5種方法讓你知道Kubernetes集群的健康狀況
Kubernetes是一種非常智能的技術,但如果操作不當反而弄巧成拙。正如大多數智能化技術一樣,它的智能程度取決于操作者。為了建立成功的Kubernetes團隊,了解Kubernetes的健康狀況至關重要。這里有五種方法,可以讓工程師很好的識別出集群的潛在健康風險。
幸運的是,有一些現成的技術可以用來收集Kubernetes集群的日志、各種指標數據、事件和安全威脅,以幫助監視集群的健康狀況。這些收集器從Kubernetes集群的各個部分收集數據,然后對數據進行整合,從而生成可視化的高級視圖,并實時了解資源利用率,發現錯誤的配置和其他問題。
為所有的Pod設置CPU的使用上下限
在Kubernetes集群中,Pod的調度機制依賴于requests和limits這兩個參數。我們可以為CPU和內存設置requests和limits。對于CPU,它的單位是millicores,1000m等于一個CPU核。requests是你認為容器至少需要多少CPU和內存,而limits則是允許容器使用的實際上限。

確保為所有的Pod設置了CPU requests。最佳實踐是將其設置為一個CPU核或更少,如果需要更多的計算能力,則添加額外的Pod副本。需要注意的是,如果你的CPU requests過高,比如2000m,但是你只有1個CPU核可用,那么這個Pod將永遠不會被調度到Kubernetes集群中。在第5點中,我將向你展示如何檢查未被調度的Pod。
確保為所有的Pod設置了CPU limits。如上所述,這個參數限制了Pod使用CPU的上限,因此Kubernetes將不允許Pod使用比limits中定義的更多的CPU。也就是說,CPU是比較寬容的,因為它被認為是一種可壓縮資源。如果你的Pod達到了CPU limits,它不會被終止,而是被節流,因此可能會出現性能下降。
為所有的Pod設置內存的使用上下限

確保為所有的Pod設置了memory requests:memory requests是你認為容器至少需要多少內存。像CPU一樣,如果Pod的memory requests大于集群可以提供的內存,Kubernetes不會將Pod調度到Kubernetes集群中。
確保為所有的Pod設置了memory limits: memory limit是允許Pod使用內存的上限。與CPU不同,內存是不可壓縮的,也不能進行節流。如果容器超過了它的內存限制,那么它將被終止。
審計資源配置
檢查Kubernetes是否有不足或過剩的資源。如果Kubernetes集群中有剩余的可用CPU和內存,那么集群就處于消耗狀態,并且消耗可能會持續增長。另一方面,如果CPU和內存的利用率接近100%,那么當集群需要水平擴展或有大量請求到來時,集群可能會遇到問題。
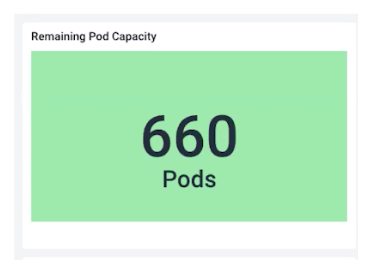
檢查Pod的剩余容量,在Kubernetes中有一個指標數據“kube_node_status_allocatable”,這是Kubernetes在給定平均Pod資源利用率的情況下,對一個節點能容納多少個Pod的估計。我們可以把剩余的Pod容量加起來,粗略地估計一下我們能在不遇到問題的情況下,集群還能擴大多少。
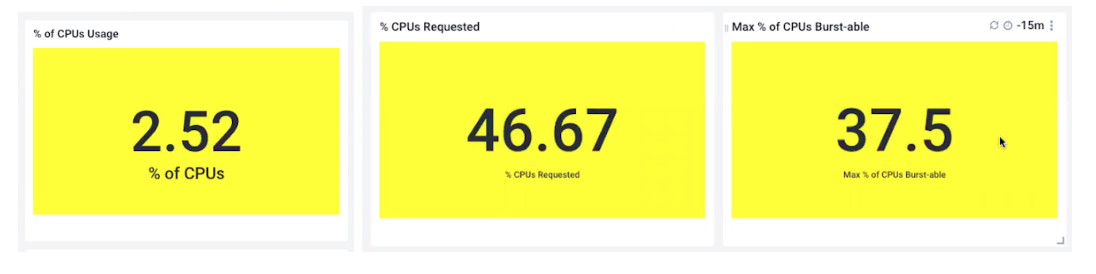
檢查CPU總百分比使用率,CPU requests百分比使用率,CPU limits百分比使用率:CPU總百分比使用率可以告訴你現在使用了多少。CPU requests百分比使用率可以告訴你應該需要多少。CPU limits百分比使用率限制了你可以使用多少。
在下面的例子中,我們只使用了可用計算能力的2.5%。我們的剩余資源過多。相比之下,我們定義的CPU requests是46%,所以我們認為Pod需要的比Pod實際使用的多得多。我們的預估不夠準確。
最后,我們的CPU limits總和是37%。由于這低于我們的CPU requests,這是一個錯誤的配置,我們需要重新檢查我們的CPU limits。
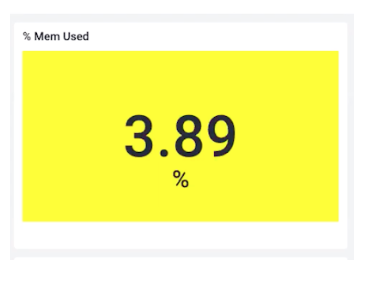
檢查內存的百分比使用率、memory requests百分比使用率,memory limits百分比使用率。就像CPU一樣,查看是否有過多的剩余資源。只有3.8%的使用率告訴我們,我們確實資源過剩,但我們可以安全的進行水平擴展。
檢查節點間的Pod分布
當我們查看Pod在集群中的分布情況時,我們希望得到一個大致均勻的分布。如果某些節點完全超載或負載不足,這可能是一個值得深入研究的問題。
以下是可能導致分布不均勻的一些事項:
- Node affinity,親和性是一種Pod設置,它使Pod更喜歡具有某些屬性的節點。例如,Pod可能需要在附加了GPU或SSD的節點上運行,或者Pod可能需要具有特定安全隔離或策略的節點。檢查親和性設置可以幫助分析不均勻分布的原因,并減少可能出現的問題。
Taints and tolerations,污點是親和性的反義詞。Pod不太喜歡被分配到這些被“污染”的節點上。如果你希望為特定的Pod保留節點,或者確保該節點上的Pod可以完全訪問可用資源,那么可以使用此方法。
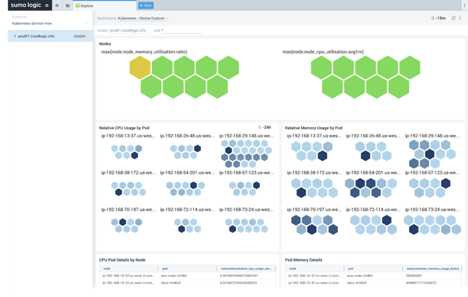
Limits and requests,查看limit和request的設置。這常常是Pod分布不均勻的原因,因此值得在本節的三個部分中提及。如果Kubernetes調度程序沒有Pod需要什么的正確信息,那么調度程序在調度方面就會做得很差。
檢查Pod是否處于不良狀態
在Kubernetes環境中,Pod的狀態時刻在變化,所以過度關注每一個被終止的Pod將會慢慢吞噬你的時間和理智。但是,下面的列表值得你關注,以確保達到期望的集群狀態。
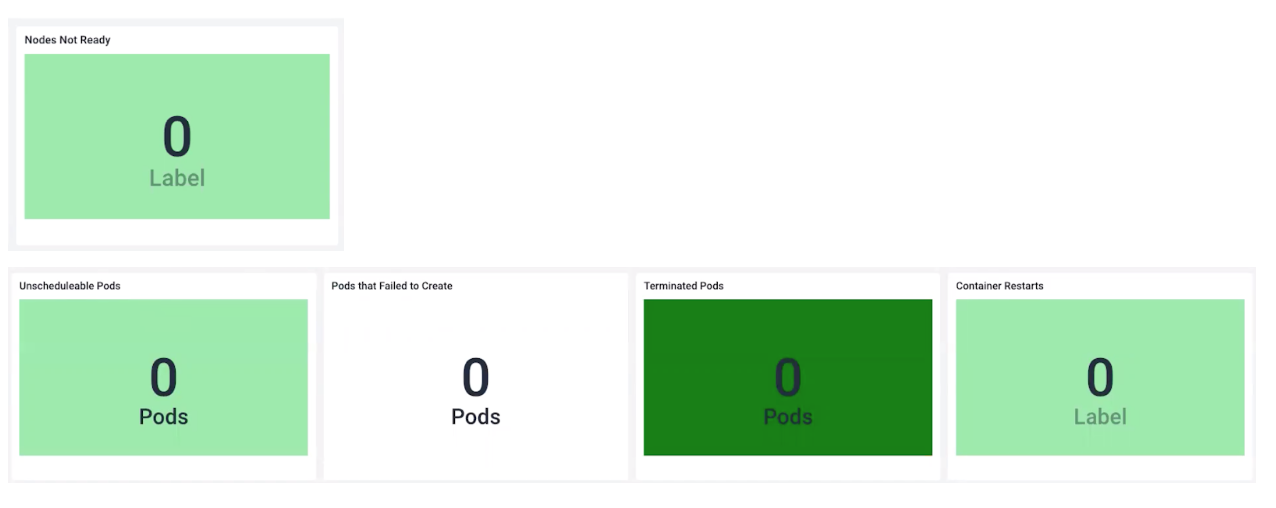
- Nodes not ready:節點可能由許多原因而陷入這種狀態,但通常是因為內存或磁盤空間不足。
- Unscheduled pods:Pod通常以未調度狀態結束,由于調度程序無法滿足Pod所需要的CPU或內存請求。檢查集群是否擁有足夠的可用資源。
- Pods that failed to create:Pod在創建時失敗,這通常是由于在Pod的啟動腳本中缺少某些依賴項之類的鏡像導致的。在這種情況下,回到起點,反復檢查Pod的各種參數配置。
Container restarts:一些容器重新啟動不值得關注,但是看到很多這樣的情況,可能意味著Pod處于OOMKill(內存耗盡)狀態。內存不足是Kubernetes集群中最常見的錯誤之一,可能是由鏡像問題、下游依賴項問題或各種意外、限制和請求問題引起的。
這些集群健康最佳實踐可以限制Kubernetes集群出現意外情況,并確保集群在擴展時不會遇到問題。還為你提供了一個很好的起點,以幫助你回答那些無定形的問題,如“我的Kubernetes集群是否健康?” 如果所有這些檢查點都是綠色的,那么你的集群可能處于健康狀態,你可以高枕無憂了。