機器學習模型必不可少的5種數據預處理技術
如果您曾經參與過數據科學項目,那么您可能會意識到數據挖掘的第一步和主要步驟是數據預處理。在現實生活問題中,我們得到的原始數據往往非常混亂,機器學習模型無法識別模式并從中提取信息。
1.處理空值:
空值是數據中任何行或列中缺失的值。空值出現的原因可能是沒有記錄或數據損壞。在python中,它們被標記為“Nan”。您可以通過運行以下代碼來檢查它
- data.isnull().sum()
我們可以用該列的平均值或該列中最頻繁出現的項來填充這些空值。或者我們可以用-999這樣的隨機值替換Nan。我們可以使用panda庫中的fillna()函數來填充Nan的值。如果一列有大量的空值(假設超過50%),那么將該列從dataframe中刪除會更好。您還可以使用來自同一列中不為空的k近鄰的值來填充空值。Sklearn的KNNImputer()可以幫助您完成這項任務。
2. 處理離群值:
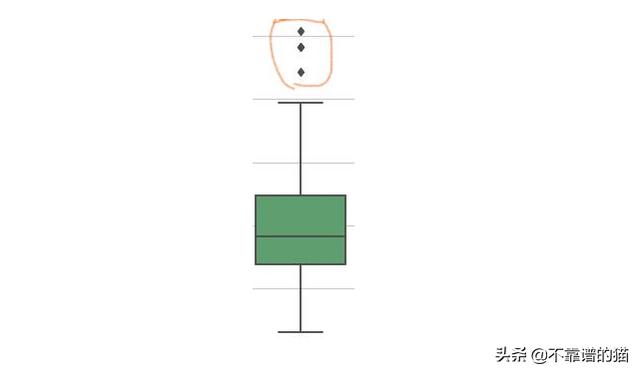
離群值是與數據中的其他值保持一定距離的數據點。我們可以使用可視化工具(例如Boxplots)來檢測離群值:
通過繪制兩個特征向量之間的散點圖:
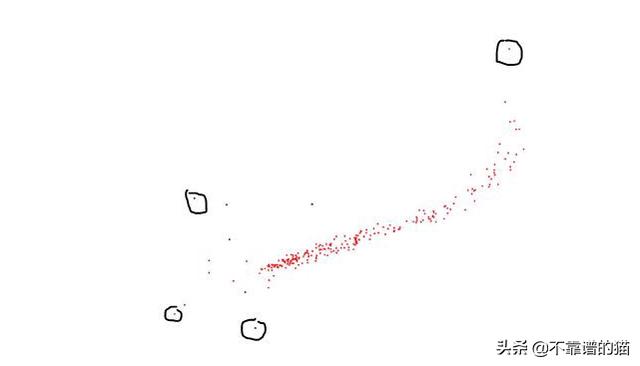
散點圖中的離群值
如果您了解數據背后的科學事實(例如這些數據點必須位于的范圍),則可以將離群值排除在外。例如,如果年齡是您數據的特征,那么您就知道它必須介于0到100之間(或在某些情況下介于0到130歲之間)。但是,如果數據中的年齡值有些荒謬,例如300,那么必須將其刪除。如果機器學習模型的預測很關鍵,即微小的變化都很重要,那么您就不應該放棄這些離群值。同樣,如果離群值大量存在(例如25%或更多),那么它們很有可能代表有用的東西。在這種情況下,您必須仔細檢查離群值。
3. 歸一化或數據縮放:
如果您使用的是基于距離的機器學習算法,例如K近鄰,線性回歸,K均值聚類或神經網絡,那么在將數據輸入機器學習模型之前,對數據進行歸一化是一個好習慣。歸一化是指修改數值特征的值以使其達到共同的標度而不改變它們之間的相關性。不同數值特征中的值位于不同的范圍內,這可能會降低模型的性能,因此歸一化可以確保在進行預測時為特征分配適當的權重。一些常用的歸一化技術是:
a)Min-Max歸一化 -將特征縮放到最小和最大值之間的給定范圍。公式為:
X(scaled)=a+ (b-a)(X - Xmin)/(Xmax - Xmin)
其中a是最小值,b是最大值。
b)Z-score歸一化 -我們從每個特征中減去均值,然后除以其標準差,以使得到的縮放特征具有零均值和單位方差。公式為:
X(scaled)=(X - mean(X)) /σ
這樣,您可以將數據的分布更改為正態分布。
4. 編碼分類特征
分類特征是包含離散數據值的特征。如果一個分類特征有字符、單詞、符號或日期作為數據值,那么這些數據必須被編碼成數字,以便機器學習模型能夠理解,因為它們只處理數字數據。有三種方法來編碼你的數據:
a)標簽編碼:在 這種類型的編碼中,分類特征中的每個離散值都根據字母順序分配一個唯一的整數。在下面的示例中,您可以看到為每個水果分配了一個相應的整數標簽:
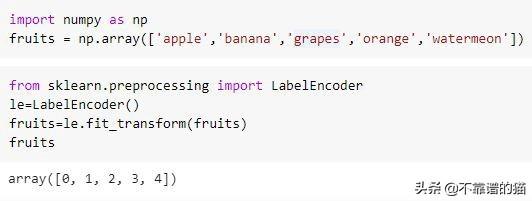
標簽編碼通常適用于線性模型,如線性回歸,Logistic回歸以及神經網絡。
b)One-hot:在這種編碼類型中,分類特征中的每個離散值都分配有唯一的one-hot向量或由1和0組成的二進制向量。在one-hot向量中,僅離散值的索引標記為1,其余所有值標記為0。在下面的示例中,您可以看到為每個水果分配了對應的長度為5的one-hot向量:
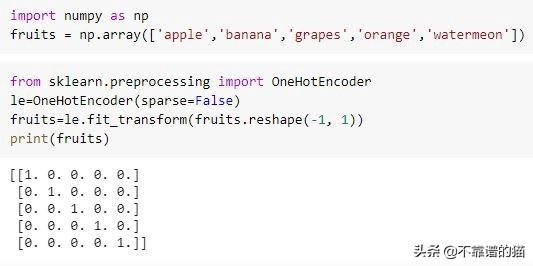
one-hot編碼通常可與基于樹的模型(例如隨機森林和梯度提升機)配合使用。
c)均值編碼-在 這種類型的編碼中,分類特征中的每個離散值都使用相應的均值目標標簽進行編碼。為了更好地理解,讓我們看下面的示例:
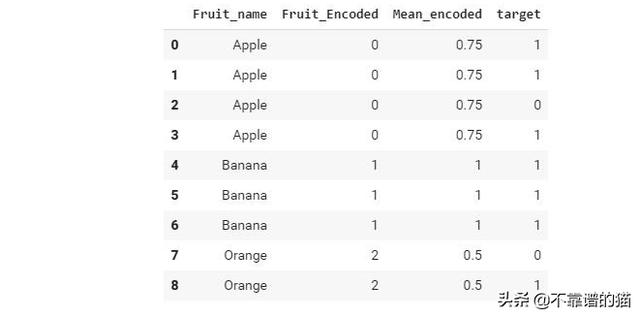
我們有三個水果標簽['Apple','Banana','Orange']。每個水果標簽的平均編碼公式如下:
Encoded feature = True targets/Total targets
對于Apple來說,true targets是3,total targets是4,因此Apple的均值編碼是3/4 =0.75。類似地,Orange的編碼是1/2=0.5,banana的編碼是3/3 =1。均值編碼是標簽編碼的擴展版本,由于它考慮了目標標簽,因此與之相比更符合邏輯。
5. 離散化:
這也是一種很好的預處理技術,有時可以通過減小數據大小來提高模型的性能。它主要用于數值特征。在離散化中,數字特征分為bin / intervals。每個bin都包含一定范圍內的數值。一個bin中的值數量可以相同,也可以不同,然后將每個bin視為分類值。我們可以使用離散化將數值特征轉換為分類特征。
這些是實現機器學習模型時可以用來預處理數據的不同方法。希望本文對您有所幫助。