













Kafka:消息是如何在服務端存儲與讀取的,你真的知道嗎?
前言
小伙伴們肯定也比較好奇,Kafka 能夠處理千萬級消息,那它的消息是如何在 Partition 上存儲的呢?今天這篇文章就來為大家揭秘消息是如何存儲的。本文主要從消息的邏輯存儲和物理存儲兩個角度來介紹其實現原理。
文章概覽
- Partition、Replica、Log 和 LogSegment 的關系。
- 寫入消息流程分析。
- 消費消息及副本同步流程分析。
Partition、Replica、Log 和 LogSegment 的關系
假設有一個 Kafka 集群,Broker 個數為 3,Topic 個數為 1,Partition 個數為 3,Replica 個數為 2。Partition 的物理分布如下圖所示。
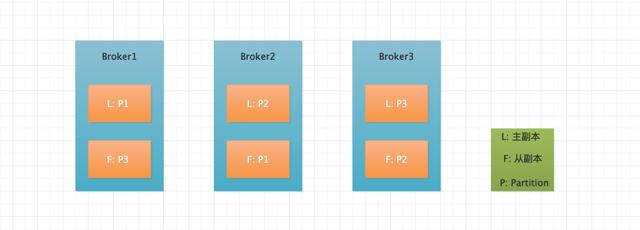
Partition分布圖
從上圖可以看出,該 Topic 由三個 Partition 構成,并且每個 Partition 由主從兩個副本構成。每個 Partition 的主從副本分布在不同的 Broker 上,通過這點也可以看出,當某個 Broker 宕機時,可以將分布在其他 Broker 上的從副本設置為主副本,因為只有主副本對外提供讀寫請求,當然在最新的 2.x 版本中從副本也可以對外讀請求了。將主從副本分布在不同的 Broker 上從而提高系統的可用性。
Partition 的實際物理存儲是以 Log 文件的形式展示的,而每個 Log 文件又以多個 LogSegment 組成。Kafka 為什么要這么設計呢?其實原因比較簡單,隨著消息的不斷寫入,Log 文件肯定是越來越大,Kafka 為了方便管理,將一個大文件切割成一個一個的 LogSegment 來進行管理;每個 LogSegment 由數據文件和索引文件構成,數據文件是用來存儲實際的消息內容,而索引文件是為了加快消息內容的讀取。
可能又有朋友會問,Kafka 本身消費是以 Partition 維度順序消費消息的,磁盤在順序讀的時候效率很高完全沒有必要使用索引啊。其實 Kafka 為了滿足一些特殊業務需求,比如要隨機消費 Partition 中的消息,此時可以先通過索引文件快速定位到消息的實際存儲位置,然后進行處理。
總結一下 Partition、Replica、Log 和 LogSegment 之間的關系。消息是以 Partition 維度進行管理的,為了提高系統的可用性,每個 Partition 都可以設置相應的 Replica 副本數,一般在創建 Topic 的時候同時指定 Replica 的個數;Partition 和 Replica 的實際物理存儲形式是通過 Log 文件展現的,為了防止消息不斷寫入,導致 Log 文件大小持續增長,所以將 Log 切割成一個一個的 LogSegment 文件。
注意: 在同一時刻,每個主 Partition 中有且只有一個 LogSegment 被標識為可寫入狀態,當一個 LogSegment 文件大小超過一定大小后(比如當文件大小超過 1G,這個就類似于 HDFS 存儲的數據文件,HDFS 中數據文件達到 128M 的時候就會被分出一個新的文件來存儲數據),就會新創建一個 LogSegment 來繼續接收新寫入的消息。
寫入消息流程分析
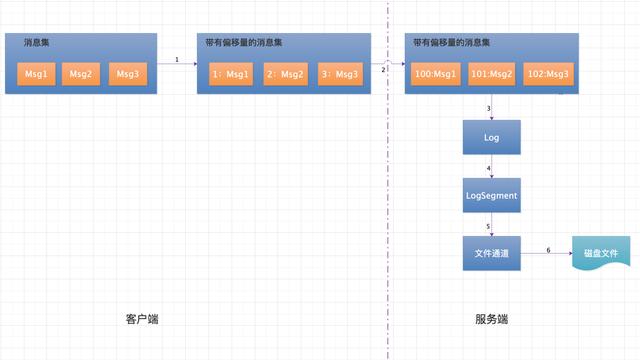
消息寫入及落盤流程
流程解析
在第 3 篇文章講過,生產者客戶端對于每個 Partition 一次會發送一批消息到服務端,服務端收到一批消息后寫入相應的 Partition 上。上圖流程主要分為如下幾步:
- 客戶端消息收集器收集屬于同一個分區的消息,并對每條消息設置一個偏移量,且每一批消息總是從 0 開始單調遞增。比如第一次發送 3 條消息,則對三條消息依次編號 [0,1,2],第二次發送 4 條消息,則消息依次編號為 [0,1,2,3]。注意此處設置的消息偏移量是相對偏移量。
- 客戶端將消息發送給服務端,服務端拿到下一條消息的絕對偏移量,將傳到服務端的這批消息的相對偏移量修改成絕對偏移量。
- 將修改后的消息以追加的方式追加到當前活躍的 LogSegment 后面,然后更新絕對偏移量。
- 將消息集寫入到文件通道。
- 文件通道將消息集 flush 到磁盤,完成消息的寫入操作。
了解以上過程后,我們在來看看消息的具體構成情況。
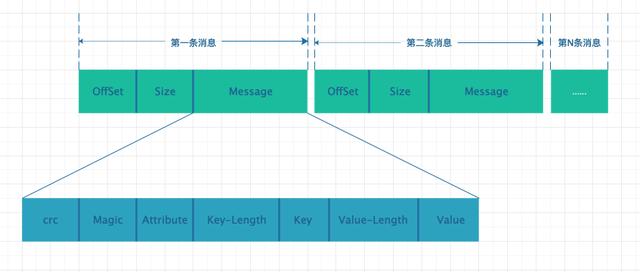
消息構成細節圖
一條消息由如下三部分構成:
- OffSet:偏移量,消息在客戶端發送前將相對偏移量存儲到該位置,當消息存儲到 LogSegment 前,先將其修改為絕對偏移量在寫入磁盤。
- Size:本條 Message 的內容大小
- Message:消息的具體內容,其具體又由 7 部分組成,crc 用于校驗消息,Attribute 代表了屬性,key-length 和 value-length 分別代表 key 和 value 的長度,key 和 value 分別代表了其對應的內容。
消息偏移量的計算過程
通過以上流程可以看出,每條消息在被實際存儲到磁盤時都會被分配一個絕對偏移量后才能被寫入磁盤。在同一個分區內,消息的絕對偏移量都是從 0 開始,且單調遞增;在不同分區內,消息的絕對偏移量是沒有任何關系的。接下來討論下消息的絕對偏移量的計算規則。
確定消息偏移量有兩種方式,一種是順序讀取每一條消息來確定,此種方式代價比較大,實際上我們并不想知道消息的內容,而只是想知道消息的偏移量;第二種是讀取每條消息的 Size 屬性,然后計算出下一條消息的起始偏移量。比如第一條消息內容為 “abc”,寫入磁盤后的偏移量為:8(OffSet)+ 4(Message 大小)+ 3(Message 內容的長度)= 15。第二條寫入的消息內容為“defg”,其起始偏移量為 15,下一條消息的起始偏移量應該是:15+8+4+4=31,以此類推。
消費消息及副本同步流程分析
和寫入消息流程不同,讀取消息流程分為兩種情況,分別是消費端消費消息和從副本(備份副本)同步主副本的消息。在開始分析讀取流程之前,需要先明白幾個用到的變量,不然流程分析可能會看的比較糊涂。
- BaseOffSet:基準偏移量,每個 Partition 由 N 個 LogSegment 組成,每個 LogSegment 都有基準偏移量,大概由如下構成,數組中每個數代表一個 LogSegment 的基準偏移量:[0,200,400,600, ...]。
- StartOffSet:起始偏移量,由消費端發起讀取消息請求時,指定從哪個位置開始消費消息。
- MaxLength:拉取大小,由消費端發起讀取消息請求時,指定本次最大拉取消息內容的數據大小。該參數可以通過max.partition.fetch.bytes來指定,默認大小為 1M。
- MaxOffSet:最大偏移量,消費端拉取消息時,最高可拉取消息的位置,即俗稱的“高水位”。該參數由服務端指定,其作用是為了防止生產端還未寫入的消息就被消費端進行消費。此參數對于從副本同步主副本不會用到。
- MaxPosition:LogSegment 的最大位置,確定了起始偏移量在某個 LogSegment 上開始,讀取 MaxLength 后,不能超過 MaxPosition。MaxPosition 是一個實際的物理位置,而非偏移量。
假設消費端從 000000621 位置開始消費消息,關于幾個變量的關系如下圖所示。
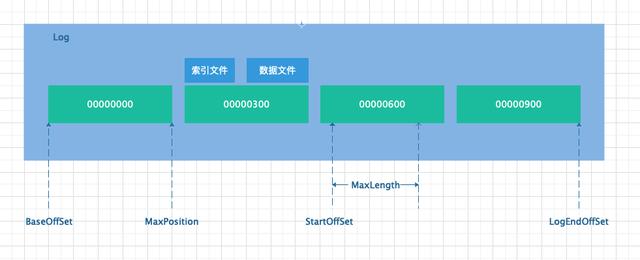
位置關系圖
消費端和從副本拉取流程如下:
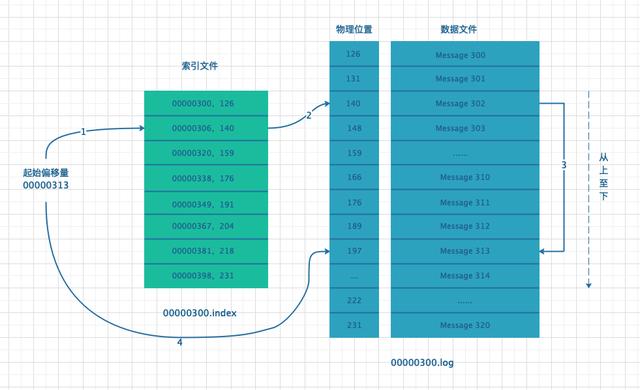
- 客戶端確定拉取的位置,即 StartOffSet 的值,找到主副本對應的 LogSegment。
- LogSegment 由索引文件和數據文件構成,由于索引文件是從小到大排列的,首先從索引文件確定一個小于等于 StartOffSet 最近的索引位置。
- 根據索引位置找到對應的數據文件位置,由于數據文件也是從小到大排列的,從找到的數據文件位置順序向后遍歷,直到找到和 StartOffSet 相等的位置,即為消費或拉取消息的位置。
從 StartOffSet 開始向后拉取 MaxLength 大小的數據,返回給消費端或者從副本進行消費或備份操作。
假設拉取消息起始位置為 00000313,消息拉取流程圖如下:
消息拉取流程圖
總結
本文從邏輯存儲和物理存儲的角度,分析了消息的寫入與消費流程。其中邏輯存儲是以 Partition 來管理一批一批的消息,Partition 映射 Log 對象,Log 對象管理了多個 LogSegment,多個 Partition 構成了一個完整的 Topic。消息的實際物理存儲是由一個一個的 LogSegment 構成,每個 LogSegment 又由索引文件和數據文件構成。




























