大數(shù)據(jù)新人應(yīng)該了解的Hadoop中的各種文件格式
Hadoop文件格式初學(xué)者指南
幾周前,我寫了一篇有關(guān)Hadoop的文章,并談到了它的不同部分。 以及它如何在數(shù)據(jù)工程中扮演重要角色。 在本文中,我將總結(jié)Hadoop中不同的文件格式。 本主題將是一個簡短而快速的主題。 如果您想了解Hadoop的工作原理以及它在數(shù)據(jù)工程師中的重要作用,請在此處訪問我關(guān)于Hadoop的文章,或樂于跳過。
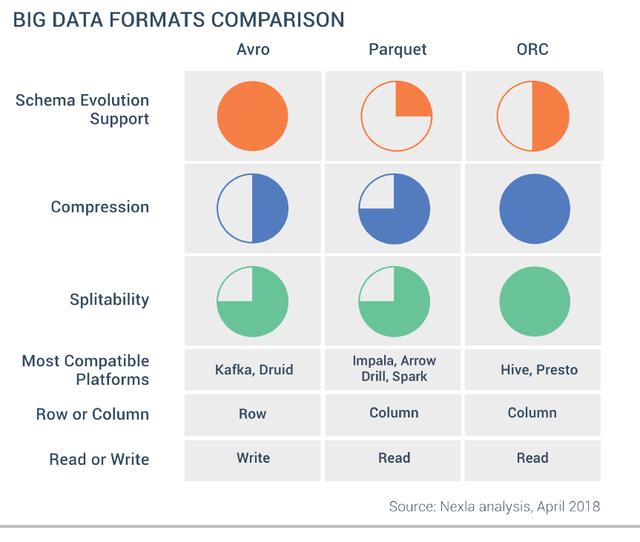
Hadoop中的文件格式大致分為兩類:面向行和面向列:
- 面向行:在一起存儲的同一行數(shù)據(jù)是連續(xù)存儲:SequenceFile,MapFile,Avro Datafile。 這樣,如果僅需要訪問該行的少量數(shù)據(jù),則需要將整個行讀入存儲器。 延遲序列化可以將問題減輕到一定程度,但是無法取消從磁盤讀取整行數(shù)據(jù)的開銷。 面向行的存儲適用于需要同時處理整行數(shù)據(jù)的情況。
- 面向列:整個文件分為幾列數(shù)據(jù),每列數(shù)據(jù)存儲在一起:Parquet,RCFile,ORCFile。 面向列的格式可以在讀取數(shù)據(jù)時跳過不需要的列,適用于字段中只有一小部分行的情況。 但是這種讀取和寫入格式需要更多的存儲空間,因為高速緩存行需要位于內(nèi)存中(以獲取多行中的一列)。 同時,它不適合流式傳輸,因為一旦寫入失敗,就無法恢復(fù)當(dāng)前文件,并且在寫入失敗時,面向行的數(shù)據(jù)可以重新同步到最后一個同步點,因此Flume使用 面向行的存儲格式。
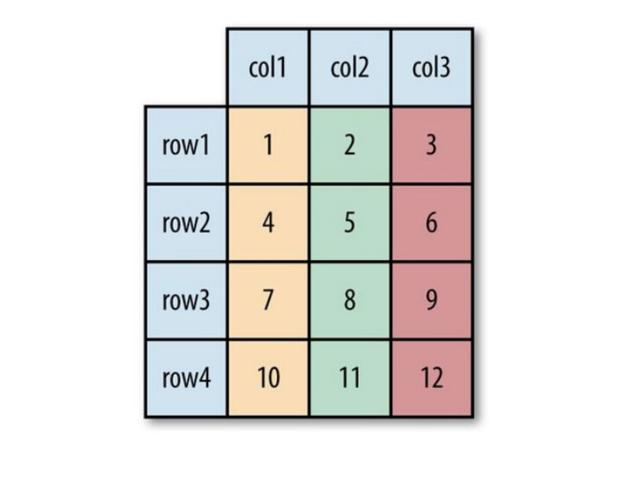

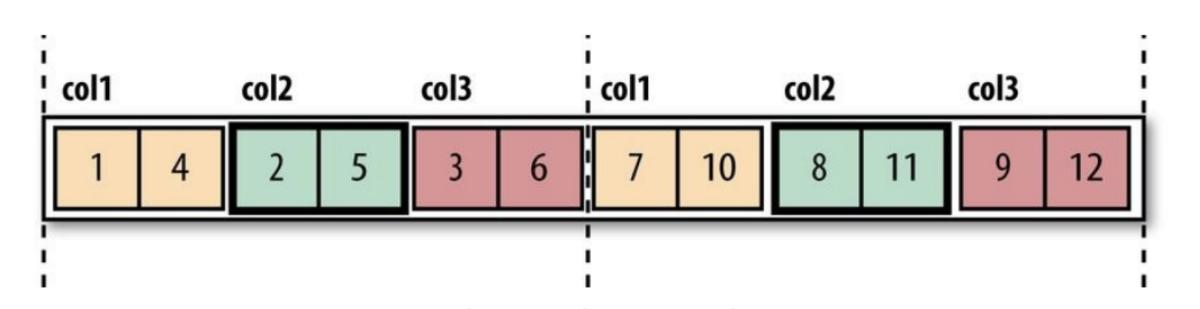
> Picture 1.(Left Side )Show the Logical Table and Picture 2. ( Right Side) Row-Oriented Layout(Sequ
> Picture 3. Column-oriented Layout (RC File)
如果仍不清楚行和列的方向,請不用擔(dān)心,您可以訪問此鏈接,了解它們之間的區(qū)別。
以下是在Hadoop系統(tǒng)上廣泛使用的一些相關(guān)文件格式:
序列文件
存儲格式取決于是否壓縮以及使用記錄壓縮還是塊壓縮而有所不同:
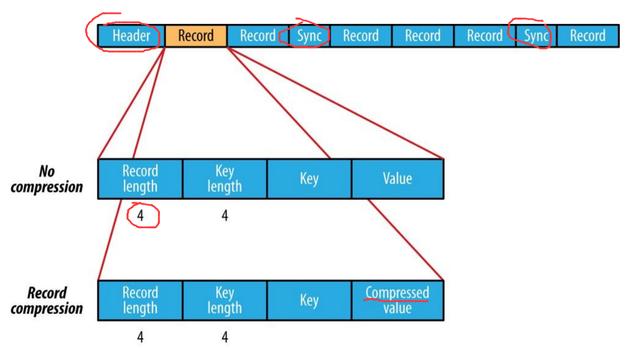
> The Internal structure of a sequence file with no compression and with record compression.
- 不壓縮:根據(jù)記錄長度,鍵長,值程度,鍵值和值值順序存儲。 范圍是字節(jié)數(shù)。 使用指定的序列化執(zhí)行序列化。
- 記錄壓縮:僅壓縮值,并將壓縮的編解碼器存儲在標(biāo)頭中。
- 塊壓縮:將多個記錄壓縮在一起,以利用記錄之間的相似性并節(jié)省空間。 同步標(biāo)記被添加在塊之前和之后。 該屬性的最小值為io.seqfile.compress.blocksizeset。
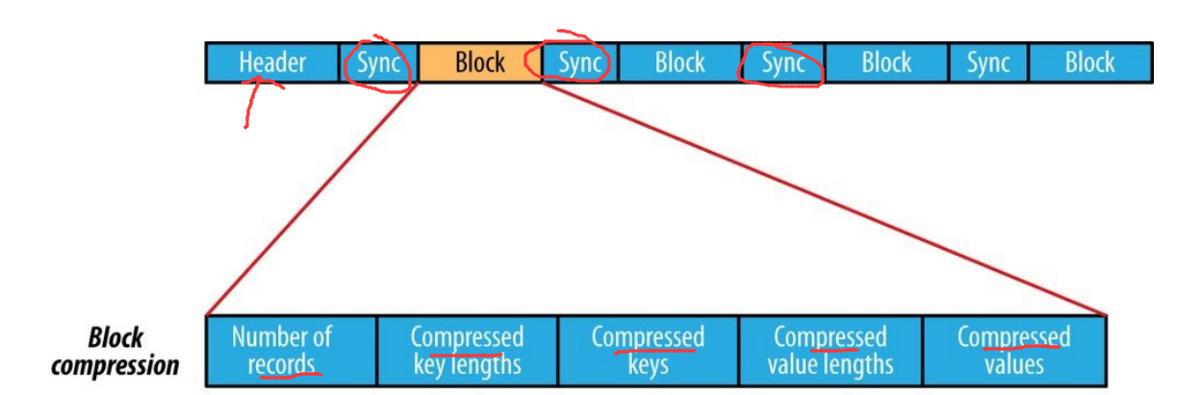
> The internal structure of a sequence file with block compression
地圖文件
MapFile是SequenceFile的變體。 將索引添加到SequenceFile并對其進(jìn)行排序后,它就是MapFile。 索引存儲為單獨的文件,通常每128條記錄存儲一個索引。 可以將索引加載到內(nèi)存中以進(jìn)行快速查找-存儲按Key定義的順序排列的數(shù)據(jù)的文件。 MapFile記錄必須按順序編寫。 否則,將引發(fā)IOException。
MapFile的派生類型:
- SetFile:一個特殊的MapFile,用于存儲可寫類型的鍵序列。 密鑰是按順序?qū)懭氲摹?/li>
- ArrayFile:鍵是一個整數(shù),表示數(shù)組中的位置,值是可寫的。
- BloomMapFile:使用動態(tài)Bloom過濾器針對MapFile get()方法進(jìn)行了優(yōu)化。 過濾器存儲在內(nèi)存中,并且僅當(dāng)鍵值存在時,才會調(diào)用常規(guī)的get()方法來執(zhí)行讀取操作。
Hadoop系統(tǒng)下面列出的文件包括RCFile,ORCFile和Parquet。 Avro的面向列的版本是Trevni。
RC文件
Hive的Record Columnar File(記錄列文件),這種類型的文件首先將數(shù)據(jù)按行劃分為行組,然后在行組內(nèi)部將數(shù)據(jù)存儲在列中。 其結(jié)構(gòu)如下:
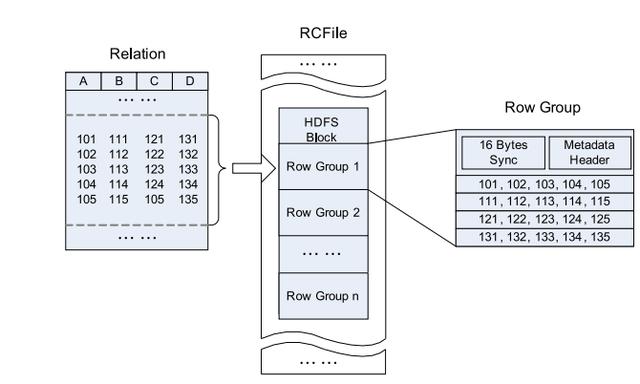
> Data Layout of RC File in an HDFS block
與純面向行和面向列的比較:
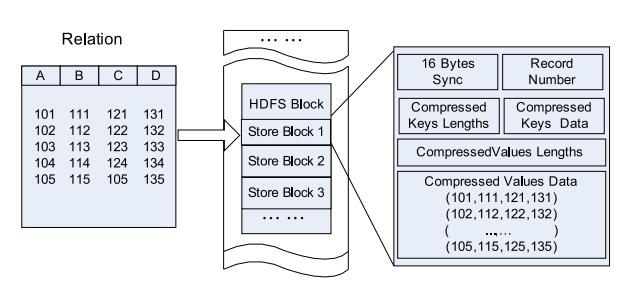
> Row-Store in an HDFS Block
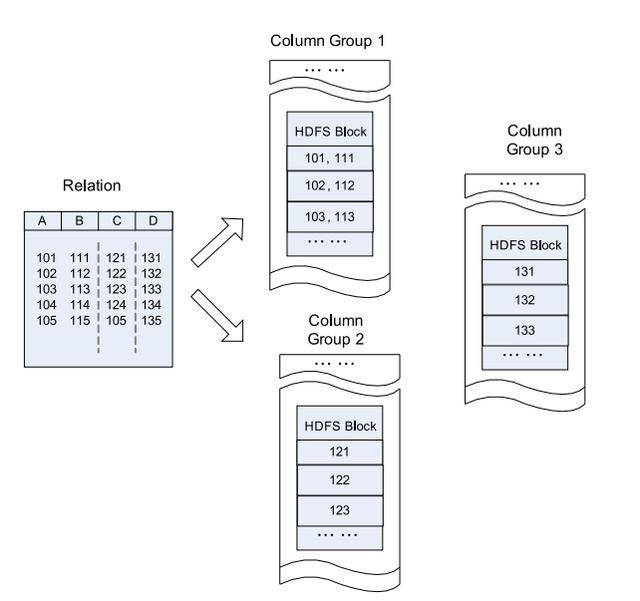
> Column Group in HDFS Block
ORC文件
ORCFile(優(yōu)化的記錄列文件)提供了比RCFile更有效的文件格式。 它在內(nèi)部將數(shù)據(jù)劃分為默認(rèn)大小為250M的Stripe。 每個條帶均包含索引,數(shù)據(jù)和頁腳。 索引存儲每列的最大值和最小值以及列中每一行的位置。
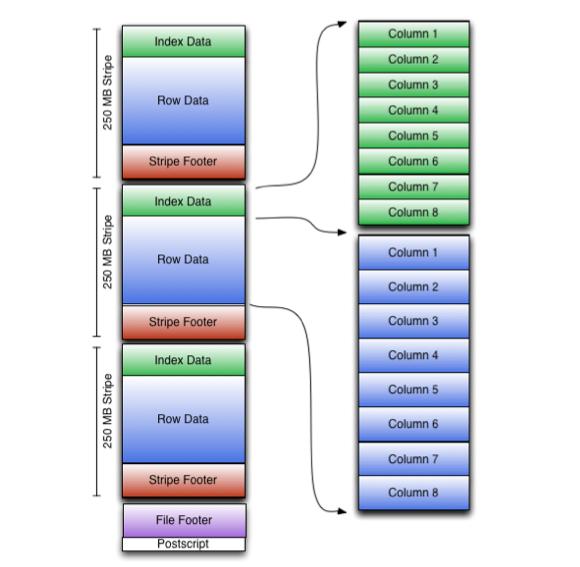
> ORC File Layout
在Hive中,以下命令用于使用ORCFile:
CREATE TABLE ...STORED AAS ORC ALTER TABLE ... SET FILEFORMAT ORC SET hive.default.fileformat=ORC
Parquet
一種通用的基于列的存儲格式,基于Google的Dremel。 特別擅長處理深度嵌套的數(shù)據(jù)。
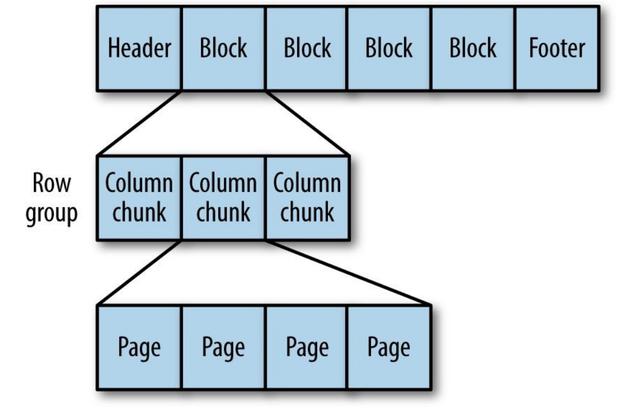
> The internal Structure of Parquet File
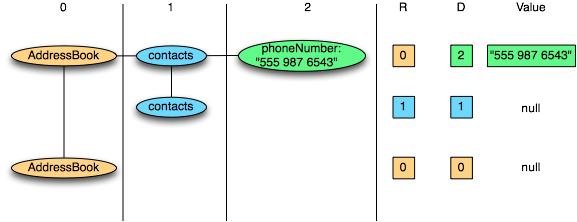
對于嵌套結(jié)構(gòu),Parquet會將其轉(zhuǎn)換為平面列存儲,該存儲由重復(fù)級別和定義級別(R和D)表示,并在讀取數(shù)據(jù)以重建整個文件時使用元數(shù)據(jù)來重建記錄。 結(jié)構(gòu)體。 以下是R和D的示例:
AddressBook { contacts: { phoneNumber: "555 987 6543" } contacts: { } } AddressBook { }
就這樣,現(xiàn)在,您知道了Hadoop中不同的文件格式。 如果您發(fā)現(xiàn)任何錯誤并提出建議,請隨時與我聯(lián)系。 您可以在我的LinkedIn上與我聯(lián)系。