一次MySQL索引面試,被面試官懟的體無完膚!
之前有過一次面試,關(guān)于MySQL索引的原理及使用被面試官懟的體無完膚,立志要總結(jié)一番,然后一直沒有時間(其實是懶……),準備好了嗎?
索引是什么?
數(shù)據(jù)庫索引,是數(shù)據(jù)庫管理系統(tǒng)(DBMS)中一個排序的數(shù)據(jù)結(jié)構(gòu),它可以對數(shù)據(jù)庫表中一列或多列的值進行排序,以協(xié)助更加快速的訪問數(shù)據(jù)庫表中特定的數(shù)據(jù)。通俗的說,我們可以把數(shù)據(jù)庫索引比做是一本書前面的目錄,它能加快數(shù)據(jù)庫的查詢速度。
為什么需要索引?
思考:如何在一個圖書館中找到一本書?設(shè)想一下,假如在圖書館中沒有其他輔助手段,只能一條道走到黑,一本書一本書的找,經(jīng)過3個小時的連續(xù)查找,終于找到了你需要看的那本書,但此時天都黑了。
為了避免這樣的事情,每個圖書館才都配備了一套圖書館管理系統(tǒng),大家要找書籍的話,先在系統(tǒng)上查找到書籍所在的房屋編號、圖書架編號還有書在圖書架幾層的那個方位,然后就可以直接大搖大擺的去取書了,就可以很快速的找到我們所需要的書籍。索引就是這個原理,它可以幫助我們快速的檢索數(shù)據(jù)。
一般的應(yīng)用系統(tǒng)對數(shù)據(jù)庫的操作,遇到最多、最容易出問題是一些復(fù)雜的查詢操作,當數(shù)據(jù)庫中數(shù)據(jù)量很大時,查找數(shù)據(jù)就會變得很慢,這樣就很影響整個應(yīng)用系統(tǒng)的效率,我們就可以使用索引來提高數(shù)據(jù)庫的查詢效率。
B-Tree和B+Tree
目前大部分數(shù)據(jù)庫系統(tǒng)及文件系統(tǒng)都采用B-Tree或其變種B+Tree作為索引結(jié)構(gòu), 我在這里分別講一下。推薦看下:為什么索引能提高查詢速度?
B-Tree
即B樹,注意(不是B減樹),B樹是一種多路搜索樹。使用B-Tree結(jié)構(gòu)可以顯著減少定位記錄時所經(jīng)歷的中間過程,從而加快存取速度。
B-Tree有如下一些特征:
- 定義任意非葉子結(jié)點最多只有M個子節(jié)點,且M>2。
- 根結(jié)點的兒子數(shù)為[2, M]。
- 除根結(jié)點以外的非葉子結(jié)點的兒子數(shù)為[M/2, M], 向上取整 。
- 每個結(jié)點存放至少M/2-1(取上整)和至多M-1個關(guān)鍵字;(至少2個關(guān)鍵字)。
- 非葉子結(jié)點的關(guān)鍵字個數(shù)=指向兒子的指針個數(shù)-1。
- 非葉子結(jié)點的關(guān)鍵字:K[1], K[2], …, K[M-1],且K[i] <= K[i+1]。
- 非葉子結(jié)點的指針:P[1], P[2], …,P[M](其中P[1]指向關(guān)鍵字小于K[1]的子樹,P[M]指向關(guān)鍵字大于K[M-1]的子樹,其它P[i]指向關(guān)鍵字屬于(K[i-1], K[i])的子樹)。
- 所有葉子結(jié)點位于同一層。
有關(guān)b樹的一些特性:
- 關(guān)鍵字集合分布在整顆樹的所有結(jié)點之中;
- 任何一個關(guān)鍵字出現(xiàn)且只出現(xiàn)在一個結(jié)點中;
- 搜索有可能在非葉子結(jié)點結(jié)束;
- 其搜索性能等價于在關(guān)鍵字全集內(nèi)做一次二分查找。
B樹的搜索:從根結(jié)點開始,對結(jié)點內(nèi)的關(guān)鍵字(有序)序列進行二分查找,如果命中則結(jié)束,否則進入查詢關(guān)鍵字所屬范圍的兒子結(jié)點;重復(fù)執(zhí)行這個操作,直到所對應(yīng)的節(jié)點指針為空,或者已經(jīng)是是葉子結(jié)點。
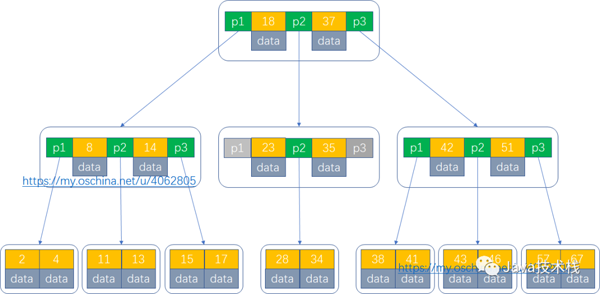
例如下面一個B樹,那么查找元素43的過程如下:
根據(jù)根節(jié)點指針找到18、37所在節(jié)點,把此節(jié)點讀入內(nèi)存,進行第一次磁盤IO,此時發(fā)現(xiàn)43>37,找到指針p3。
根據(jù)指針p3,找到42、51所在節(jié)點,把此節(jié)點讀入內(nèi)存,進行第二次磁盤IO,此時發(fā)現(xiàn)42<43<51,找到指針p2。
根據(jù)指針p2,找到43、46所在節(jié)點,把此節(jié)點讀入內(nèi)存,進行第三次磁盤IO,此時我們就已經(jīng)查到了元素43。
在此過程總共進行了三次磁盤IO。
B+Tree
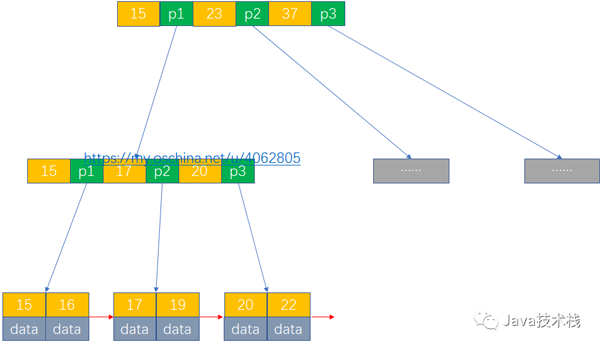
B+Tree屬于B-Tree的變種。與B-Tree相比,B+Tree有以下不同點:
- 有n棵子樹的非葉子結(jié)點中含有n個關(guān)鍵字(B樹是n-1個),即非葉子結(jié)點的子樹指針與關(guān)鍵字個數(shù)相同。這些關(guān)鍵字不保存數(shù)據(jù),只用來索引,所有數(shù)據(jù)都保存在葉子節(jié)點(B樹是每個關(guān)鍵字都保存數(shù)據(jù))。
2. 所有的葉子結(jié)點中包含了全部關(guān)鍵字的信息,及指向含這些關(guān)鍵字記錄的指針,且葉子結(jié)點本身依關(guān)鍵字的大小自小而大順序鏈接。
3. 所有的非葉子結(jié)點可以看成是葉子節(jié)點的索引部分。
4. 同一個數(shù)字會在不同節(jié)點中重復(fù)出現(xiàn),根節(jié)點的最大元素就是b+樹的最大元素。
相對B樹,B+樹做索引的優(yōu)勢
- B+樹的磁盤IO代價更低:B+樹非葉子節(jié)點沒有指向數(shù)據(jù)行的指針,所以相同的磁盤容量存儲的節(jié)點數(shù)更多,相應(yīng)的IO讀寫次數(shù)肯定減少了。
- B+樹的查詢效率更加穩(wěn)定:由于所有數(shù)據(jù)都存于葉子節(jié)點。所有關(guān)鍵字查詢的路徑長度相同,每一個數(shù)據(jù)的查詢效率相當。
- 所有的葉子節(jié)點形成了一個有序鏈表,更加便于查找。
關(guān)于MySQL的兩種常用存儲引擎MyISAM和InnoDB的索引均以B+樹作為數(shù)據(jù)結(jié)構(gòu),二者卻有不同(這里只說二者索引的區(qū)別)。推薦看下:InnoDB一棵B+樹可以存放多少行數(shù)據(jù)?
MyISAM索引和Innodb索引的區(qū)別
MyISAM使用B+樹作為索引結(jié)構(gòu),葉節(jié)點葉節(jié)點的data域保存的是存儲數(shù)據(jù)的地址,主鍵索引key值唯一,輔助索引key可以重復(fù),二者在結(jié)構(gòu)上相同。關(guān)注微信公眾號:Java技術(shù)棧,在后臺回復(fù):mysql,可以獲取我整理的 N 篇 MySQL 教程,都是干貨。
因此,MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果要找的Key存在,則取出其data域的值,然后以data域的值為地址,去讀取相應(yīng)數(shù)據(jù)記錄 。因此,索引文件和數(shù)據(jù)文件是分開的,從索引中檢索到的是數(shù)據(jù)的地址,而不是數(shù)據(jù)。
Innodb也是用B+樹作為索引結(jié)構(gòu),但具體實現(xiàn)方式卻與MyISAM截然不同,首先,數(shù)據(jù)表本身就是按照b+樹組織,所以數(shù)據(jù)文件本身就是主鍵索引文件。葉節(jié)點key值為數(shù)據(jù)表的主鍵,data域為完整的數(shù)據(jù)記錄。
因此InnoDB表數(shù)據(jù)文件本身就是主鍵索引(這也就是MyISAM可以允許沒有主鍵,但是Innodb必須有主鍵的原因)。第二個與MyISAM索引的不同是InnoDB的輔助索引的data域存儲相應(yīng)數(shù)據(jù)記錄的主鍵值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。
索引類型
普通索引:(由關(guān)鍵字KEY或INDEX定義的索引)的唯一任務(wù)是加快對數(shù)據(jù)的訪問速度。
唯一索引:普通索引允許被索引的數(shù)據(jù)列包含重復(fù)的值,而唯一索引不允許,但是可以為null。所以任務(wù)是保證訪問速度和避免數(shù)據(jù)出現(xiàn)重復(fù)。
主鍵索引:在主鍵字段創(chuàng)建的索引,一張表只有一個主鍵索引。
組合索引:多列值組成一個索引,專門用于組合搜索。
全文索引:對文本的內(nèi)容進行分詞,進行搜索。(MySQL5.6及以后的版本,MyISAM和InnoDB存儲引擎均支持全文索引。)推薦看下:MySQL 索引B+樹原理,以及建索引的幾大原則。
索引的使用策略及優(yōu)缺點
使用索引
主鍵自動建立唯一索引。
經(jīng)常作為查詢條件在WHERE或者ORDER BY 語句中出現(xiàn)的列要建立索引。
查詢中與其他表關(guān)聯(lián)的字段,外鍵關(guān)系建立索引。
經(jīng)常用于聚合函數(shù)的列要建立索引,如min(),max()等的聚合函數(shù)。
不使用索引
經(jīng)常增刪改的列不要建立索引。
有大量重復(fù)的列不建立索引。
表記錄太少不要建立索引,因為數(shù)據(jù)較少,可能查詢?nèi)繑?shù)據(jù)花費的時間比遍歷索引的時間還要短,索引就可能不會產(chǎn)生優(yōu)化效果 。
最左匹配原則
建立聯(lián)合索引的時候都會默認從最左邊開始,所以索引列的順序很重要,建立索引的時候就應(yīng)該把最常用的放在左邊,使用select的時候也是這樣,從最左邊的開始,依次匹配右邊的。
優(yōu)點
可以保證數(shù)據(jù)庫表中每一行的數(shù)據(jù)的唯一性。
可以大大加快數(shù)據(jù)的索引速度。
加速表與表之間的連接。
可以顯著的減少查詢中分組和排序的時間。
缺點
創(chuàng)建索引和維護索引要耗費時間,這種時間隨著數(shù)據(jù)量的增加而增加。
索引需要占物理空間,除了數(shù)據(jù)表占用數(shù)據(jù)空間之外,每一個索引還要占用一定的物理空間,如果需要建立聚簇索引,那么需要占用的空間會更大,其實建立索引就是以空間換時間。
表中的數(shù)據(jù)進行增、刪、改的時候,索引也要動態(tài)的維護,這就降低了維護效率。
驗證索引是否能夠提升查詢性能
創(chuàng)建測試表index_test

使用python腳本程序通過pymsql模塊,向表中添加十萬條數(shù)據(jù)
- import pymysql
- def main():
- # 創(chuàng)建Connection連接
- conn = pymysql.connect(host='localhost',
- port=3306,
- database='db_test',
- user='root',
- password='deepin',
- charset='utf8')
- # 獲得Cursor對象
- cursor = conn.cursor()
- # 插入10萬次數(shù)據(jù)
- for i in range(100000):
- cursor.execute("insert into index_test values('haha-%d')" % i)
- # 提交數(shù)據(jù)
- conn.commit()
- if __name__ == "__main__":
- main()
在mysql終端開啟運行時間監(jiān)測:set profiling=1;

查找第1萬條數(shù)據(jù)ha-99999
- select * from index_test where name='haha-99999';
查看執(zhí)行的時間:
- show profiles;
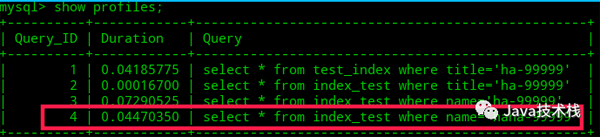
為表index_test的name列創(chuàng)建索引:
- create index name index on index_test(name(10));
再次執(zhí)行查詢語句、查看執(zhí)行的時間:

可以看出合適的索引確實可以明顯提高某些字段的查詢效率。
最后,感謝女朋友在生活中,工作上的包容、理解與支持 !