關于 TCP/IP,運維必知必會的十個問題
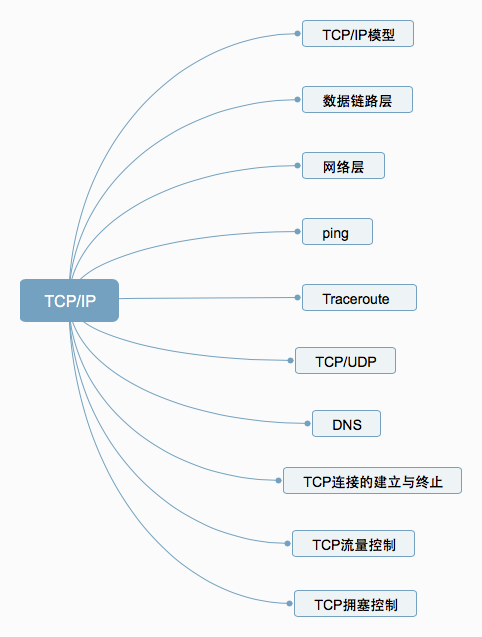
一、TCP/IP模型



上圖以HTTP協議為例,具體說明。
二、數據鏈路層

-
封裝成幀: 把網絡層數據報加頭和尾,封裝成幀,幀頭中包括源MAC地址和目的MAC地址。
-
透明傳輸:零比特填充、轉義字符。
-
可靠傳輸: 在出錯率很低的鏈路上很少用,但是無線鏈路WLAN會保證可靠傳輸。
-
差錯檢測(CRC):接收者檢測錯誤,如果發現差錯,丟棄該幀。
三、網絡層
1.IP協議
IP協議是TCP/IP協議的核心,所有的TCP,UDP,IMCP,IGMP的數據都以IP數據格式傳輸。要注意的是,IP不是可靠的協議,這是說,IP協議沒有提供一種數據未傳達以后的處理機制,這被認為是上層協議:TCP或UDP要做的事情。
1.1 IP地址
B類IP地址:128.0.0.1~191.255.0.0
C類IP地址:192.168.0.0~239.255.255.0
1.2 IP協議頭

2.ARP及RARP協議
3. ICMP協議
IP協議并不是一個可靠的協議,它不保證數據被送達,那么,自然的,保證數據送達的工作應該由其他的模塊來完成。其中一個重要的模塊就是ICMP(網絡控制報文)協議。ICMP不是高層協議,而是IP層的協議。
當傳送IP數據包發生錯誤。比如主機不可達,路由不可達等等,ICMP協議將會把錯誤信息封包,然后傳送回給主機。給主機一個處理錯誤的機會,這 也就是為什么說建立在IP層以上的協議是可能做到安全的原因。
四、ping
ping可以說是ICMP的最著名的應用,是TCP/IP協議的一部分。利用“ping”命令可以檢查網絡是否連通,可以很好地幫助我們分析和判定網絡故障。
例如:當我們某一個網站上不去的時候。通常會ping一下這個網站。ping會回顯出一些有用的信息。一般的信息如下:

五、Traceroute
Traceroute是用來偵測主機到目的主機之間所經路由情況的重要工具,也是最便利的工具。
Traceroute的原理是非常非常的有意思,它收到到目的主機的IP后,首先給目的主機發送一個TTL=1的UDP數據包,而經過的第一個路由器收到這個數據包以后,就自動把TTL減1,而TTL變為0以后,路由器就把這個包給拋棄了,并同時產生 一個主機不可達的ICMP數據報給主機。主機收到這個數據報以后再發一個TTL=2的UDP數據報給目的主機,然后刺激第二個路由器給主機發ICMP數據 報。如此往復直到到達目的主機。這樣,traceroute就拿到了所有的路由器IP。

六、TCP/UDP

面向報文
面向報文的傳輸方式是應用層交給UDP多長的報文,UDP就照樣發送,即一次發送一個報文。因此,應用程序必須選擇合適大小的報文。若報文太長,則IP層需要分片,降低效率。若太短,會是IP太小。
面向字節流

什么時候應該使用TCP?
什么時候應該使用UDP?
七、DNS
八、TCP連接的建立與終止
1.三次握手

為什么要三次握手?
2.四次揮手
當客戶端和服務器通過三次握手建立了TCP連接以后,當數據傳送完畢,肯定是要斷開TCP連接的啊。那對于TCP的斷開連接,這里就有了神秘的“四次分手”。

第一次分手:主機1(可以使客戶端,也可以是服務器端),設置Sequence Number,向主機2發送一個FIN報文段;此時,主機1進入FIN_WAIT_1狀態;這表示主機1沒有數據要發送給主機2了;
第二次分手:主機2收到了主機1發送的FIN報文段,向主機1回一個ACK報文段,Acknowledgment Number為Sequence Number加1;主機1進入FIN_WAIT_2狀態;主機2告訴主機1,我“同意”你的關閉請求;
第三次分手:主機2向主機1發送FIN報文段,請求關閉連接,同時主機2進入LAST_ACK狀態;
第四次分手:主機1收到主機2發送的FIN報文段,向主機2發送ACK報文段,然后主機1進入TIME_WAIT狀態;主機2收到主機1的ACK報文段以后,就關閉連接;此時,主機1等待2MSL后依然沒有收到回復,則證明Server端已正常關閉,那好,主機1也可以關閉連接了。
為什么要四次分手?
為什么要等待2MSL?
MSL:報文段最大生存時間,它是任何報文段被丟棄前在網絡內的最長時間。原因有二:
-
保證TCP協議的全雙工連接能夠可靠關閉
-
保證這次連接的重復數據段從網絡中消失
第一點:如果主機1直接CLOSED了,那么由于IP協議的不可靠性或者是其它網絡原因,導致主機2沒有收到主機1最后回復的ACK。那么主機2就會在超時之后繼續發送FIN,此時由于主機1已經CLOSED了,就找不到與重發的FIN對應的連接。所以,主機1不是直接進入CLOSED,而是要保持TIME_WAIT,當再次收到FIN的時候,能夠保證對方收到ACK,最后正確的關閉連接。
第二點:如果主機1直接CLOSED,然后又再向主機2發起一個新連接,我們不能保證這個新連接與剛關閉的連接的端口號是不同的。也就是說有可能新連接和老連接的端口號是相同的。一般來說不會發生什么問題,但是還是有特殊情況出現:假設新連接和已經關閉的老連接端口號是一樣的,如果前一次連接的某些數據仍然滯留在網絡中,這些延遲數據在建立新連接之后才到達主機2,由于新連接和老連接的端口號是一樣的,TCP協議就認為那個延遲的數據是屬于新連接的,這樣就和真正的新連接的數據包發生混淆了。所以TCP連接還要在TIME_WAIT狀態等待2倍MSL,這樣可以保證本次連接的所有數據都從網絡中消失。
九、TCP流量控制
如果發送方把數據發送得過快,接收方可能會來不及接收,這就會造成數據的丟失。所謂流量控制就是讓發送方的發送速率不要太快,要讓接收方來得及接收。
利用滑動窗口機制可以很方便地在TCP連接上實現對發送方的流量控制。
設A向B發送數據。在連接建立時,B告訴了A:“我的接收窗口是 rwnd = 400 ”(這里的 rwnd 表示 receiver window) 。因此,發送方的發送窗口不能超過接收方給出的接收窗口的數值。請注意,TCP的窗口單位是字節,不是報文段。假設每一個報文段為100字節長,而數據報文段序號的初始值設為1。大寫ACK表示首部中的確認位ACK,小寫ack表示確認字段的值ack。

從圖中可以看出,B進行了三次流量控制。第一次把窗口減少到 rwnd = 300 ,第二次又減到了 rwnd = 100 ,最后減到 rwnd = 0 ,即不允許發送方再發送數據了。這種使發送方暫停發送的狀態將持續到主機B重新發出一個新的窗口值為止。B向A發送的三個報文段都設置了 ACK = 1 ,只有在ACK=1時確認號字段才有意義。
TCP為每一個連接設有一個持續計時器(persistence timer)。只要TCP連接的一方收到對方的零窗口通知,就啟動持續計時器。若持續計時器設置的時間到期,就發送一個零窗口控測報文段(攜1字節的數據),那么收到這個報文段的一方就重新設置持續計時器。
十、TCP擁塞控制
發送方維持一個擁塞窗口 cwnd ( congestion window )的狀態變量。擁塞窗口的大小取決于網絡的擁塞程度,并且動態地在變化。發送方讓自己的發送窗口等于擁塞窗口。
發送方控制擁塞窗口的原則是:只要網絡沒有出現擁塞,擁塞窗口就再增大一些,以便把更多的分組發送出去。但只要網絡出現擁塞,擁塞窗口就減小一些,以減少注入到網絡中的分組數。
慢開始算法:
當主機開始發送數據時,如果立即所大量數據字節注入到網絡,那么就有可能引起網絡擁塞,因為現在并不清楚網絡的負荷情況。因此,較好的方法是 先探測一下,即由小到大逐漸增大發送窗口,也就是說,由小到大逐漸增大擁塞窗口數值。
通常在剛剛開始發送報文段時,先把擁塞窗口 cwnd 設置為一個最大報文段MSS的數值。而在每收到一個對新的報文段的確認后,把擁塞窗口增加至多一個MSS的數值。用這樣的方法逐步增大發送方的擁塞窗口 cwnd ,可以使分組注入到網絡的速率更加合理。

每經過一個傳輸輪次,擁塞窗口 cwnd 就加倍。一個傳輸輪次所經歷的時間其實就是往返時間RTT。不過“傳輸輪次”更加強調:把擁塞窗口cwnd所允許發送的報文段都連續發送出去,并收到了對已發送的最后一個字節的確認。
另,慢開始的“慢”并不是指cwnd的增長速率慢,而是指在TCP開始發送報文段時先設置cwnd=1,使得發送方在開始時只發送一個報文段(目的是試探一下網絡的擁塞情況),然后再逐漸增大cwnd。
為了防止擁塞窗口cwnd增長過大引起網絡擁塞,還需要設置一個慢開始門限ssthresh狀態變量。慢開始門限ssthresh的用法如下:
-
當 cwnd < ssthresh 時,使用上述的慢開始算法。
-
當 cwnd > ssthresh 時,停止使用慢開始算法而改用擁塞避免算法。
-
當 cwnd = ssthresh 時,既可使用慢開始算法,也可使用擁塞控制避免算法。擁塞避免
擁塞避免
讓擁塞窗口cwnd緩慢地增大,即每經過一個往返時間RTT就把發送方的擁塞窗口cwnd加1,而不是加倍。這樣擁塞窗口cwnd按線性規律緩慢增長,比慢開始算法的擁塞窗口增長速率緩慢得多。

無論在慢開始階段還是在擁塞避免階段,只要發送方判斷網絡出現擁塞(其根據就是沒有收到確認),就要把慢開始門限ssthresh設置為出現擁塞時的發送 方窗口值的一半(但不能小于2)。然后把擁塞窗口cwnd重新設置為1,執行慢開始算法。
這樣做的目的就是要迅速減少主機發送到網絡中的分組數,使得發生 擁塞的路由器有足夠時間把隊列中積壓的分組處理完畢。
如下圖,用具體數值說明了上述擁塞控制的過程。現在發送窗口的大小和擁塞窗口一樣大。

2.快重傳和快恢復
快重傳
快重傳算法首先要求接收方每收到一個失序的報文段后就立即發出重復確認(為的是使發送方及早知道有報文段沒有到達對方)而不要等到自己發送數據時才進行捎帶確認。

接收方收到了M1和M2后都分別發出了確認。現在假定接收方沒有收到M3但接著收到了M4。
顯然,接收方不能確認M4,因為M4是收到的失序報文段。根據 可靠傳輸原理,接收方可以什么都不做,也可以在適當時機發送一次對M2的確認。
但按照快重傳算法的規定,接收方應及時發送對M2的重復確認,這樣做可以讓 發送方及早知道報文段M3沒有到達接收方。發送方接著發送了M5和M6。接收方收到這兩個報文后,也還要再次發出對M2的重復確認。這樣,發送方共收到了 接收方的四個對M2的確認,其中后三個都是重復確認。
快重傳算法還規定,發送方只要一連收到三個重復確認就應當立即重傳對方尚未收到的報文段M3,而不必 繼續等待M3設置的重傳計時器到期。
由于發送方盡早重傳未被確認的報文段,因此采用快重傳后可以使整個網絡吞吐量提高約20%。
快恢復
當發送方連續收到三個重復確認,就執行“乘法減小”算法,把慢開始門限ssthresh減半。 與慢開始不同之處是現在不執行慢開始算法(即擁塞窗口cwnd現在不設置為1),而是把cwnd值設置為 慢開始門限ssthresh減半后的數值,然后開始執行擁塞避免算法(“加法增大”),使擁塞窗口緩慢地線性增大。