、內容和數據的參考集合。此類集合利用某種數據模型來描述人員、地點、事物、以及它們之間的關系。
雖然許多企業都部署了各種類型的業務知識圖譜(business knowledge graph,BKG)方案,但是并非所有的圖譜都能叫做EKG。EKG的主要驅動力源自:為滿足特定業務需求而構建定制化的知識圖譜。如果說BKG主要旨在支持那些細分的業務用例,那么EKG則旨在向多個業務部門提供高質量的統一數據,以及多種用例。在下一節中,我們將討論在利用EKG支持業務用例時,所面臨的挑戰和機遇。
EKG的挑戰與機遇
對于業務部門而言,由于EKG包含了來自多個數據源的高凈值數據,因此它省去了為支持業務用例而集成數據源所使用的時間和精力。目前許多EKG方案都能夠根據企業的概念模型,來協調多個截然不同的異構源系統。這些原始數據通常被暫存在諸如Hadoop/HDFS、S3等分布式的存儲系統上,中間件群集會將這些數據提取并轉換(Extract Transform Load,ETL)到圖形數據庫的群集之中。
由于EKG能夠支持諸如企業級搜索之類的應用,因此它們需要提取和轉換各種格式(如:文檔、表格、鍵值和圖形)的EKG數據,以支持業務應用。
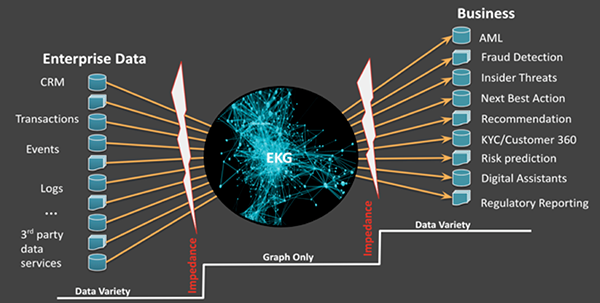
圖2:在協調圖譜和提供數據時,可能產生不匹配的現象
由于企業往往難以將數據協調成為EKG所需的復雜多源數據,因此EKG常常無法發揮出其全部的潛力。同時,業務用戶不但難以應對復雜且生疏的知識圖譜表示形式,而且缺乏使用它們的工具。雖然企業可以通過付出巨大的努力,將數十個、乃至數百個數據源整合到一個EKG中,并且解決諸如數據出處、以及權限保留之類的數據治理問題,因此業務部門在充分利用高質量EKG數據過程種,面臨著“最后一百米”的巨大挑戰。
其實,問題的本質在于,從數據到圖形的“全有或全無”轉換過程,會導致源數據表示形式與EKG之間、以及EKG與業務部門希望的數據處理方式之間的不匹配(見圖2)狀況。基于多模型的EKG,通過允許知識圖譜中表示形式的多樣性,來減少數據的不匹配。據此,圖譜將得以靈活地進行增量協調,而業務部門也能夠按需對數據進行最少的轉換。
多個數據源被協調到圖譜中的挑戰
企業需要協調好大量不同的數據源。通常情況下,被統一的相關數據源越多,對企業的潛在價值也就越大。當然,將數據協調到圖譜的成本,也會隨著數據源數量的增加而呈現指數級的增長。這就是為什么企業渴望找到能夠對數據進行自動協調,以及通過敏捷應用,來按需提供數據的協調方法。
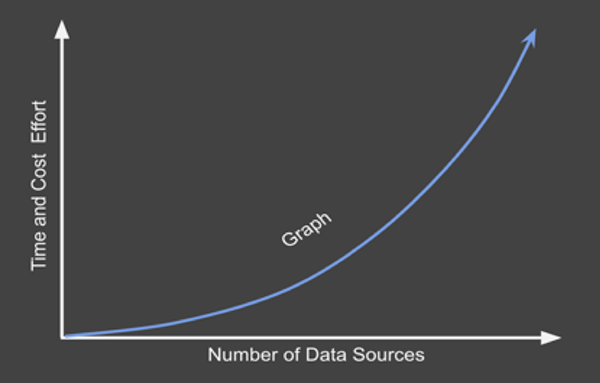
圖3:EKG的數據協調工作量會隨著數據源數量而呈現出指數級的增長
可見,我們需要通過復雜的知識表示形式,來表示不同數據的細微差別,并標準化圖譜結構。供知識圖譜使用與聯合的所有源數據,都需要被轉換成為單模型圖形數據庫中的圖表結構。當然,將源數據映射到這些復雜的知識圖譜表示形式是需要時間、精力、以及知識儲備的。
如下圖4所示,由于需要大量的資源,EKG的生成過程可能會影響到圖形數據庫的擴展性能。在實際應用中,總會有超過圖形數據庫擴展能力的海量數據,尤其是存儲鍵值和文檔等實際數據的時候。
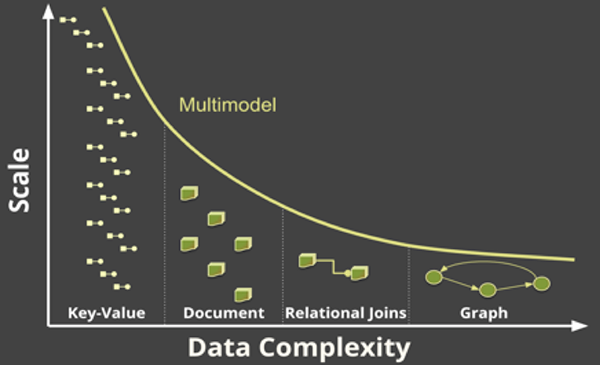
圖4:圖形處理數據的復雜度與文檔、鍵值的處理能力關系
基于上述原因,多模型數據庫恰好能夠以按需擴容和簡化圖形表示的方式,來融合各種鍵值、文檔、聯接(join)、以及圖形數據模型。例如:當用純圖形表示時,企業內部的網絡安全信息會逐年以數萬億條“邊(edge)”的速度增長。那么在結合了圖形、文檔和聯接之后,同一個企業網絡安全的圖譜則可能以數十億條“邊”來表示。
企業在尋找減少開發和維護EKG所需工作量的過程中,往往會捫心自問如下問題:
- 我們可以自動將源數據進行分類、映射和轉換為知識圖譜嗎?
- 在概念模型出現變化時,我們能夠自動重構EKG嗎?
- 我們能夠搜索數據源、知識圖譜,進而精選數據嗎?
鑒于目前尚無可用于將數據自動協調為圖形的實用方案,EKG必須是整體化的圖模型,并且所有數據都必須被轉換為圖才能真正有用。同時,通過允許包含其他類型的數據模型,我們可以減少EKG的部署和維護工作,增加EKG的潛在規模,并且提高EKG開發和維持的靈活性與敏捷性。另外,通過讓其他數據模型的知識圖譜將分段數據和圖形存儲在同一數據庫中,我們能夠以敏捷和迭代的方式進行圖形的協調。
讓EKG易用的挑戰
如前文所述,業務用戶難以應對復雜且生疏的知識圖譜的表示形式,而且缺乏使用它們的工具。在實際使用中,他們常會碰到如下EKG問題:
- 它能夠與我現有的工具一起使用嗎?
- 我的開發人員會知道如何使用它嗎?
- 我如何能夠找到相關的數據?
- 如何綁定所需的數據?
- 如何獲得所需的數據格式?
上述挑戰的實質源于:在EKG與業務部門需要使用和處理的數據方式之間,存在不匹配的狀況。例如:某家企業可能需要2017年1月至2019年12月的所有交易信息,并要求此類數據能夠以特定文檔結構(如JSON文檔集合)的形式提供出來。由于不想額外地學習或使用圖形查詢語言來達到該目的,因此他們需要一種“數據購物”的體驗。即:通過訪問EKG商店,并使用多重過濾器在EKG的目錄中搜索數據,然后他們根據EKG商店推薦的數據集,來補充現有的數據,并指定獲取數據的方式與時間。
多模型企業知識圖譜
多模型企業圖譜(Multi-model enterprise graphs,MMEKG)可以通過讓用戶在同一個生態系統中混合和管理數據源、EKG、以及數據的表示形式,以解決前面提到的各種問題。
減少時間和成本
MMEKG能夠按需對圖進行延遲轉換。由于允許在邊和頂點中包含不同的文檔,因此多模型圖譜能夠減小圖的大小。據此,EKG也可以使用敏捷迭代的過程來進行開發。
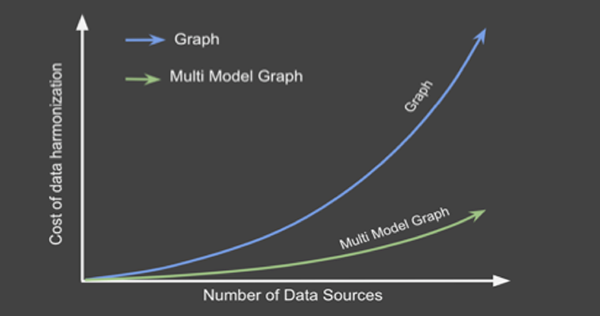
圖5:使用多模型圖譜能夠更有效地協調知識圖譜的數據
減少計算資源
如下圖6所示,EKG解決方案通常需要使用單獨的數據系統,來進行stage、圖形ETL、圖形管理、以及將數據傳遞給業務部門使用。MMEKG可以有效地消除源數據、知識圖譜、以及精選的業務數據之間存在的不匹配狀況。它不但可以在同一個系統中管理數據,而且能夠減少轉換的延遲,并使得所有的數據都可以被搜索。可見,它降低了使用單獨的集群來進行stage,轉換,圖形化,以及業務應用的相關成本(請參見圖7)。
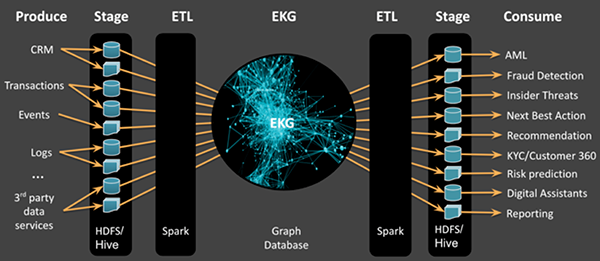
圖6:典型的EKG生態系統會使用多個系統來進行stage和轉換
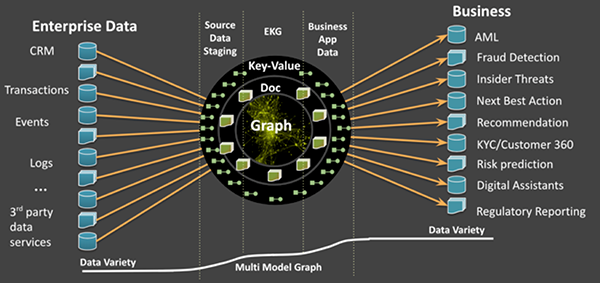
圖7:可以在同一多模型數據庫中管理源數據、EKG、以及業務數據
使用方便
由于多模型使得源數據、知識圖譜和業務應用數據,能夠在同一個數據系統中被搜索和找到,因此業務用戶可以采用自己的格式去使用數據,而不必了解復雜的企業圖譜模型。
數據沿襲(data lineage)
同樣由于采用了同一個多模型系統進行數據的stage,轉換和交付,因此跟蹤數據的沿襲也變得容易了許多。
增強現有的EKG
具有RDF(Resource Description Framework,資源描述框架)類EKG的企業,完全可以保留現有的投入,并在MMEKG中加以利用。因為多模型圖是RDF基于帶標記的有向圖的超集,因此模型數據庫可以吸收RDF的本體和RDF的EKG。類似地,多模型圖也包含有屬性圖,因此方便了吸收那些基于屬性圖的EKG。
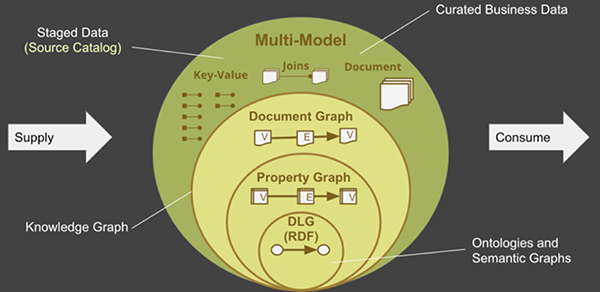
圖8:多模型的EKG可以提取RDF,以及基于屬性圖的EKG
總結
多模型(Multi-model)可謂針對EKG的實用技術,其優勢包括讓EKG的多源數據更加流暢,提高EKG數據在業務用例中的可用性,通過混合模型實現更高的可擴展性,以及減少EKG生態系統的復雜度。
原文標題:The Multi-Model Knowledge Graph,作者:Arthur Keen & Jan Stuecke
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】


























