













解決棘手SQL性能問題,我的SQLT使用心得
一、SQLT背景介紹
SQLTXPLAIN(簡稱SQLT)是ORACLE COE提供的一款SQL性能診斷工具,SQLT主要方法是通過輸入的一個SQL語句,從而生成一組診斷文件,這些文件用于診斷性能較差的或產生錯誤結果(WRONG RESULTS)的SQL。
SQLT產生的診斷文件內容包括執(zhí)行計劃、統(tǒng)計信息、CBO的參數(shù)、10053文件、性能變化的歷史等需要診斷SQL性能的一系列文件,而且SQLT還提供一系列工具,比如快速綁定SQL執(zhí)行計劃的工具。
SQLT主要使用場合是在需要快速綁定SQL執(zhí)行計劃,或者一些和參數(shù)、BUG等相關的疑難SQL分析中。
二、SQLT家族簡介
SQLT主要包含下列方法:
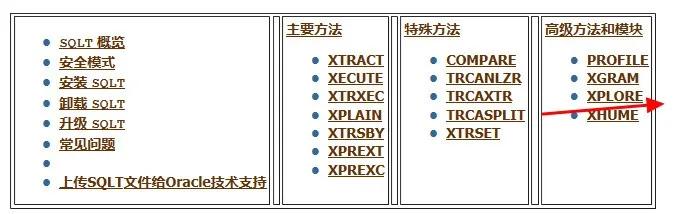
SQLT為一個SQL語句提供了下面 7種主要方法來生成診斷詳細信息XTRACT,XECUTE,XTRXEC,XTRSBY,XPLAIN,XPREXT和XPREXC。XTRACT,XECUTE,XTRXEC,XTRSBY,XPREXT和XPREXC處理綁定變量和會做 bind peeking(綁定變量窺視),但是XPLAIN不會。這是因為XPLAIN是基于EXPLAIN PLAN FOR 命令執(zhí)行的,該命令不做 bind peeking。
因此,如果可能請避免使用XPLAIN,除了XPLAIN的bind peeking限制外,所有這 7種主要方法都可以提供足夠的診斷詳細信息,對性能較差或產生錯誤結果集的SQL進行初步評估。如果該SQL仍位于內存中或者Automatic Workload Repository (AWR) 中,請使用XTRACT或XTRXEC,其他情況請使用XECUTE。對于Data Guard或備用只讀數(shù)據(jù)庫,請使用XTRSBY。僅當其他方法都不可行時,再考慮使用XPLAIN。XPREXT和XPREXC是類似于XTRACT和XECUTE,但為了提高SQLT的性能它們禁了一些SQLT的特性。
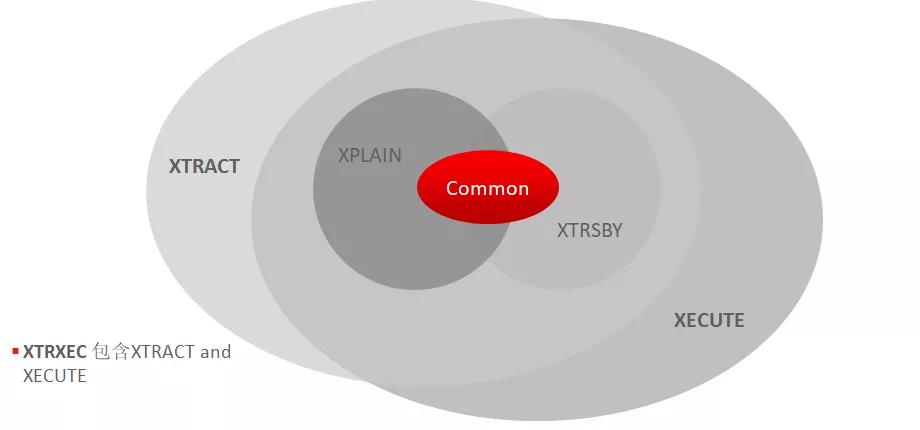
幾種主要方法的關系如下:
其中XTRXEC包括了XTRACT和XECUTE方法,實際上它會同時執(zhí)行這兩個方法生成對應的文件。使用這些方法后,會生成文件,自動打包。
SQLT的詳細內容請參考MOS文檔:SQLT 使用指南 (Doc ID 1677588.1),本文重點說下SQLT里比較有用的方法(本文內容的環(huán)境是11.2.0.3)。
三、SQLT寶劍出鞘
1、SQLT生成診斷文件
生成診斷文件使用的是sqlt/run目錄下的文件,此目錄下還有SQLHC健康檢查的腳本。這里看一個例子:
- SQL text:
- select *
- from test1
- where test1.status in (select test2.status from test2
- where object_name like 'PRC_TEST%');
這是條簡單的子查詢SQL,其中test1的status有索引,而且status有傾斜分布如下:
- dingjun123@ORADB> select status,count(*)
- 2 from test1
- 3 group by status;
- STATUS COUNT(*)
- ------- ----------
- INVALID 6
- VALID 76679
- --子查詢結果是INVALID
- dingjun123@ORADB> select test2.status from test2
- 2 where object_name like 'PRC_TEST%'
- 3 ;
- STATUS
- -------
- INVALID
- INVALID
子查詢中的語句返回的正好是INVALID,那么可以預測,此語句應該是用子查詢結果驅動表test1,走test.status列的索引,正常的應該是走nested loops。OK,那么我們看看執(zhí)行計劃:
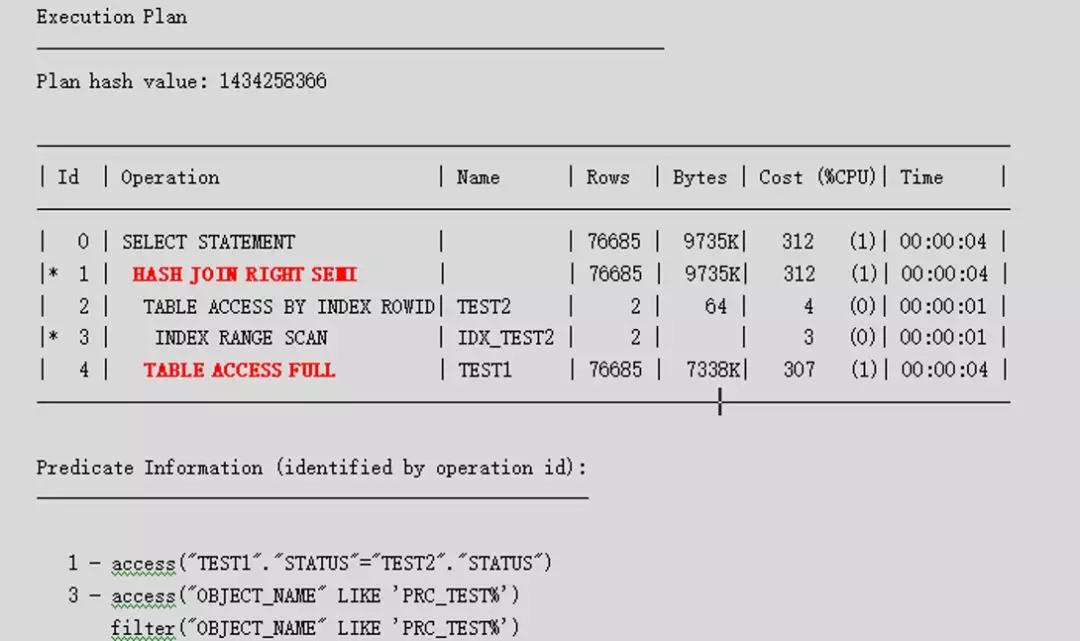
執(zhí)行計劃令人費解,要知道,對于表的統(tǒng)計信息是最新的且采樣比例100%,而且也收集了STATUS列的直方圖,為什么還走HASH JOIN,而且TEST1還走全表呢?先用SQLT診斷下,到sqlt/run目錄下找到對應的腳本,然后輸入SQLID,之后會將生成的文件打包。
- dingjun123@ORADB> @sqltxtrxec
- PL/SQL procedure successfully completed.
- Elapsed: 00:00:00.00
- Parameter 1:
- SQL_ID or HASH_VALUE of the SQL to be extracted (required)
- Enter value for 1: aak402j1r6zy3
- Paremeter 2:
- SQLTXPLAIN password (required)
- Enter value for 2: XXXXXX
- PL/SQL procedure successfully completed.
- Elapsed: 00:00:00.00
- Value passed to sqltxtrxec:
- SQL_ID_OR_HASH_VALUE: "aak402j1r6zy3"
解壓文件,即可看到如下內容:
這里我們主要看main文件,這是主要內容以及10053等。
首先打開main文件,可以看到主要診斷內容:

可以看到,包括CBO的環(huán)境,執(zhí)行計劃以及歷史執(zhí)行信息,表,索引等對象統(tǒng)計信息都在這個main文件中,大部分時候可以通過此文件,了解SQL效率不佳的原因,比如執(zhí)行計劃變壞的時間段內正好收集了統(tǒng)計信息,那么可以快速定位可能是統(tǒng)計信息收集不正確導致的。
一般情況下,都是先看執(zhí)行計劃,通過Plans目錄找到Execution Plans,可以點那些+,會顯示對應的統(tǒng)計信息等內容:
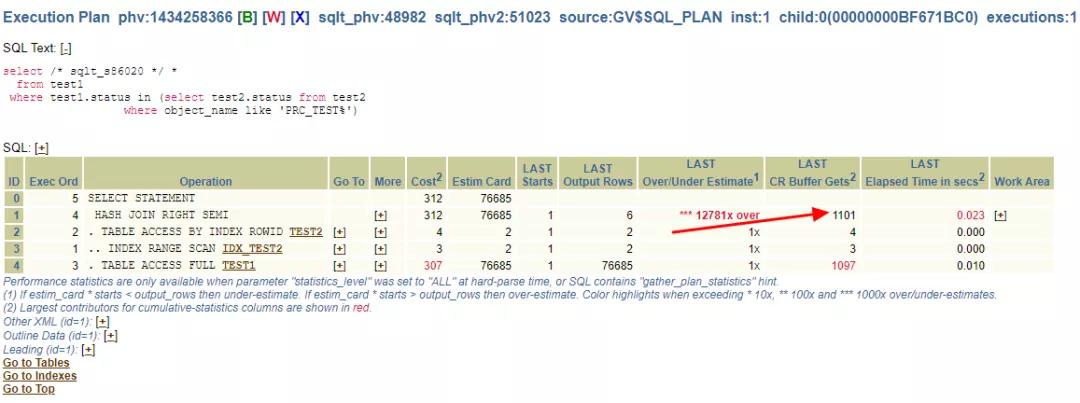
在統(tǒng)計信息正確的情況下,CBO估算的返回結果行是76685行,而實際結果是6行,估算是實際的12781倍,這顯然是有問題的。可以點開對應的+,看看統(tǒng)計信息:
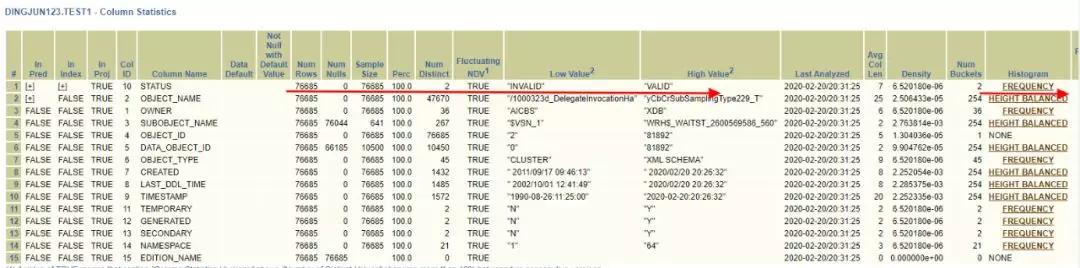
TEST1的STATUS列收集了直方圖,而且是100%采樣,沒有任何問題。到此,這個簡單的SQL很可能的情況就是:
- CBO的缺陷,無法準確估算對應的結果集的cardinality;
- CBO的BUG或參數(shù)設置原因。
針對以上兩種情況,后面會介紹解決方法,這里先說下,為什么這里走了HASH JOIN,TEST1走了FULL TABLE SCAN,結果集的cardinality估算的結果正好是TEST1的行數(shù)呢,原因在于:
- TEST1的STATUS有直方圖;
- 子查詢結果查詢出STATUS,但是查詢結果的STATUS值在沒有執(zhí)行之前是未知的,也就是可能是INVALID也可能是VALID。
綜合以上因素,CBO無法在運行期之前預知結果的具體值,從而導致優(yōu)化器缺陷,走了不佳的執(zhí)行計劃(12C的apative plan可以解決這個問題)。
既然知道是這個原因,那么,就采用SQL PROFILE綁定就可以了,詳細內容見下節(jié)。
2、SQLT快速綁定執(zhí)行計劃
SQL PROFILE可以使用SQLT工具快速綁定,SQL PROFILE就是對SQL增加了一系列HINTS,好處是不需要改寫SQL,可以在數(shù)據(jù)庫里直接管理。
對于COE工具SQL PROFILE綁定有兩類:
- 直接綁定:針對執(zhí)行計劃經常突變的,歷史中有好的執(zhí)行計劃,當前走的執(zhí)行計劃差,直接綁定即可。
- 替換綁定:針對執(zhí)行計劃一直較差,沒有好的執(zhí)行計劃作為參考,可通過添加hints讓其走好的執(zhí)行計劃,然后通過coe工具手動修改文件或coe_load_sql_profile或者編寫存儲過程綁定到好的執(zhí)行計劃上。
注意:如果SQL沒有綁定變量,則通過coe_xfr_sql_profile生成的文件需要修改force_match=>true,手動編寫存儲過程或者coe_load_sql_profile做替換綁定的也需要修改force_match=>true,以讓所有SQL結構相同(字面量條件不同)的SQL都綁定上好的執(zhí)行計劃。
(對應的綁定計劃的腳本在sqlt/utl目錄下)
下面分別說說這兩種綁定方式:
1)使用coe_xfr_sql_profile腳本直接綁定
針對SQL執(zhí)行計劃經常突變,當計劃變差時候,快速綁定到效率高的執(zhí)行計劃中。如下例:運行code_xfr_sql_profile然后輸入sql_id:
- SQL> @coe_xfr_sql_profile.sql
- Parameter 1:
- SQL_ID (required)
- Enter value for 1: 0hzkb6xf08jhw
- PLAN_HASH_VALUE AVG_ET_SECS
- --------------- -----------
- 3071332600 .006 --效率高的計劃
- 40103161 653
- Parameter 2: ---------------次數(shù)輸入需要綁定的PLAN_HASH_VALUE,顯然我們輸入3071332600
- PLAN_HASH_VALUE (required)
- Enter value for 2:
- 最后生成文件,執(zhí)行。
- 注意:如果SQL沒有使用綁定變量,需要將生成文件的force_match => FALSE中的FALSE改成TRUE。
2)使用coe_load_sql_profile做替換綁定
3.1中的例子是由于CBO的缺陷導致無法判定子查詢結果,從而導致走錯了執(zhí)行計劃,這里在12c之前需要綁定執(zhí)行計劃,因為沒有現(xiàn)成的執(zhí)行計劃,所以需要自己寫hints構造一條正確執(zhí)行計劃的SQL,然后通過SQLT的替換綁定,將正確執(zhí)行計劃綁定到原SQL中去。
先將原始SQL通過增加hints,讓其執(zhí)行計劃正確,改造后的SQL如下:
- select/*+
- BEGIN_OUTLINE_DATA
- USE_NL(@"SEL$5DA710D3" "TEST1"@"SEL$1")
- LEADING(@"SEL$5DA710D3" "TEST2"@"SEL$2" "TEST1"@"SEL$1")
- INDEX_RS_ASC(@"SEL$5DA710D3" "TEST2"@"SEL$2" ("TEST2"."OBJECT_NAME"))
- INDEX_RS_ASC(@"SEL$5DA710D3" "TEST1"@"SEL$1" ("TEST1"."STATUS"))
- OUTLINE(@"SEL$2")
- OUTLINE(@"SEL$1")
- UNNEST(@"SEL$2")
- OUTLINE_LEAF(@"SEL$5DA710D3")
- ALL_ROWS
- DB_VERSION('11.2.0.3')
- OPTIMIZER_FEATURES_ENABLE('11.2.0.3')
- IGNORE_OPTIM_EMBEDDED_HINTS
- END_OUTLINE_DATA
- */ *
- from test1
- where test1.status in (select test2.status from test2
- where object_name like 'PRC_TEST%');
然后使用coe_load_sql_profile腳本做替換綁定,輸入原始的sql_id和替換的sql_id:
- dingjun123@ORADB> @coe_load_sql_profile
- Parameter 1:
- ORIGINAL_SQL_ID (required)
- Enter value for 1: aak402j1r6zy3
- Parameter 2:
- MODIFIED_SQL_ID (required)
- Enter value for 2: 6rbnw92d7djwk
- PLAN_HASH_VALUE AVG_ET_SECS
- -------------------- --------------------
- 313848035 .001
- Parameter 3:
- PLAN_HASH_VALUE (required)
- Enter value for 3: 313848035
- Values passed to coe_load_sql_profile:
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- ORIGINAL_SQL_ID: "aak402j1r6zy3"
- MODIFIED_SQL_ID: "6rbnw92d7djwk"
- PLAN_HASH_VALUE: "313848035"
- …
再次執(zhí)行原始語句,可以看到,綁定執(zhí)行計劃成功,已經走了索引和NESTED LOOPS。
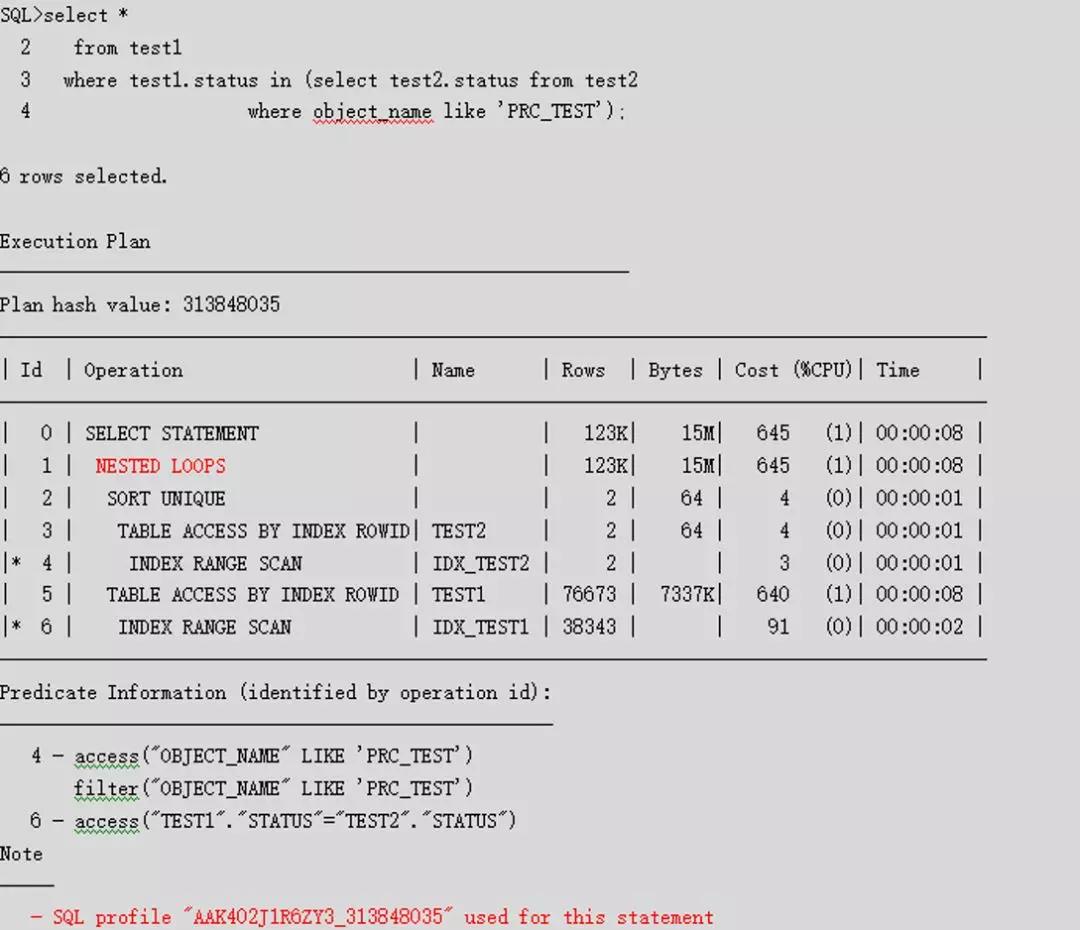
SQLT的快速綁定執(zhí)行計劃,在處理突發(fā)SQL性能問題中使用廣泛,的確是一個非常好的工具,猶如寶劍出鞘,削鐵如泥。
3、XPLORE快速診斷參數(shù)設置問題
某天晚上某系統(tǒng)一重要語句,遷移到新庫后執(zhí)行1小時都沒有結果,原先很快(1s左右),業(yè)務人員焦急萬分。對應的語句如下:
- SELECT
- *
- FROM (SELECT A.ID, A.TEL_ID, A.PRE_CATE_ID, A.INSERT_TIME, A.REMARK1
- FROM TAB_BN_TEST_LOG A,
- (SELECT TEL_ID, MIN(INSERT_TIME) AS INSERT_TIME
- FROM TAB_BN_TEST_LOG
- WHERE INSERT_TIME > '08-APR-19'
- AND ID NOT IN
- (SELECT IMEI FROM TX_MM_LOG_201907 WHERE TID = '10')
- GROUP BY TEL_ID) B
- WHERE A.TEL_ID = B.TEL_ID
- AND A.INSERT_TIME = B.INSERT_TIME
- AND A.ID NOT IN
- (SELECT IMEI FROM TX_MM_LOG_201907 WHERE TID = '10')
- ORDER BY INSERT_TIME)
- WHERE ROWNUM < 200
查看執(zhí)行計劃:
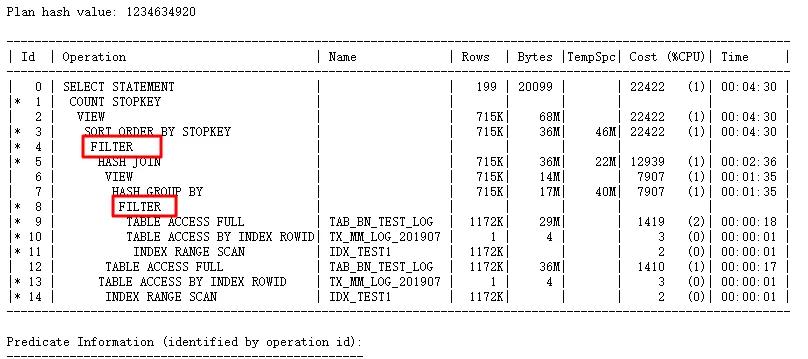
執(zhí)行計劃中出現(xiàn)FILTER,也就是子查詢無法unnest,由于使用的是NOT IN,但是回頭一想,這是11g,有null aware特性,應該不會出現(xiàn)FILTER才對,而且使用hints也無效。那么首先想到的就是檢查null aware參數(shù)是否設置,經過檢查:
完全沒有問題,那么在收集統(tǒng)計信息、SQL PROFILE、可以想到的參數(shù)設置都沒有問題情況下,如何解決呢?
由于查詢轉換受眾多參數(shù)設置影響,雖然null aware已經開啟,但是可能受其它參數(shù)或fix control設置影響,因此,這里可以使用SQLT的神器XPLORE分析,它會將已知參數(shù)、已知bug對應的fix control逐一重新設置一遍,然后生成對應的執(zhí)行計劃,最后生成一個html文件,通過查看執(zhí)行計劃,找到對應的參數(shù)或者BUG。
SQLT XPLORE中有XEXCUTE、XPLAIN等眾多方法,對于慢的語句,建議使用XPLAIN方法。然后查看分析結果與目標計劃匹配的設置,從而找出問題。
使用XPLORE,可以參考sqlt/utl/xplore中的readme.txt。這里需要將對應的SQL內容里加上:/* ^^unique_id */。
最終,生成的XPLORE文件內容如下:
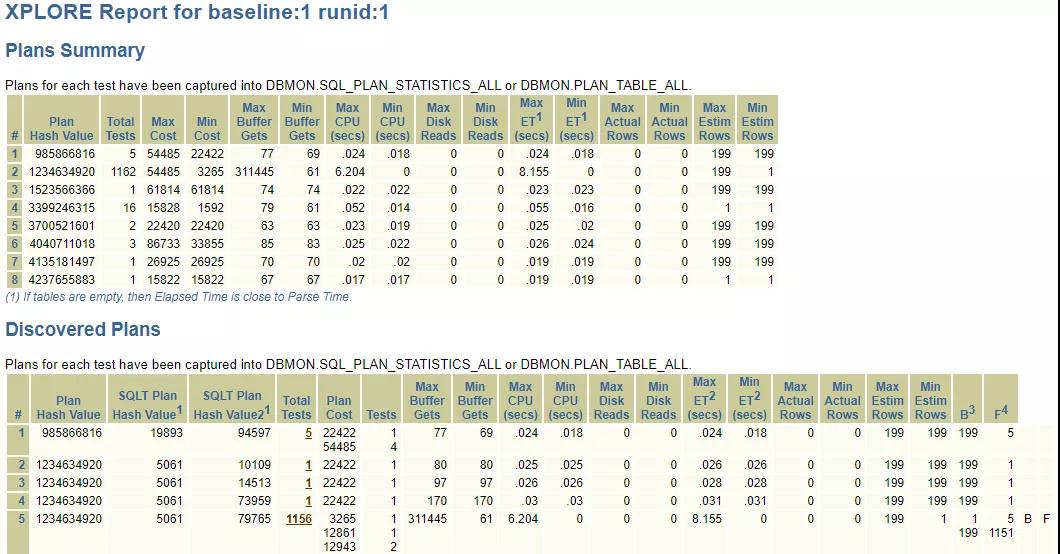
有8個執(zhí)行計劃的PLAN_HASH_VALUE,對應的點進去,找到正確的執(zhí)行計劃對應的參數(shù)設置:

最終找到,原來和_optimizer_squ_bottomup參數(shù)有關,這個參數(shù),系統(tǒng)設置成FALSE,導致此子查詢無法進行null aware查詢轉換,重新設置后語句執(zhí)行恢復到正常時間。
針對這樣的情況,如果一個個參數(shù)去對比分析,必然耗時很長,使用SQLT的XPLORE神器,可以快速找到對應的參數(shù)設置或已知BUG問題,比如一些新特性導致的SQL性能問題、SQL產生錯誤的結果等,都可以通過XPLORE分析,快速找到對應的參數(shù),然后重新設置。
最后做個總結:SQLT里還有很多其他的功能,可以通過MOS查看對應的文章,SQLT在解決棘手的SQL性能問題時,的確是一把利器,猶如寶劍出鞘,SQL性能問題無所遁形。










