2D變3D,視角隨意換,神還原高清立體感
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
看到這張恐龍化石的動(dòng)態(tài)圖片,你肯定會(huì)認(rèn)為是用視頻截出來的吧?

然而真相卻是——完全由靜態(tài)圖片生成!
沒錯(cuò),而且還是不用3D建模的那種。
這就是來自伯克利大學(xué)和谷歌的最新研究:NeRF,只需要輸入少量靜態(tài)圖片,就能做到多視角的逼真3D效果。

還需要專門說明的是,這項(xiàng)研究的代碼和數(shù)據(jù),也都已經(jīng)開源。
你有想法,盡情一試~
靜態(tài)圖片,合成逼真3D效果
我們先來看下NeRF,在合成數(shù)據(jù)集(synthetic dataset)上的效果。

可以看到,這些生成的對(duì)象,無論旋轉(zhuǎn)到哪個(gè)角度,光照、陰影甚至物體表面上的細(xì)節(jié),都十分逼真。
就仿佛是拿了一臺(tái)錄影設(shè)備,繞著物體一周錄了視頻一樣。
正所謂沒有對(duì)比就沒有傷害,下面便是NeRF分別與SRN、LLFF和Neural Volumes三個(gè)方法的效果比較。

不難看出,作為對(duì)比的三種方法,或多或少的在不同角度出現(xiàn)了模糊的情況。
而NeRF可謂是做到了360度無死角高清效果。
接下來是NeRF的視點(diǎn)相關(guān) (View-Dependent)結(jié)果。
通過固定攝像機(jī)的視點(diǎn),改變被查詢的觀看方向,將視點(diǎn)相關(guān)的外觀編碼在NeRF表示中可視化。


NeRF還能夠在復(fù)雜的遮擋下,展現(xiàn)場(chǎng)景中詳細(xì)的幾何體。


還可以在現(xiàn)實(shí)場(chǎng)景中,插入虛擬對(duì)象,并且無論是“近大遠(yuǎn)小”,還是遮擋效果,都比較逼真。

當(dāng)然,360度捕捉真實(shí)場(chǎng)景也不在話下。

神經(jīng)輻射場(chǎng)(neural radiance field)方法
這樣出色的效果,是如何實(shí)現(xiàn)的呢?
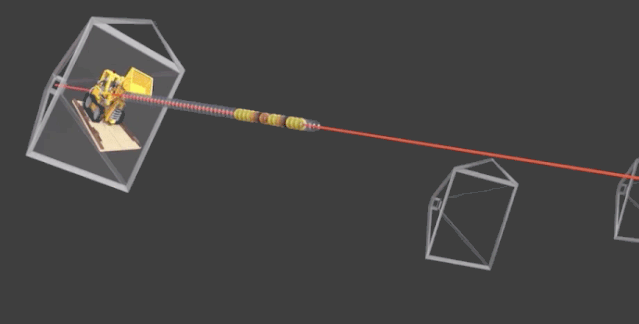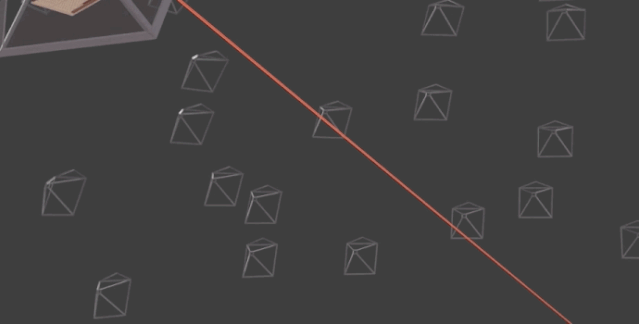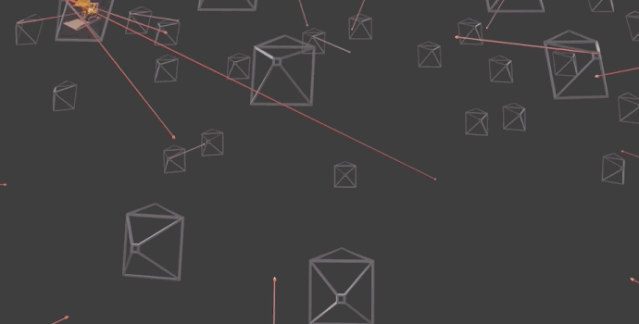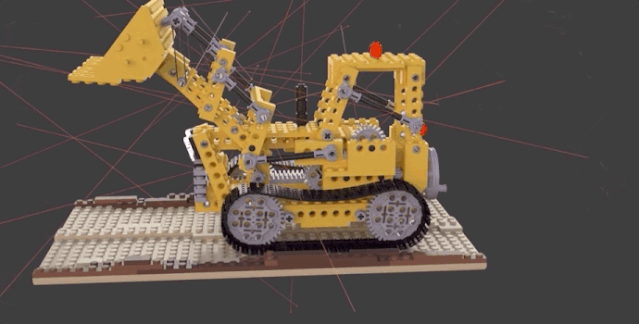
首先,是將場(chǎng)景的體積表示優(yōu)化為向量函數(shù),該函數(shù)由位置和視圖方向組成的連續(xù)5D坐標(biāo)定義。具體而言,是沿相機(jī)射線采樣5D坐標(biāo),來合成圖像。
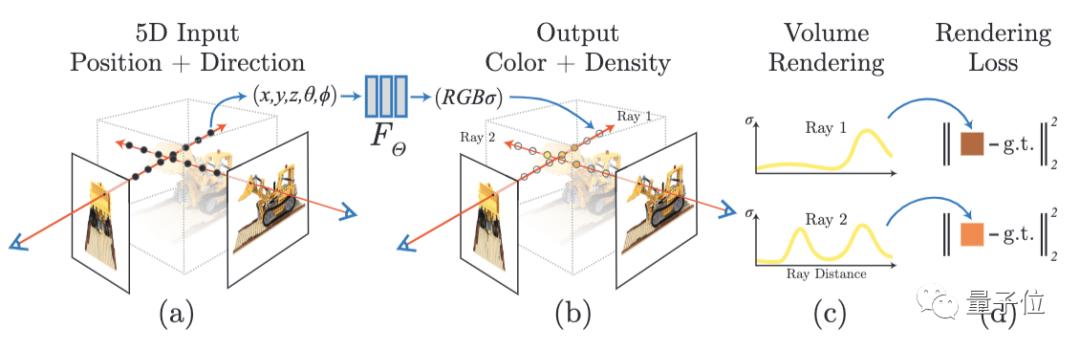
而后,將這樣的場(chǎng)景表示參數(shù)化為一個(gè)完全連接深度網(wǎng)絡(luò)(MLP),該網(wǎng)絡(luò)將通過5D坐標(biāo)信息,輸出對(duì)應(yīng)的顏色和體積密度值。
通過體積渲染技術(shù)將這些值合成為RGB圖像。
渲染函數(shù)是可微分的,所以可以通過最小化合成圖像和真實(shí)圖像之間的殘差,優(yōu)化場(chǎng)景表示。
需要進(jìn)一步說明的是,MLP使用8個(gè)完全連接層(ReLU激活,每層256個(gè)通道)處理輸入,輸出σ和256維特征向量。然后,將此特征向量與攝像機(jī)視角連接起來,傳遞到4個(gè)附加的全連接層(ReLU激活,每層128個(gè)通道),以輸出視點(diǎn)相關(guān)的RGB顏色。
NeRF輸出的RGB顏色也是空間位置x和視圖方向d的5D函數(shù)。

這樣做的好處可以通過對(duì)比來體現(xiàn)。可以看到,如果去掉視點(diǎn)相關(guān),模型將無法重現(xiàn)鏡面反射;如果去掉位置編碼,就會(huì)極大降低模型對(duì)高頻幾何形狀紋理的表現(xiàn)能力,導(dǎo)致渲染出的外觀過于平滑。
另外,針對(duì)高分辨率的復(fù)雜場(chǎng)景,研究人員還進(jìn)行了兩方面的改進(jìn)。
其一,是輸入坐標(biāo)的位置編碼,可以幫助MLP表示高頻函數(shù)。
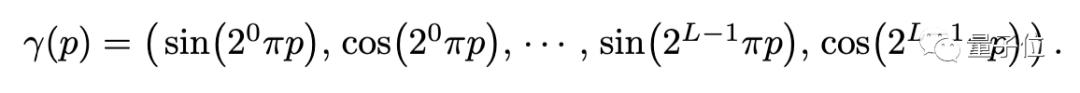
其二,是分層采樣。用以更高效地采樣高頻表示。
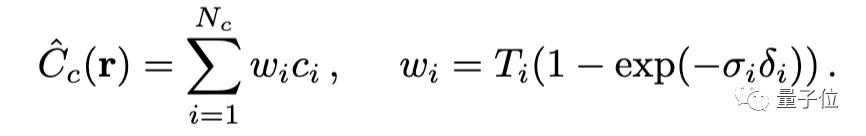
GitHub代碼開源
目前,NeRF項(xiàng)目的代碼已經(jīng)在GitHub上開源。
代碼主要基于Python 3,還需要準(zhǔn)備的一些庫(kù)和框架包括:TensorFlow 1.15、matplotlib、numpy、imageio、configargparse。
優(yōu)化一個(gè)NeRF
研究人員表示,優(yōu)化NeRF只需要一個(gè)GPU就可以完成,時(shí)間方面,需要花費(fèi)幾個(gè)小時(shí)到一兩天(取決于分辨率)。
而從優(yōu)化的NeRF渲染圖像,大約只需要1~30秒時(shí)間。
運(yùn)行如下代碼可以獲取生成Lego數(shù)據(jù)集和LLFF Fern數(shù)據(jù)集:
- bash download_example_data.sh
若想優(yōu)化一個(gè)低解析度的Fern NeRF:
- python run_nerf.py --config config_fern.txt
在經(jīng)過200次迭代之后,就可以得到如下效果:

若想優(yōu)化一個(gè)低解析度的Lego NeRF:
- python run_nerf.py --config config_lego.txt
在經(jīng)過200次迭代之后,就可以得到如下效果:

開始渲染
運(yùn)行如下代碼,為Fern數(shù)據(jù)集獲取經(jīng)過預(yù)訓(xùn)練的高分辨率NeRF。
- bash download_example_weights.sh
渲染代碼,在 render_demo.ipynb 中。
另外,你還可以將NeRF轉(zhuǎn)換為網(wǎng)格,像這樣:

具體示例,可以在 extract_mesh.ipynb 中找到。還需要準(zhǔn)備PyMCubes、trimesh和pyrender包。
關(guān)于作者:三位青年才俊
這篇論文的研究團(tuán)隊(duì),來自加州大學(xué)伯克利分校、谷歌研究院和加州大學(xué)圣地亞哥分校。
共同一作有三位。
Ben Mildenhall,本科畢業(yè)于斯坦福大學(xué),目前在伯克利電氣工程與計(jì)算機(jī)科學(xué)系(EECS)助理教授吳義仁(Ren Ng)門下讀博。致力于計(jì)算機(jī)視覺和圖形學(xué)研究。
Pratul P. Srinivasan,同樣為伯克利EECS在讀博士,師從吳義仁和Ravi Ramamoorthi。
Matthew Tancik,前面兩位作者的同門,本碩畢業(yè)于MIT。除了專注于計(jì)算機(jī)成像和計(jì)算機(jī)視覺研究外,他還是一位攝影愛好者。

1個(gè)GPU就能完成優(yōu)化,優(yōu)化后渲染又只需要1-30秒,如此方便又效率的項(xiàng)目,還不快來試試?
One More Thing
最后,還想介紹個(gè)這方面有意思的研究。
NeRF確實(shí)強(qiáng),但在輸入上還需要多張照片……
那么有沒有方法,一張圖片就能玩3D效果呢?
問就有。
之前,Adobe的實(shí)習(xí)生就提出了一個(gè)智能景深算法,單張2D圖片秒變3D。
讓我們感受下效果。

也是很有大片既視感了。
而最近,同樣是單張2D圖片變3D,臺(tái)灣清華大學(xué)的研究人員,在老照片上玩出了新花樣,論文入選CVPR 2020。
你看看女神奧黛麗·赫本,看看畢加索,看看馬克吐溫:

感覺以后看照片——搖一搖更有感覺啊。
再來看看“登月”、“宇航員和民眾握手”照片裸眼3D效果:

頗有點(diǎn)身臨其境之感。
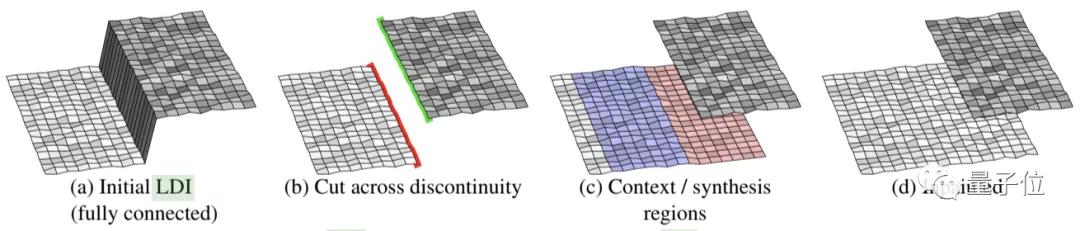
與此前介紹過的Adobe的算法(后臺(tái)加鏈接)類似,這一3D圖像分層深度修復(fù)技術(shù)的核心算法,同樣有關(guān)上下文感知修復(fù):
初始化并切割分層深度圖像(LDI),使其形成前景輪廓和背景輪廓,然后,僅針對(duì)邊緣的背景像素進(jìn)行修補(bǔ)。從邊緣“已知”側(cè)提取局部上下文區(qū)域,并在“未知”側(cè)生成合成區(qū)域(如下圖c所示)。
說起來,對(duì)于個(gè)人視頻制作者、游戲開發(fā)人員,以及缺乏3D建模經(jīng)驗(yàn)的動(dòng)畫公司來說,這類技術(shù)的成熟,可謂“福音”。
通過AI技術(shù),讓3D效果的實(shí)現(xiàn)進(jìn)一步簡(jiǎn)化,這也是Facebook、Adobe及微軟等公司紛紛投入這方面研究的原因所在。
最后,這個(gè)項(xiàng)目的代碼也開源了……
稿子還沒寫完,我就準(zhǔn)備好一系列“雪藏”已久的照片要試試了。
這也是最近看到最酷的3D圖片方面的突破了。
如果有更酷的,也歡迎留言分享~~
傳送門
項(xiàng)目主頁(yè):http://www.matthewtancik.com/nerfhttps://shihmengli.github.io/3D-Photo-Inpainting/
GitHub地址:https://github.com/bmild/nerfhttps://github.com/vt-vl-lab/3d-photo-inpainting