由淺到深學習Kafka:生產者消息分區機制原理
在使用Apache Kafka生產和消費消息的時候,肯定是希望能夠將數據均勻地分配到所有服務器上。
比如很多公司使用Kafka收集應用服務器的日志數據,這種數據都是很多的,特別是對于那種大批量機器組成的集群環境,每分鐘產生的日志量都能以GB數,因此如何將這么大的數據量均勻地分配到Kafka的各個Broker上,就成為一個非常重要的問題。
為什么分區?
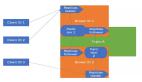
Topic的概念,它是承載真實數據的邏輯容器,而在主題之下還分為若干個分區,也就是說Kafka的消息組織方式實際上是三級結構:主題-分區-消息。主題下的每條消息只會保存在某一個分區中,而不會在多個分區中被保存多份。官網上的這張圖非常清晰地展示了。
Kafka的三級結構,如下所示:
看到了這張圖,我有幾個問題,為什么Kafka要做這樣的設計?為什么使用分區而不是直接使用多個Topic呢?
分區的作用
其實,分區的作用就是提供負載均衡的能力,或者說對數據進行分區的主要原因,就是為了實現系統的高伸縮性(Scalability)
不同的分區能夠被放置到不同節點的機器上,而數據的讀寫操作也都是針對分區這個粒度而進行的,這樣每個節點的機器都能獨立地執行各自分區的讀寫請求處理,并且,我們還可以通過添加新的節點機器來增加整體系統的吞吐量
實際上分區的概念以及分區數據庫早在1980年就已經有大牛們在做了,比如那時候有個叫Teradata的數據庫就引入了分區的概念
在不同的分布式系統對分區的叫法也不盡相同:比如在Kafka中叫分區,在MongoDB和Elasticsearch中就叫分片Shard,而在HBase中則叫Region,在Cassandra中又被稱作vnode
從表面看起來,它們實現原理可能不盡相同,但對底層分區(Partitioning)的整體思想卻從未改變
除了提供負載均衡這種最核心的功能之外,利用分區也可以實現其他一些業務級別的需求,比如實現業務級別的消息順序的問題
Kafka中的分區策略
Kafka中的分區策略,就是決定生產者將消息發送到哪個分區的算法
Kafka提供了默認的分區策略,同時,也支持自定義分區策略
- 默認分區策略
- 自定義分區策略
默認分區策略
- 輪詢策略(Round-robin)
- 隨機策略(Randomness)(已過時)
- 消息鍵策略(Key-ordering)
- 地理分區策略
輪詢策略
也稱Round-robin策略,即順序分配
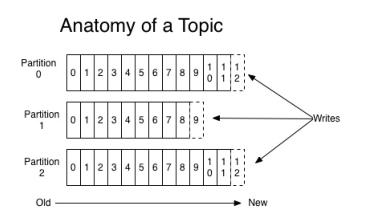
比如一個主題下有3個分區,那么第一條消息被發送到分區0,第二條被發送到分區1,第三條被發送到分區2,以此類推。當生產第4條消息時又會重新開始,即將其分配到分區0,如下圖所示
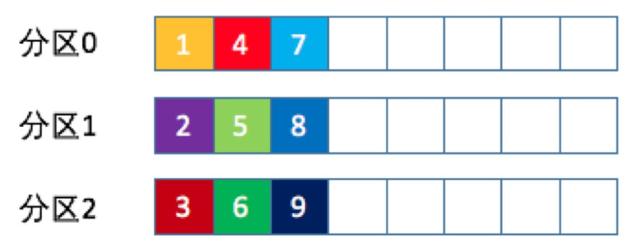
如果你未指定partitioner.class參數,那么你的生產者程序會按照輪詢的方式在Topic的所有分區間均勻地“存放”消息
輪詢策略有非常優秀的負載均衡表現,它總是能保證消息最大限度地被平均分配到所有分區上,默認情況下它是最合理的分區策略,也是我們最常用的分區策略之一
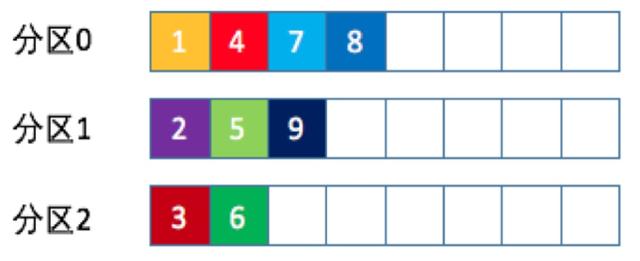
隨機策略
也稱Randomness策略,所謂隨機就是我們隨意地將消息放置到任意一個分區上,如下圖所示
如果要實現隨機策略版的partition方法,很簡單,只需要兩行代碼即可:
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- return ThreadLocalRandom.current().nextInt(partitions.size());
先計算出該Topic總的分區數,然后隨機地返回一個小于它的正整數
本質上看隨機策略也是力求將數據均勻地打散到各個分區,但從實際表現來看,它要遜于輪詢策略,所以如果追求數據的均勻分布,還是使用輪詢策略比較好
事實上,隨機策略是老版本生產者使用的分區策略,在新版本中已經改為輪詢了
消息鍵策略
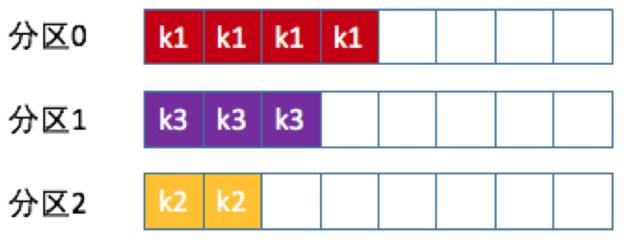
也稱Key-ordering策略,Kafka允許為每條消息定義消息鍵,簡稱為Key
這個Key的作用非常大,它可以是一個有著明確業務含義的字符串,比如客戶代碼、部門編號或是業務ID等;也可以用來表征消息元數據
特別是在Kafka不支持時間戳的年代,在一些場景中,工程師們都是直接將消息創建時間封裝進Key里面的
一旦消息被定義了Key,那么你就可以保證同一個Key的所有消息都進入到相同的分區里面,由于每個分區下的消息處理都是有順序的,故這個策略被稱為按消息鍵策略,如下圖所示
實現這個策略的partition方法同樣簡單,只需要下面兩行代碼即可:
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- return Math.abs(key.hashCode()) % partitions.size();
先計算出該Topic總的分區數,然后計算出key的hashCode與分區數取模的絕對值
Kafka在默認分區策略的選擇:如果指定了Key,那么默認實現按消息鍵策略;如果沒有指定Key,則使用輪詢策略
地理分區策略
上面這幾種分區策略都是比較基礎的策略,其實還有一種比較常見的,即所謂的基于地理位置的分區策略
當然這種策略一般只針對那些大規模的Kafka集群,特別是跨城市、跨國家甚至是跨大洲的集群
自定義分區策略
說完了默認分區,來說說自定義分區
Kafka中如果要自定義分區策略,你需要顯式地配置生產者端的參數partitioner.class
這個參數該怎么設定呢?方法很簡單,在編寫生產者程序時,你可以編寫一個具體的類實現org.apache.kafka.clients.producer.Partitioner接口
這個接口也很簡單,只定義了兩個方法:partition()和close(),通常你只需要實現最重要的partition方法,代碼如下所示
- /**
- * Compute the partition for the given record.
- *
- * @param topic The topic name
- * @param key The key to partition on (or null if no key)
- * @param keyBytes The serialized key to partition on( or null if no key)
- * @param value The value to partition on or null
- * @param valueBytes The serialized value to partition on or null
- * @param cluster The current cluster metadata
- */
- public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
- /**
- * This is called when partitioner is closed.
- */
- public void close();
這里的topic、key、keyBytes、value和valueBytes都屬于消息數據,cluster則是集群信息(比如當前Kafka集群共有多少主題、多少Broker等)
Kafka給你這么多信息,就是希望讓你能夠充分地利用這些信息對消息進行分區,計算出它要被發送到哪個分區中
只要你自己的實現類定義好了partition方法,同時設置partitioner.class參數為你自己實現類的Full Qualified Name,那么生產者程序就會按照你的代碼邏輯對消息進行分區
結語
今天學習了Kafka生產者消息分區的機制以及常見的幾種分區策略
分區是實現負載均衡以及高吞吐量的關鍵,故在生產者這一端就要仔細盤算合適的分區策略,避免造成消息數據的傾斜,使得某些分區成為性能瓶頸,這樣極易引發下游數據消費的性能下降