數據挖掘之聚類分析總結(建議收藏)
聚類分析
一、概念
聚類分析是按照個體的特征將他們分類,讓同一個類別內的個體之間具有較高的相似度,不同類別之間具有較大的差異性
- 聚類分析屬于無監督學習
- 聚類對象可以分為Q型聚類和R型聚類
Q型聚類:樣本/記錄聚類 以距離為相似性指標 (歐氏距離、歐氏平方距離、馬氏距離、明式距離等)
R型聚類:指標/變量聚類 以相似系數為相似性指標 (皮爾遜相關系數、夾角余弦、指數相關系數等)
二、常用的聚類算法
- K-Means劃分法
- 層次聚類法
- DBSCAN密度法
1、K-Means劃分法
K表示聚類算法中類的個數,Means表示均值算法,K-Means即是用均值算法把數據分成K個類的算法。
K-Means算法的目標,是把n個樣本點劃分到k個類中,使得每個點都屬于離它最近的質心(一個類內部所有樣本點的均值)對應的類,以之作為聚類的標準。
K-Means算法的計算步驟
- 取得k個初始質心:從數據中隨機抽取k個點作為初始聚類的中心,來代表各個類
- 把每個點劃分進相應的類:根據歐式距離最小原則,把每個點劃分進距離最近的類中
- 重新計算質心:根據均值等方法,重新計算每個類的質心
- 迭代計算質心:重復第二步和第三步,迭代計算
- 聚類完成:聚類中心不再發生移動
基于sklearn包的實現
導入一份如下數據,經過各變量間的散點圖和相關系數,發現工作日上班電話時長與總電話時長存在強正相關關系。

選擇可建模的變量并降維。
- cloumns_fix1 = ['工作日上班時電話時長', '工作日下半時電話時長',
- '周末電話時長', '國際電話時長', '平均每次通話時長']
- #數據降維
- pca_2 = PCA(n_components=2)
- data_pca_2 = pd.DataFrame(pca_2.fit_transform(data[cloumns_fix1]))
通過sklearn包中的K-Means方法構建模型。
- #繪制散點圖查看數據點大致情況
- plt.scatter(data_pca_2[0],data_pca_2[1])
- #預計將數據點分類為3類
- kmmodel = KMeans(n_clusters=3) #創建模型
- kmmodel = kmmodel.fit(data[cloumns_fix1]) #訓練模型
- ptarget = kmmodel.predict(data[cloumns_fix1]) #對原始數據進行標注
- pd.crosstab(ptarget,ptarget) #交叉表查看各個類別數據的數量
plt.scatter(data_pca_2[0],data_pca_2[1],c=ptarget)#查看聚類的分布情況。
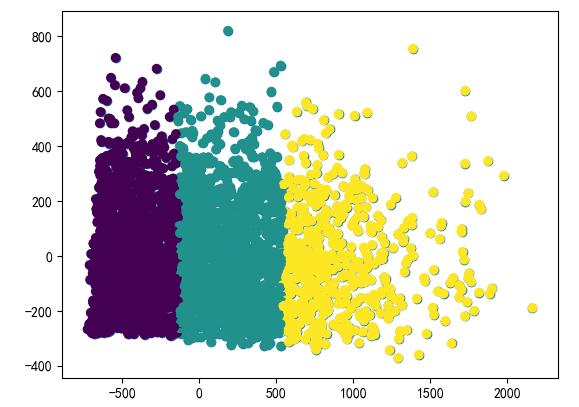
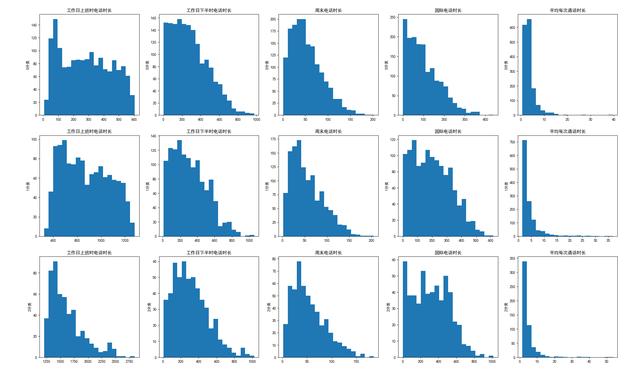
最后,可以通過直方圖查看各聚類間的差異。
- #查看各類之間的差異
- dMean = pd.DataFrame(columns=cloumns_fix1+['分類']) #得到每個類別的均值
- data_gb = data[cloumns_fix1].groupby(ptarget) #按標注進行分組
- i = 0
- for g in data_gb.groups:
- rMean = data_gb.get_group(g).mean()
- rMean['分類'] = g;
- dMean = dMean.append(rMean, ignore_index=True)
- subData = data_gb.get_group(g)
- for column in cloumns_fix1:
- i = i+1;
- p = plt.subplot(3, 5, i)
- p.set_title(column)
- p.set_ylabel(str(g) + "分類")
- plt.hist(subData[column], bins=20)
2、 層次聚類法
層次聚類算法又稱為樹聚類算法,它根據數據之間的距離,透過一種層次架構方式,反復將數據進行聚合,創建一個層次以分解給定的數據集。層次聚類算法常用于一維數據的自動分組。
層次聚類算法是一種很直觀的聚類算法,基本思想是通過數據間的相似性,按相似性由高到低排序后重新連接各個節點,整個過程就是建立一個樹結構,如下圖:
層次聚類算法的步驟:
- 每個數據點單獨作為一個類
- 計算各點之間的距離(相似度)
- 按照距離從小到大(相似度從強到弱)連接成對(連接后按兩點的均值作為新類繼續計算),得到樹結構
基于sklearn包的實現
使用K-Means聚類案例中的數據。
- cloumns_fix1 = ['工作日上班時電話時長', '工作日下半時電話時長',
- '周末電話時長',
- '國際電話時長', '平均每次通話時長']
- linkage = hcluster.linkage(data[cloumns_fix1], method='centroid') #中心點距離計算,得到矩陣
- linkage = scipy.cluster.hierarchy.linkage(data, method='single')
method 類距離計算公式有三種參數:
- single 兩個類之間最短距離的點的距離
- complete 兩個類之間最長距離的點的距離
- centroid 兩個類所有點的中點的距離
- #層次聚類繪圖
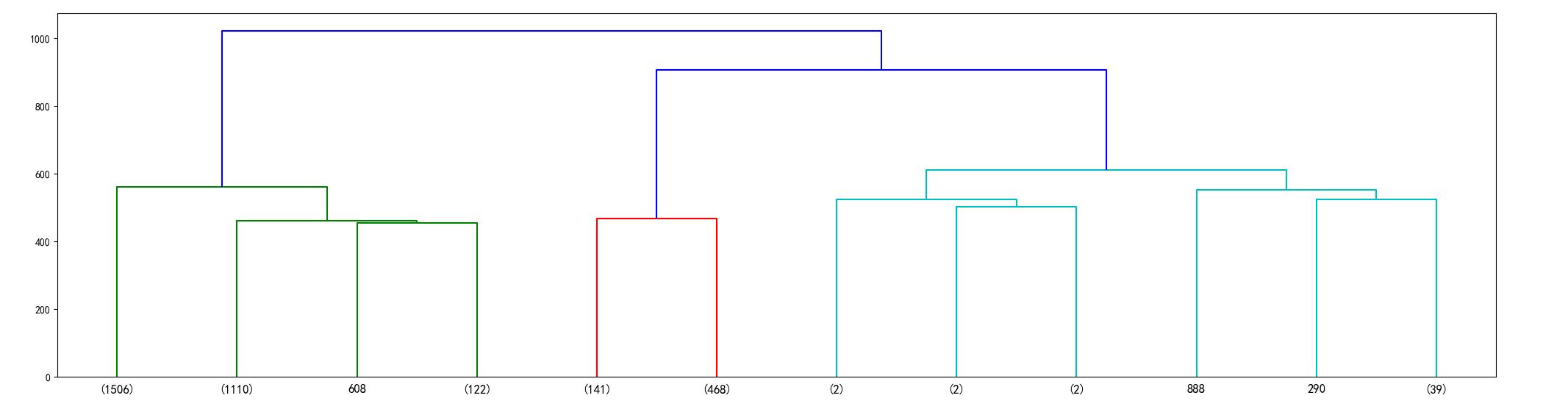
- hcluster.dendrogram(linkage) #不設置參數時會將所有點做為一個基礎的類進行樹結構的繪制
- #由于數據量大,限制類的個數,保留12個節點,有括號表示副節點,括號內的數字為該節點內部包含的子節點
- hcluster.dendrogram(linkage, truncate_mode='lastp', p=12, leaf_font_size=12.)
- #對聚類得到的類進行標注 層次聚類的結果,要聚類的個數,劃分方法
- (maxclust,最大劃分法)ptarget = hcluster.fcluster(linkage, 3,
- criterion='maxclust')#查看各類別中樣本含量
- pd.crosstab(ptarget,ptarget)
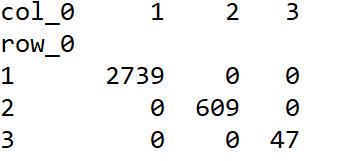
繪制圖形
- #使用主成分分析進行數據降維
- pca_2 = PCA(n_components=2)
- data_pca_2 = pd.DataFrame(pca_2.fit_transform(data[cloumns_fix1]))
- plt.scatter(data_pca_2[0], data_pca_2[1], c=ptarget) #繪制圖形
3、 DBSCAN密度法
概念:
- 中文全稱:基于密度的帶噪聲的空間聚類應用算法,它是將簇定義為密度相聯的點的最大集合,能夠把具有足夠高密度的區域劃分為簇,并可在噪聲的空間數據集中發現任意形狀的聚類。
- 密度:空間中任意一點的密度是以該點為圓心,以Eps為半徑的園區域內包含的點數目。
- 鄰域:空間中任意一點的鄰域是以該店為圓心,以Eps為半徑的園區域內包含的點集合。
- 核心點:空間中某一點的密度,如果大于某一給定閾值MinPts,則稱該點為核心點。(小于MinPts則稱邊界點)
- 噪聲點:既不是核心點,也不是邊界點的任意點
DBSCAN算法的步驟:
- 通過檢查數據集中每點的Eps鄰域來搜索簇,如果點p的Eps鄰域內包含的點多于MinPts個,則創建一個以p為核心的簇
- 通過迭代聚集這些核心點p距離Eps內的點,然后合并成為新的簇(可能)
- 當沒有新點添加到新的簇時,聚類完成
DBSCAN算法優點:
- 聚類速度快且能夠有效處理噪聲點發現任意形狀的空間聚類
- 不需要輸入要劃分的聚類個數
- 聚類簇的形狀沒有偏倚
- 可以在需要是過濾噪聲
DBSCAN算法缺點:
- 數據量大時,需要較大的內存和計算時間
- 當空間聚類的密度不均勻、聚類間距差較大時,得到的聚類質量較差(MinPts與Eps選取困難)
- 算法效果依賴距離公式選擇,實際應用中常使用歐式距離,對于高緯度數據,存在“維度災難” https://baike.baidu.com/item/維數災難/6788619?fr=aladdin
python中的實現
1)數學原理實現
導入一份如下分布的數據點的集合。
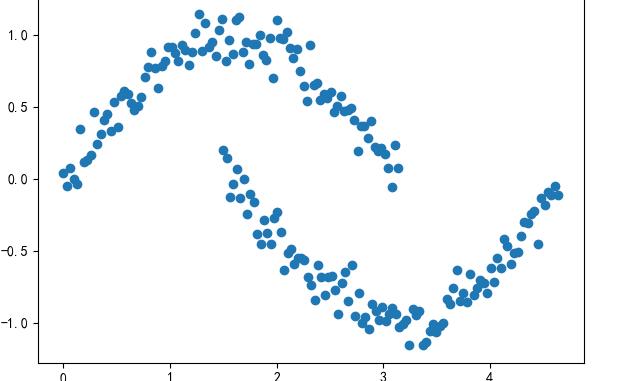
- #計算得到各點間距離的矩陣
- from sklearn.metrics.pairwise import euclidean_distances
- dist = euclidean_distances(data)
將所有點進行分類,得到核心點、邊界點和噪聲點。
- #設置Eps和MinPts
- eps = 0.2
- MinPts = 5
- ptses = []
- for row in dist: #密度 density = np.sum(row<eps)
- pts = 0
- if density>MinPts: #核心點,密度大于5
- pts = 1
- elif density>1 : #邊界點,密度大于1小于5
- pts = 2
- else: #噪聲點,密度為1
- pts = 0
- ptses.append(pts)
- #得到每個點的分類
以防萬一,將噪聲點進行過濾,并計算新的距離矩陣。
- #把噪聲點過濾掉,因為噪聲點無法聚類,它們獨自一類
- corePoints = data[pandas.Series(ptses)!=0]
- coreDist = euclidean_distances(corePoints)
以每個點為核心,得到該點的鄰域。
- cluster = dict()
- i = 0
- for row in coreDist:
- cluster[i] = numpy.where(row<eps)[0]
- i = i + 1
然后,將有交集的鄰域,都合并為新的領域。
- for i in range(len(cluster)):
- for j in range(len(cluster)):
- if len(set(cluster[j]) & set(cluster[i]))>0 and i!=j:
- cluster[i] = list(set(cluster[i]) | set(cluster[j]))
- cluster[j] = list()
最后,找出獨立(也就是沒有交集)的鄰域,就是我們最后的聚類的結果了。
- result = dict()
- j = 0
- for i in range(len(cluster)):
- if len(cluster[i])>0:
- result[j] = cluster[i]
- j = j + 1
- #找出每個點所在領域的序號,作為他們最后聚類的結果標記
- for i in range(len(result)):
- for j in result[i]:
- data.at[j, 'type'] = i
- plt.scatter(data['x'], data['y'], c=data['type'])
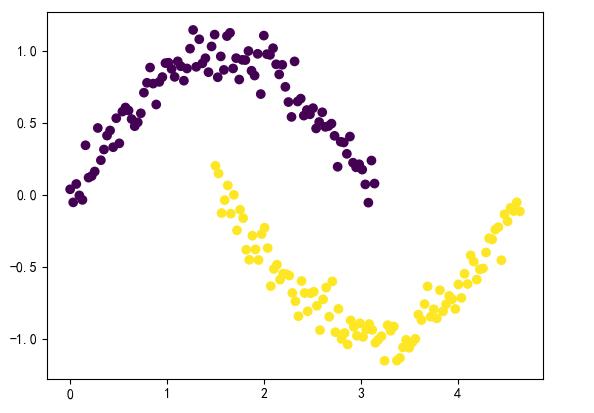
2)基于sklearn包的實現
- eps = 0.2
- MinPts = 5
- model = DBSCAN(eps, MinPts)
- data['type'] = model.fit_predict(data)
- plt.scatter(data['x'], data['y'], c=data['type'])