













機(jī)器學(xué)習(xí)的中流砥柱:用于模型構(gòu)建的基礎(chǔ)架構(gòu)工具有哪些?
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)
人工智能(AI)和機(jī)器學(xué)習(xí)(ML)已然“滲透”到了各行各業(yè),企業(yè)們期待通過機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)平臺,以推動人工智能在業(yè)務(wù)中的利用。
理解各種平臺和產(chǎn)品算得上是一項(xiàng)挑戰(zhàn)。機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)空間擁擠、混亂又復(fù)雜。許多平臺和工具涵蓋了整個模型構(gòu)建工作流程的多種功能。
為了理解其生態(tài),我們可將機(jī)器學(xué)習(xí)工作流程大致分為三個階段:數(shù)據(jù)準(zhǔn)備,模型構(gòu)建和生產(chǎn)。了解工作流各個階段的目標(biāo)和挑戰(zhàn)有助于人們正確地選出最適合企業(yè)業(yè)務(wù)需求的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)平臺。

機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)平臺圖
機(jī)器學(xué)習(xí)工作流程的每個主要階段都具有許多垂直功能。其中一些功能是較大的端到端平臺的一部分內(nèi)容,還有一些功能則是某些平臺的主要關(guān)注點(diǎn)。
本文將帶你走進(jìn)機(jī)器學(xué)習(xí)的第二階段——模型構(gòu)建。
什么是模型構(gòu)建?
模型構(gòu)建的第一步從了解業(yè)務(wù)需求開始。模型需要處理哪些業(yè)務(wù)需求?
這一步驟在機(jī)器學(xué)習(xí)工作流程的計(jì)劃和構(gòu)想階段展開。在此階段,與軟件開發(fā)生命周期類似,數(shù)據(jù)科學(xué)家收集需求,考慮可行性,并為數(shù)據(jù)準(zhǔn)備、模型構(gòu)建和生產(chǎn)制定計(jì)劃。他們還使用數(shù)據(jù)來探索各種模型構(gòu)建實(shí)驗(yàn),這些實(shí)驗(yàn)是在計(jì)劃階段所考慮的。
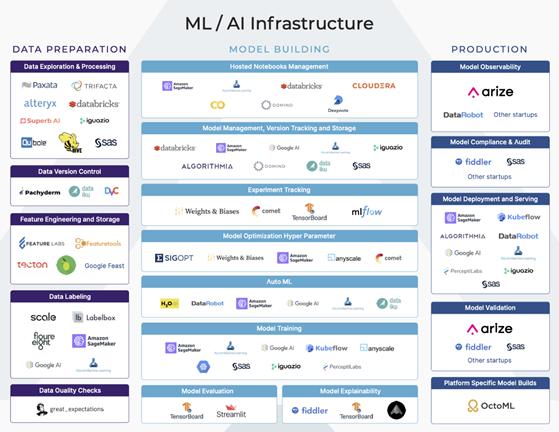
機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)平臺圖
特征探索和選擇
數(shù)據(jù)科學(xué)家探索各種數(shù)據(jù)輸入選項(xiàng)以選擇特征,是該實(shí)驗(yàn)過程的一部分。特征選擇是為機(jī)器學(xué)習(xí)模型查找特征輸入的過程。
對于新模型,理解可用的數(shù)據(jù)輸入、輸入的重要性以及不同特征之間的關(guān)系可能是一個漫長的過程。在這里,可以對更易解釋的模型、更短的訓(xùn)練時間、特征獲取的成本以及過度擬合的減輕做出許多決策。找出正確且合適的特征是一個連續(xù)不斷的迭代過程。
- 在特征提取方面的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)公司有:Alteryx/ Feature實(shí)驗(yàn)室、Paxata(DataRobot)。
模型管理
數(shù)據(jù)科學(xué)家可以嘗試多種建模方法。對于某些任務(wù),一些類型的模型比其他模型更適用(例如,基于樹的模型解釋性更佳)。
作為構(gòu)思階段的一部分,該模型是監(jiān)督、無監(jiān)督、分類或回歸等都是顯而易見的。但建模方法、超參數(shù)以及特征的選擇取決于實(shí)驗(yàn)。
一些自動機(jī)器學(xué)習(xí)(AutoML)平臺會嘗試附帶各種參數(shù)的不同模型,這有助于建立基線方法。即使手動完成,探索各種選項(xiàng)也可以為模型構(gòu)建者提供有關(guān)模型可解釋性的見解。
實(shí)驗(yàn)跟蹤
盡管各種類型的模型之間有許多優(yōu)點(diǎn)和折衷點(diǎn),但通常來說,此階段涉及許多實(shí)驗(yàn)。許多平臺可以跟蹤這些實(shí)驗(yàn)、建模依賴和模型存儲。這些功能可被大致歸為模型管理。
一些平臺主要關(guān)注實(shí)驗(yàn)跟蹤。其他一些具有訓(xùn)練或服務(wù)組件的公司擁有模型管理組件,用于比較各種模型的性能,跟蹤訓(xùn)練/測試數(shù)據(jù)集,調(diào)整和優(yōu)化超參數(shù),存儲評估指標(biāo)以及實(shí)現(xiàn)詳細(xì)的沿襲和版本控制。
與用于軟件的Github相似,這些模型管理平臺應(yīng)能實(shí)現(xiàn)版本控制、歷史沿襲和可重復(fù)性。
各種模型管理平臺之間的折衷在于集成成本。一些更輕量級的平臺雖然僅提供實(shí)驗(yàn)跟蹤,但可以輕松地與當(dāng)前環(huán)境集成,并導(dǎo)入到數(shù)據(jù)科學(xué)notebook中。其他一些平臺則需要進(jìn)行更繁重的集成,并且需要模型構(gòu)建者轉(zhuǎn)移至其平臺上,以便進(jìn)行集中的模型管理。
在機(jī)器學(xué)習(xí)工作流程的這一階段,數(shù)據(jù)科學(xué)家通常要花時間在notebook中建立、訓(xùn)練模型,將模型權(quán)重存儲在模型庫中,然后在驗(yàn)證集上評估模型結(jié)果。
這一階段有許多平臺提供訓(xùn)練所需的計(jì)算資源。根據(jù)團(tuán)隊(duì)存儲模型對象的不同方式,模型還具備許多存儲選項(xiàng)。
- 機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)AutoML:H20、SageMaker、DataRobot、Google Cloud ML、MicrosoftML
- 模型管理方面的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)公司:Domino Data Labs、SageMaker
- 超參數(shù)選項(xiàng)方面的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)公司:Sigopt、Weightsand Biases、SageMaker
- 實(shí)驗(yàn)跟蹤方面的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)公司:權(quán)重和偏差、Comet ML、MLFlow、Domino、Tensorboard
模型評估
一旦實(shí)驗(yàn)?zāi)P驮诰哂羞x定特征的訓(xùn)練數(shù)據(jù)集上經(jīng)過訓(xùn)練,就可以在測試集上進(jìn)行評估了。
在這一階段,數(shù)據(jù)科學(xué)家試圖了解模型的性能以及需要改進(jìn)的地方。一些更高級的機(jī)器學(xué)習(xí)團(tuán)隊(duì)擁有自動回測框架,可供其利用歷史數(shù)據(jù)來評估模型性能。
每個實(shí)驗(yàn)都試圖擊敗或超越基準(zhǔn)模型的性能,并考慮如何對計(jì)算成本、可解釋性和歸納能力做出權(quán)衡。在一些更規(guī)范的行業(yè)中,此評估過程還可以包括外部審核員執(zhí)行的合規(guī)性和審核,以確保模型的可重復(fù)性、性能和需求。
- 用于模型評估的機(jī)器學(xué)習(xí)基礎(chǔ)工具/架構(gòu):Fiddler AI、Tensorboard、Stealth Startups
- 用于試生產(chǎn)驗(yàn)證的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu):Fiddler AI、ArizeAI
管理以上所有任務(wù)的平臺
許多以AutoML或模型構(gòu)建為中心的公司只選定一個平臺,用以處理一切事物。因此許多平臺爭相成為公司在數(shù)據(jù)準(zhǔn)備、模型構(gòu)建和生產(chǎn)中使用的唯一人工智能平臺,這樣的公司有DataRobot、H20、SageMaker等。
該集合分為低代碼解決方案和以開發(fā)人員為中心的解決方案。Datarobot公司似乎專注于無代碼/低代碼選項(xiàng),該選項(xiàng)允許商務(wù)智能(businessintelligence, BI)或財(cái)務(wù)(Finance)團(tuán)隊(duì)從事數(shù)據(jù)科學(xué)項(xiàng)目。
這與SageMaker和H20公司形成鮮明對比,它們似乎迎合了當(dāng)今更為常見的數(shù)據(jù)科學(xué)組織——數(shù)據(jù)科學(xué)家或開發(fā)者第一團(tuán)隊(duì)。
這兩種情況下的市場都很大,并且可以共存,但值得注意的是,并非所有的機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)公司都向相同的人或團(tuán)隊(duì)出售產(chǎn)品。
近期,該領(lǐng)域中的許多新成員可以被視為機(jī)器學(xué)習(xí)基礎(chǔ)架構(gòu)食物鏈中特定部分的優(yōu)秀解決方案。比較好的模擬將是軟件工程領(lǐng)域,其軟件解決方案GitHub、集成開發(fā)環(huán)境(IDE)以及生產(chǎn)監(jiān)控并非都是相同的端到端系統(tǒng)。
它們是不同的軟件,這一點(diǎn)并非空穴來風(fēng),它們提供了迥然不同的功能,并且具有明顯的區(qū)別。
挑戰(zhàn)
與軟件開發(fā)并行不同的是,由于缺乏對模型所訓(xùn)練數(shù)據(jù)的版本控制,模型的可重復(fù)性通常被視為一個挑戰(zhàn)。
在理解模型的性能方面存在許多挑戰(zhàn)。如何比較實(shí)驗(yàn)并確定哪種模型版本是性能和折衷的優(yōu)質(zhì)平衡?稍差的模型是一種折衷方案,但它更易于解釋。一些數(shù)據(jù)科學(xué)家使用內(nèi)置的模型可解釋性特征或使用SHAP/ LIME,來探索特征的重要性。
另一性能挑戰(zhàn)是不知道實(shí)驗(yàn)階段的模型性能如何轉(zhuǎn)化到現(xiàn)實(shí)世界中。
通過確保訓(xùn)練數(shù)據(jù)集中的數(shù)據(jù)是模型在生產(chǎn)中可能看到的數(shù)據(jù)的代表性分布,以防止過度擬合訓(xùn)練數(shù)據(jù)集,可以很大程度地緩解這種情況。這是交叉驗(yàn)證和回測框架發(fā)揮作用之處。
接下來發(fā)生了什么?
對數(shù)據(jù)科學(xué)家來說,確定何時將模型投入生產(chǎn)的標(biāo)準(zhǔn)是很重要的。如果生產(chǎn)環(huán)境中已部署了預(yù)先存在的模型,則可能是新版本的性能更高的時候。無論如何,設(shè)置標(biāo)準(zhǔn)對于將實(shí)驗(yàn)轉(zhuǎn)移至實(shí)際環(huán)境中至關(guān)重要。
一旦模型受過訓(xùn)練,模型圖像/權(quán)重將存儲在模型庫中。這時,負(fù)責(zé)將模型部署到生產(chǎn)中的數(shù)據(jù)科學(xué)家或工程師通常可以獲取模型并用于服務(wù)。
在一些平臺上,該部署甚至可以更簡單,并且可以使用外部服務(wù)能調(diào)用的RESTAPI來配置已部署的模型。




















