













用Kafka實現數字孿生的物聯網架構
譯文【51CTO.com快譯】數字孿生(Digital Twin)可以被理解為現實中某些事物(也包括過程或服務)在數字虛擬環境中的表現。在本文中,你將了解到數字孿生在各個行業中所處的優勢,以及Apache Kafka、物聯網架構和機器學習之間的關系。在實際應用中,Kafka通常被用作中央事件流平臺,以那些實時流傳感器的數據,構建可靠、且可擴展的數字孿生和數字線程。
我們將從如下三個方面來討論如何構建開放、且可擴展的數字孿生基礎架構:
- 數字孿生與數字線程。
- 事件流、數字孿生與AI(機器學習)之間的關系。
- 使用Apache Kafka和其他物聯網平臺的數字孿生物聯網架構。
建立數字孿生的關鍵要點
我們首先來了解四個基礎性的要點:
- 事件流是物聯網平臺和其他后端應用程序/數據庫的補充。
- 大多數數字孿生架構都使用機器學習(ML)和統計模型來進行仿真、預測和推薦。
- “數字孿生”一詞通常是指單個資產的副本。在現實世界中,各種數字孿生比比皆是。
- “數字線程”一詞涵蓋了一到多個數字孿生的整個生命周期(如下圖所示)。
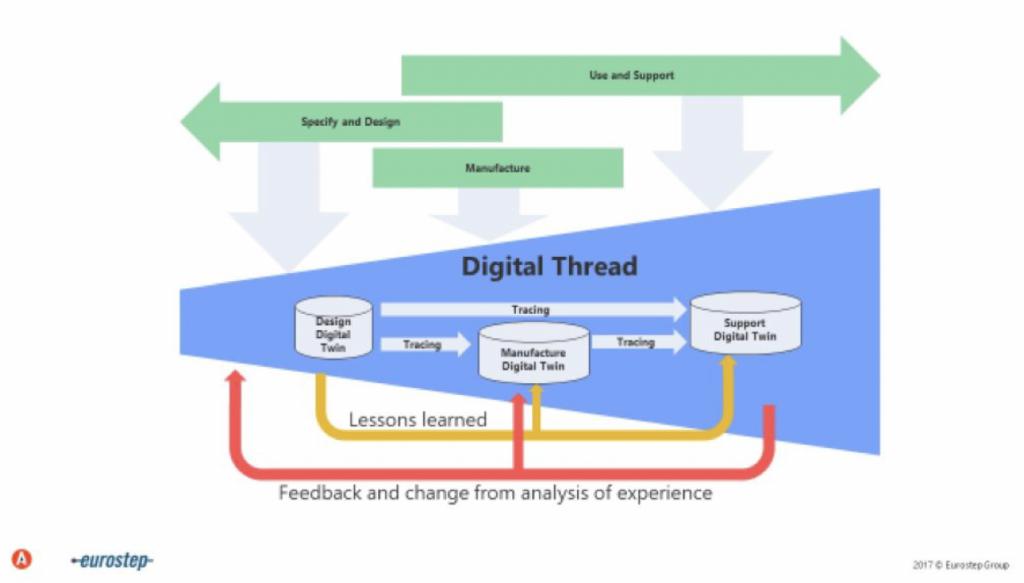
數字孿生可以被運用到許多行業和領域,其中包括:
- 減少宕機時間
- 庫存管理
- 車隊管理
- 假設(what-if)模擬
- 運營計劃
- 服務化
- 產品開發
- 衛生保健
- 客戶體驗
實際上,數字孿生不僅為各個行業帶來了自動化,而且增加了不同業務的價值和創新。
事件流、數字孿生與AI(機器學習)之間的關系
開發者需要通過機器學習,并運用數字孿生,來進行準確的預測。這兩者存在著互補的關系。下圖展示了不同的數字孿生如何利用統計方法和分析的模型:
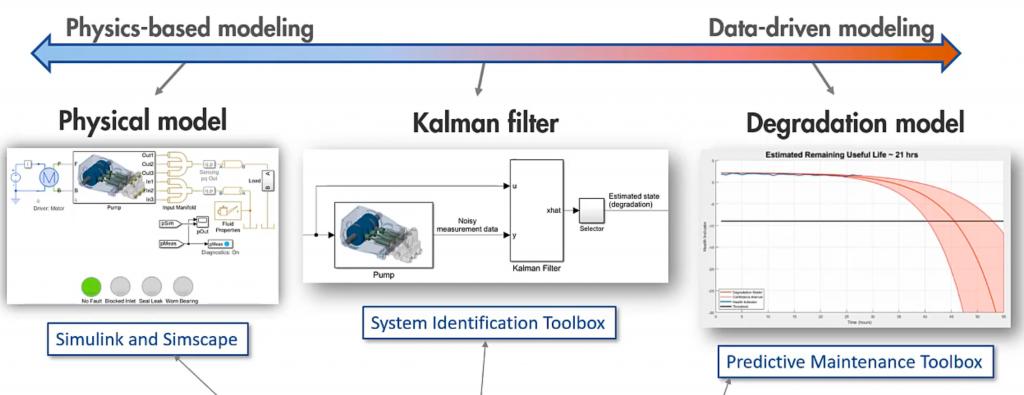
該示例包括了基于物理模型來模擬的各種假設情景,以及基于數據模型來估計剩余使用壽命(Remaining Useful Life,RUL)。可見,數字孿生和機器學習有著以下共同點:
- 能夠持續學習、監控與行動。
- 良好的數據源是成功的關鍵。
- 數據集越多越好。
- 實時性、可擴展性和可靠性是關鍵的需求。
使用Apache Kafka來實現數字孿生,機器學習和事件流
Apache Kafka開源生態系統為機器學習提供了基礎架構。下圖展示了Kafka針對機器學習的架構。該架構為模型的訓練、部署、評分和監視,提供了開放、可擴展、以及可靠性的實時處理。
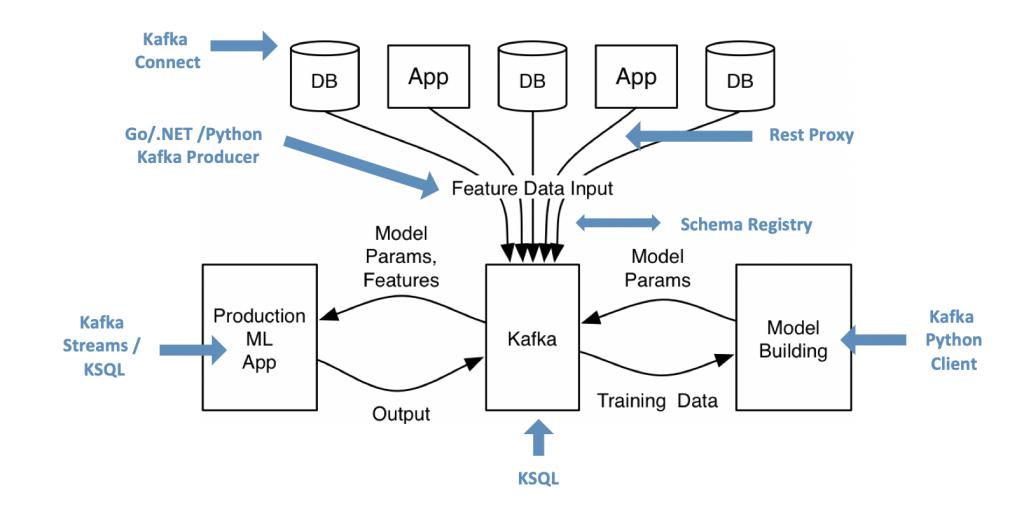
以下是數字孿生在實際應用過程中的五大常見特征:
連接性
- 各類實物資產、企業軟件與客戶。
- 通過雙向通信,以獲取命令和控制。
同態化(Homogenization)
- 解耦和標準化。
- 信息虛擬化。
- 能與多個代理共享,且不受物理位置或時間的限制。
- 成本更低,且能夠輕松地開展測試、開發和預測。
可重新編程與智能化
- 通過調整和改善特征,以開發出產品的新版本。
數字跟蹤
- 能夠實現時光倒流(回溯),并通過分析歷史事件,以診斷問題。
模塊化
- 能夠對產品和生產模塊進行設計和定制。
- 調整不同的模型和機器模塊。
為了實現上述特征,我們可以選用不同的物聯網平臺。根據物聯網分析研究(IoT Analytics Research)的統計:截止到2019年,市場上存在著600多個物聯網平臺(請參見:https://iot-analytics.com/iot-platform-companies-landscape-2020/)。與此同時,它們中的許多工具和解決方案都能夠結合在一起,共同發揮作用。
下面,我們來討論幾種典型的物聯網平臺:
- 以Siemens S7和Modbus為首的工業物聯網(IIoT)相關協議,以及與諸如OPC-UA之類標準的深度集成:它們往往并非某個單一的產品(通常是各種OEM的不同代碼庫)。雖然價格不菲,但是它們開放特定的接口,而且其可擴展性也十分有限。此類平臺的典型代表包括:西門子MindSphere、思科Kinetic、GE Digital和Predix。
- 云提供商的物聯網產品:它們提供了完備的物聯網管理工具,能夠與其他云服務(如:存儲、分析等)實現良好的集成。不過,它們往往被云提供商的平臺所綁定,且無法支持混合與邊緣計算。另外,它們不但擴展性有限,而且售價也不菲。此類平臺的典型代表包括:AWS、GCP、Azure和Alibaba等。
- 基于開放標準(如:MQTT)、且開源的物聯網平臺:它們能夠開放核心的業務模型,且與基礎架構無關。不過,它們在針對舊協議和專有協議的連接方面,可能不太成熟。此類平臺的典型代表包括:Eclipse IoT、Apache PLC4X、Node-RED等開源框架、以及符合MQTT等標準的HiveMQ相關產品。
使用Apache Kafka和其他物聯網平臺的數字孿生架構
下面,我們根據數字孿生的上述五大特征,來討論Kafka針對實時消息傳遞、集成與處理關鍵任務事件流等方面的作用:
- 連接性:Kafka Connect可以針對IoT接口、大數據解決方案、以及云服務,提供免費且實時的大規模連接。
- 同態化:Kafka實現了生產者和消費者之間真正的解耦。模式(schema)管理和實施可利用JSON Schema、Avro、Profobuf等不同技術,來實現數據的感知和標準化。
- 可重新編程與智能化:作為微服務架構的實際標準,Kafka支持:關注點分離(Separation of concerns),域驅動設計(domain-driven design,DDD,請參見:https://www.confluent.io/blog/microservices-apache-kafka-domain-driven-design/),部署新的已解耦應用,實施版本控制,A/B測試與發布。
- 數字跟蹤:作為分布式提交日志,Kafka會按需將事件永久地追加、存儲到您的時間點(永久保留時間可 = -1)。這非常適合為數字孿生構建數字跟蹤。
- 模塊化:Kafka基礎架構本身就是模塊化、且可擴展的,其中包括:Kafka brokers、Connect、Schema Registry、REST Proxy等組件、以及使用Java、Scala、Python、Go、.NET、以及C++等不同語言的客戶端應用。通過這種模塊化,您可以輕松地在邊緣、混合或全局場景中,構建合適的數字孿生架構,并能夠將Kafka組件與任何其他物聯網方案結合起來。
下面是五種適用于數字孿生的物聯網架構。您可以根據它們的優缺點,在自己的整體企業架構、項目情況、以及其他方面,做出合理的選擇。
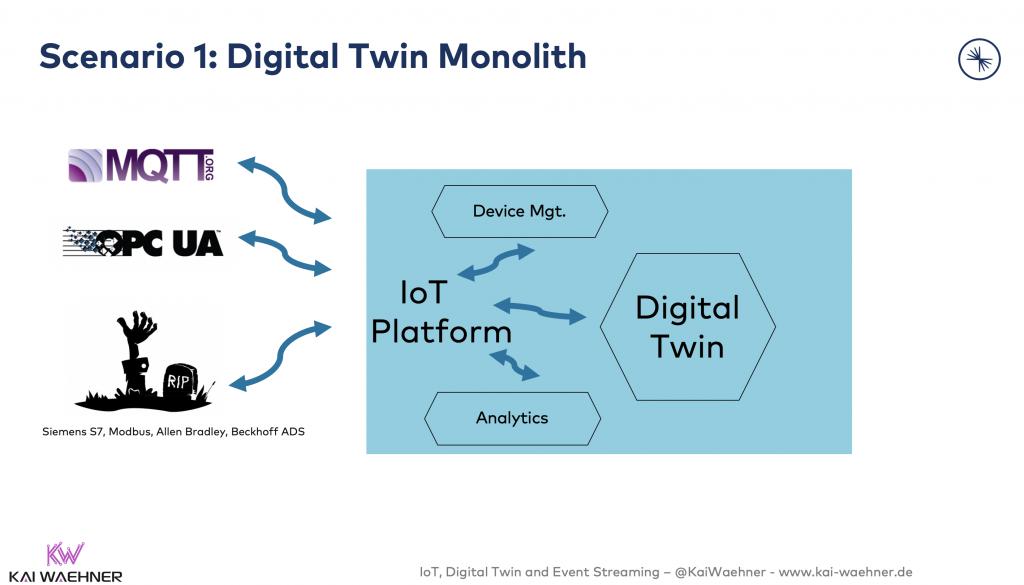
方案1:數字孿生Monolith
直接使用物聯網平臺來集成和構建數字孿生,無需其他數據庫或其他組件。
方案2:將數字孿生作為外部數據庫
物聯網平臺與其端點集成,數字孿生的數據被存儲在諸如:MongoDB、Elastic、InfluxDB或Cloud Storage之類的外部數據庫中。此類數據庫僅用于存儲,處理,以及儀表板分析等任務。
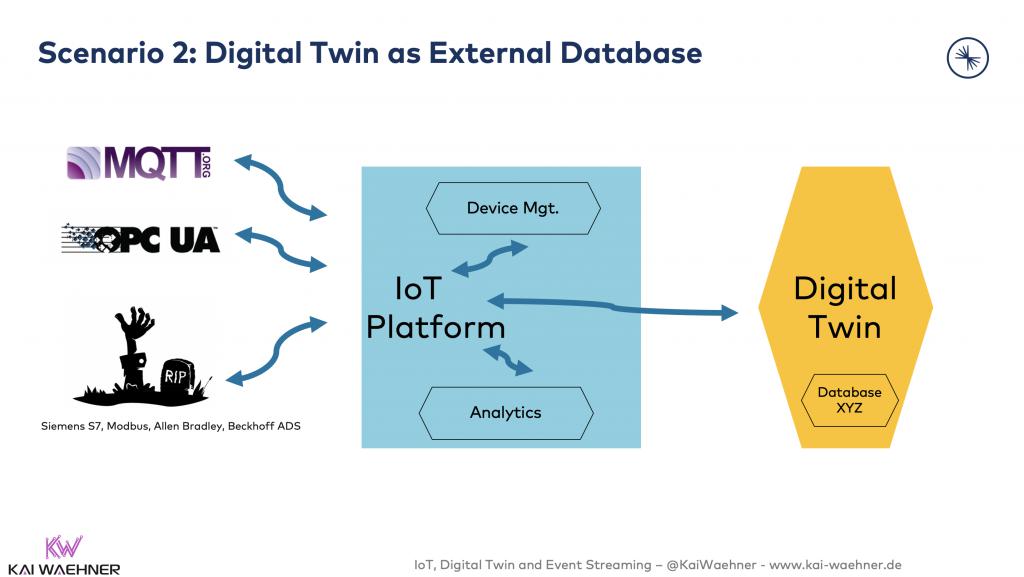
同時,Tableau、Qlik或Power BI之類的商業智能(BI)工具也可以使用數據庫的SQL接口,來實現交互式的查詢和報告。
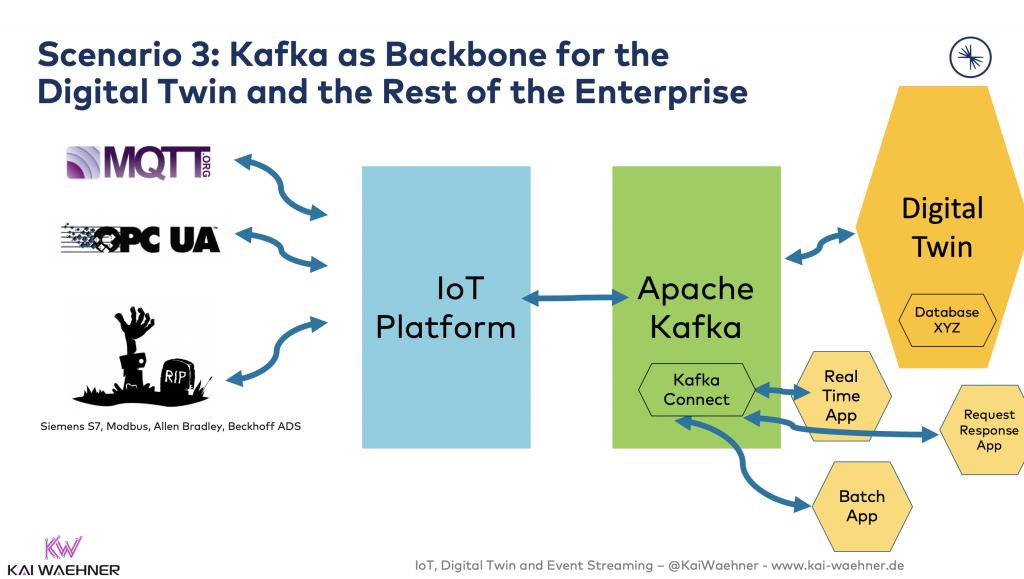
方案3:Kafka作為數字孿生和企業其余部分的主干
物聯網平臺仍然與其端點集成。Kafka作為中央事件流平臺,提供與其他組件之間的解耦。此處中央層是開放、可擴展且可靠的。而此處的數據庫同樣被用于數字孿生的存儲、以及儀表板分析。其他應用也會以實時、批處理、請求-響應通信等方式,使用來自Kafka的部分數據。
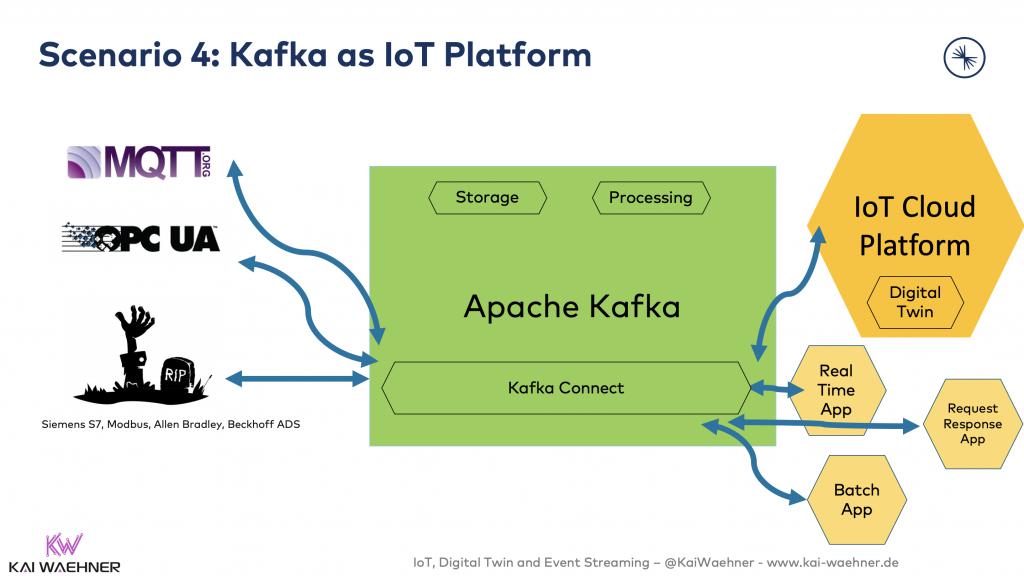
方案4:Kafka作為物聯網平臺
作為中央事件流平臺,Kafka可為物聯網端點和其他應用提供關鍵任務的實時架構和集成層。在此方案中,數字孿生并未用到上述方案中提到的數據庫,而是使用了Azure IoT Twin Twins之類的云端物聯網服務。
場景5:Kafka作為物聯網平臺
Kafka直接被用于實現數字孿生,而并不涉及到其他組件或數據庫。同時,其他消費者會直接使用原始數據和數字孿生的數據。
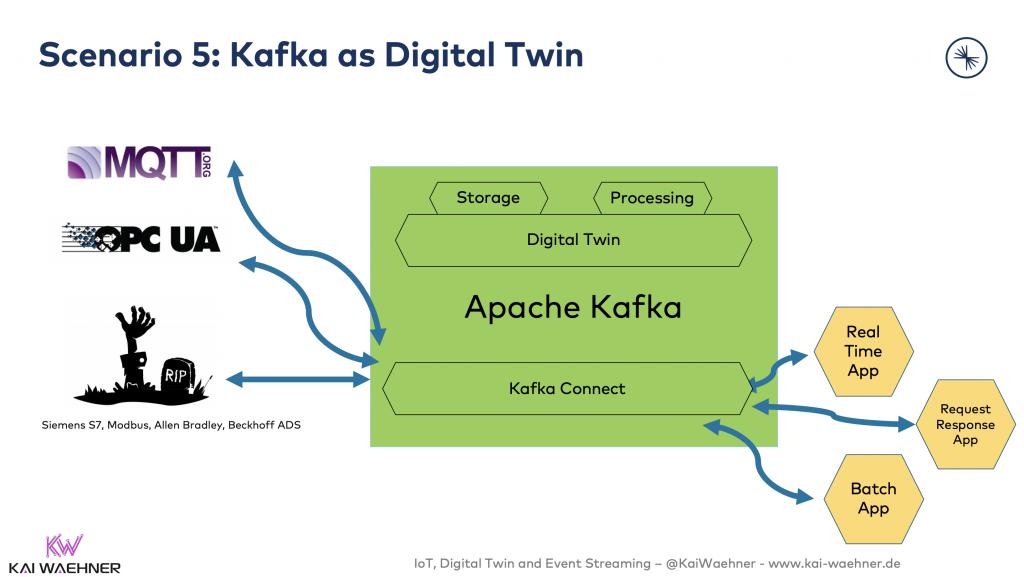
該方案的主要問題在于Kafka是否可以替換數據庫、以及如何查詢到數據(請參見:https://www.kai-waehner.de/blog/2020/03/12/can-apache-kafka-replace-database-acid-storage-transactions-sql-nosql-data-lake/)。在實際應用中,由于Kafka可以被用作數據庫,因此它不會替代諸如:Oracle、MongoDB或Elasticsearch等其他數據庫。
當然,Kafka的多次部署也可以被運用到數字孿生的架構中,在永久性存儲等方面發揮巨大的作用。
原文標題:IoT Architectures for Digital Twin With Apache Kafka,作者:Kai Wähner
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】





















