不改造HBase就能應對復雜查詢場景?這個索引組件亮了
在各行各業紛紛結合自身需求,加快自主改造和研發腳步的當下,涌現出許多值得學習借鑒的優秀項目。本期將詳述光大銀行首個獨立研發的基礎軟件Pharos,如何從HBase二級索引出發,提升多條件復雜查詢的性能,拓展HBase的數據使用模式,應對海量數據低延時復雜查詢。
自研背景
可插拔的HBase索引組件
NoSQL興起無疑是大數據時代的標志性事件,創新者們不斷打破關系型數據庫“一種存儲模式解決所有問題”的思路,發明了很多不同的產品應對細分的數據訪問模式,它們提供了更好的服務特性,比如低延時、高并發等等。HBase是其中極具代表性的產品,作為Hadoop生態體系的明星產品,時至今日已在很多企業得到廣泛應用。
NoSQL這種為特定的數據使用模式設計存儲系統的思路,收獲了性能的大幅提升,但隨著存儲數據量的激增,對解決方案整體性價比的滿意度卻在不斷走低。畢竟,相較幾個TB和數百TB,存儲成本對用戶的沖擊力是不同的,人們總是不滿于線性增長的成本,希望能花更少的錢做更多的事。
通過適度拓展數據訪問模式提升性價比,成為業內很多技術方案追求的目標。
光大銀行是金融行業中較早引入HBase的,經過若干年建設已經積累了大量數據。如果僅是為了滿足不同條件的查詢,就copy一個同等規模的集群,是各方都難以接受的。
HBase作為一種KV數據庫,數據訪問模式以主鍵為核心,當面對非主鍵查詢時,其原生解決方案Filter無法滿足大多數聯機應用的性能需求。所以,很多基于HBase的二級索引方案都在嘗試應對復雜查詢場景的需求。
Pharos是基于HBase的技術中間件,研究起點同樣是二級索引,致力于提升多條件復雜查詢的性能,應用在海量數據低延時復雜查詢場景。
構建思路
三種二級索引方案的選型與分析
在啟動研發工作前,我們對現存的二級索引方案進行了分析,除原生Filter外大致可以分為三種。
Elastic Search + HBase
這個方案流行度最高,在ES中存儲索引信息,HBase存儲數據本身,兩者協同完成索引查詢。方案的優點是組合成熟產品,實施難度低;但缺點也有很多,首先是整體架構復雜、設備投入增加、運維成本高;其次是性能相對較低,每一次索引查詢,都要先訪問ES獲得匹配的索引后,再訪問HBase讀取數據內容,查詢鏈路延長,帶來更多的網絡開銷;最后是開發技能要求較高,程序員必須熟悉ES和HBase兩種產品接口。
Phoenix
Phoenix無疑是一款優秀的開源產品,產品的理念是Put the SQL back in NoSQL。產品成熟,Apache社區背書,都是該方案的優勢。
但因為目標高遠,Phoenix的體量也偏重,這樣在沒有商業廠商支持下,運維難度很高(2019年Cloudera宣布支持Phoenix后,可能會有所改善)。第二點,對SQL的支持成為它的核心目標,但在很多查詢場景中,SQL并非不可替代,高性能才是首要目標,性能卻是Phoenix尚待改進的地方。Phoenix在整體機制上,并沒有實現完善的索引下推,很多情況下索引查詢需要從客戶端發起兩次與服務端的交互,第一次獲得匹配的索引信息,第二次才是匹配的數據,這無疑帶來了性能損耗。
云廠商方案
在云計算時代,HBase已經成為云服務的標配,部分公有云也提供了二級索引功能。這個方案的優點當然是廠商的一站式服務,運維成本極低。缺點首先是部分企業因為安全因素無法使用公有云,例如金融行業;其次在于技術方案本身,例如阿里的HBase二級索引,其內核依然是Elastic與HBase的組合,雖然接口上進行封裝降低了開發難度,但架構帶來的性能損耗依舊存在。
通過上述的分析,我們發現這些方案都不能滿足光大銀行的應用場景,因此我們決定自研產品。
我們將產品命名為Pharos,源自英文單詞 [Pharos],其含義是燈塔。這個名稱有兩層含義:
- 第一層是詞義本身,燈塔對夜行的船只進行指引保證其安全地出入港口。而索引指向符合條件的數據地址,用于提升每次查數據訪問操作的效率,兩者有神似之處;
- 第二層含義,Pharos最初是指代亞歷山大燈塔,這也是世界上第一座燈塔。而Pharos是光大銀行首次嘗試自研基礎產品,我們希望這個命名能夠激勵團隊,做出有開創意義的產品。
設計目標
低延時,架構簡單,非侵入性
在Pharos設計目標中最重要的有三點:
- 低延時:我們希望未來Pharos的應用場景不僅限于數據查詢分析,也能夠嵌入到業務交易系統中,這樣低延時就是一個剛性需求;
- 架構簡單:這樣開發人員可以很容易上手使用,而運維的成本也很低;
- 非侵入性:是指對HBase的侵入,事實上除了前述分析的二級索引方案外,還有一些小眾的二級索引方案是直接對HBase進行改造,但這種侵入式改造帶來了后續的版本維護問題,考慮到多數企業不可能維護獨立的HBase版本分支,我們的方案直接排除了這種技術路線,必須是對HBase非侵入的。
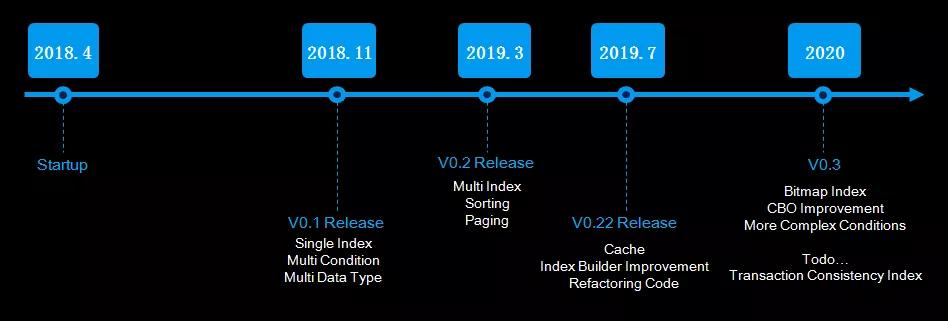
Pharos的研發是從2018年開始的,相對于目前的產品成熟度來說研發過程顯得有點長,主要原因是開發人力投入相對較小。我們希望隨著產品的應用推廣,能擴充人員,加快產品的演進速度。
研發過程,我們受到了很多同類產品的啟發,包括Phoenix、華為與360等公司的二級索引方案,也借鑒了很多好的設計方法,這里要特別致敬一下。
設計要點
四大關鍵設計的權衡
前面講了Pharos的外部特性,接下來我會著重講一些關鍵設計時的tradeoff,希望對大家的研發工作有所幫助。
存儲策略
HBase是沒有索引概念的,我們首先要解決的是如何存儲索引。
Pharos采用的方式是在數據表增加一個“獨立列族”用于存儲索引信息,利用列族對應獨立文件的特點,形成獨立的索引文件,不會直接受到原始數據量的影響,降低磁盤I/O開銷。這個設計另一個好處在于,索引與數據同分布,不必干預HBase的Region分布策略。后續的所有設計都是在同Region基礎上,這大大簡化了實現的復雜度。
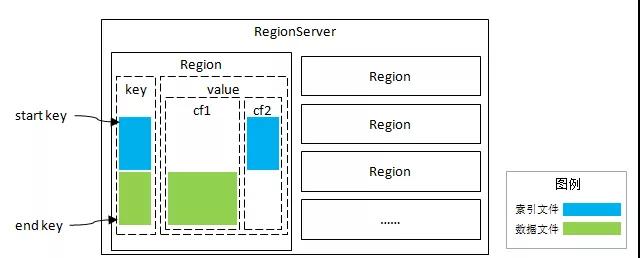
這種索引與數據同分布的模式,可以簡稱為“分區索引”;而索引與數據各自存儲的方式,則成為“全局索引”。“全局索引”的缺點在于無法完成索引查詢的下推,優點是可以進行全局控制,例如唯一索引。選擇“分區索引”是因為我們期望實現低延時目標,當然同時也就放棄了對“唯一索引”的支持,至少目前是不支持的。
存儲模型
索引記錄的Key部分,最開始是Region頭信息,保證與數據的同分布,而后是被索引字段的信息,接下來是存儲索引名稱等信息,數據記錄的Key則被拼接為尾部信息;value部分則存儲反序列化的元數據。
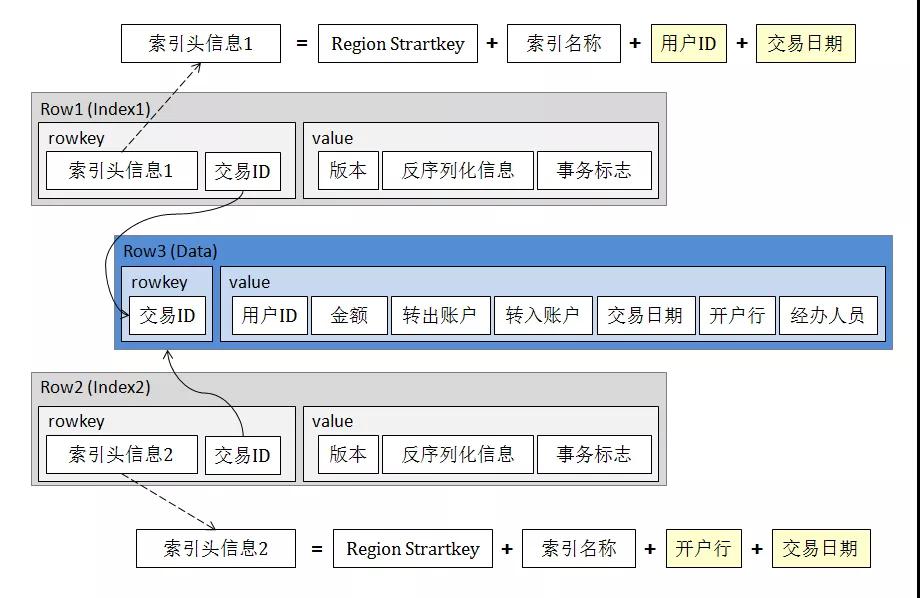
可以看到,這樣設計的優點是索引檢索速度快,存儲成本也比較小。所以,當查詢條件較復雜需要建立多個索引時,整體存儲成本依然是可接受的。
分頁機制
傳統的后臺分頁方法是由應用服務記錄每頁的末尾記錄主鍵,這個主鍵通常是由數據庫提供的row number,數據庫本身并不感知分頁動作。對于分布式存儲的HBase,每個Region都可能存在分頁斷點,如果延續該思路,應用端要記錄大量斷點信息,不僅增加傳輸數據量,也增大了開發的難度。在Pharos的設計中,我們通過Client作為匯聚點,緩存每個Region的斷點信息,在Pharos的Client中增加Session概念,應用端僅需持有Session ID即可順利完成翻頁操作。

索引與數據的事務一致性(實驗版本)
根據Pharos的存儲設計,我們可以知道索引實質上是與數據行前綴相同的另一行記錄,保證索引與數據的一致性要使用跨行事務,但HBase本身不支持跨表、跨行事務,這就成為一個死結,也是幾乎所有二級索引方案都不支持索引事務一致性的原因。
這個問題的解決比較復雜,所以我們先簡單介紹下HBase內部機制。HBase采用LSM-Tree模型,在聯機寫入時,數據在日志和內存中各保留一份,兩者通過MVCC與日志的協調機制可以保證事務一致性。我畫了一張圖來表示HBase 1.2.6的事務控制邏輯,具體如下:
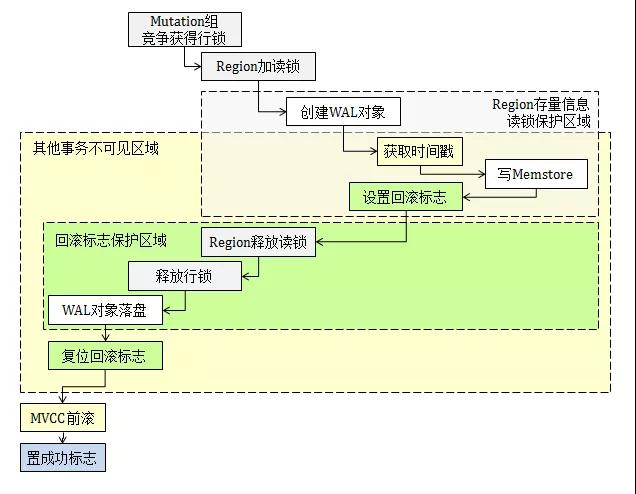
HBase內部會監控WAL的異常,但在Coprocessor事件體系中并未開“回滾標志位”,第三方開發者也就無法回滾相關數據行。
按說,到這里問題已經無解了,不過某天恰好受到了Percolator事務模型的啟發,找到了另一種解決問題的思路。既然無法在寫入過程通過回滾控制異常情況,那我們可以延后在讀取過程中來補充對異常的操作,也就是說在下一次查詢操作中再次確認并維護索引的一致性。
具體處理過程是,在首次寫入索引信息時,置事務標志位為“不確定”,數據行更新完成后,將該標志改為“成功”;如果出現回滾,則標志位保留“不確定”狀態。查詢操作中一旦發現“不確定”標志,則根據索引查找相應的數據行是否存在,如存在,則將該標志更新為“成功”。
我們用流程圖來體現處理過程,如下圖:
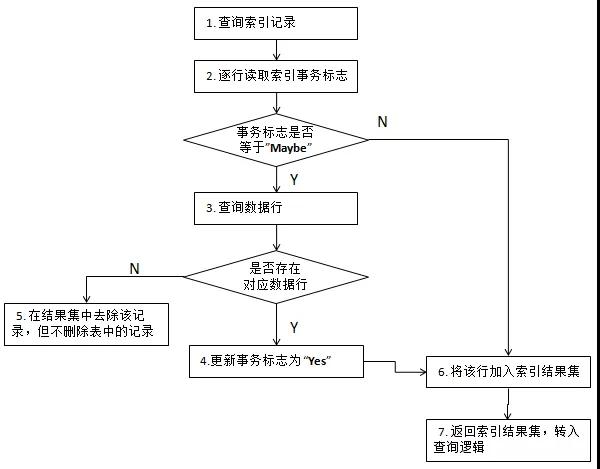
該方式付出的代價是寫入時需要兩次更新事務標志,相對于僅寫入數據行(無索引)肯定增加了一些開銷,在測試環境下我們發現損耗在15%左右,主要是指延時;在查詢環節雖然存在確認索引事務的可能性,但因為其發生的概率極低,不會對查詢產生實質性影響。
未來展望
徹底解決Region分裂問題
目前Pharos主要還是在內部使用場景中測試,收集需求和問題,近期我們會發布V0.3版本。新版本會推出一些讓人激動的特性,主要仍是圍繞查詢性能的提升,推出Pharos自有的數據組織形式,提供更加豐富的查詢加速手段,完成從二級索引組件到一個完整的技術中間件的演進。
其中,特別重要的一點是徹底解決了Region分裂問題,我要迫不及待地做個劇透。
Region分裂是HBase數據再平衡的手段,保證每個數據節點上的數據量分布大致平均,也會有一些打散熱點的效果。但是,分裂機制卻破壞了索引與數據的同分布,在同類方案中通常采用很重的更新操作來調整索引的位置,追隨數據的分布情況。
這種方式顯得過于笨拙,并且更新過程會影響整體方案的可用性。因此,Pharos在V0.22版本中是建議索引延后加載,這樣在數據更新導致的重分布完成后再更新索引。
實際操作中,這種方式要重復讀取數據文件,延長了整體數據加載周期,對運維操作來說不夠友好。在V0.3中,我們加入了Pharos自有的數據組織方式,實現在Region分裂時維持索引的同分布效果。
作者介紹
王磊(Ivan),光大銀行科技部數據領域架構師,曾任職于IBM全球咨詢服務部從事技術咨詢工作,具有十余年數據領域研發及咨詢經驗。目前負責全行數據領域系統的日常架構管理、重點系統架構設計及內部研發等工作,對分布式數據庫、Hadoop等基礎架構研究有濃厚興趣。
本文轉載自微信公眾號「DBAplus社群」,可以通過以下二維碼關注。轉載本文請聯系DBAplus社群公眾號。