













我為什么用ES做Redis監控,不用Prometheus或Zabbix?
Redis 當下很流行,也很好用,無論是在業務應用系統,還是在大數據領域都有重要的地位;但 Redis 也很脆弱,用不好,問題多多。
圖片來自 Pexels
2012 年以前都是以 Memcached 為主,之后轉到 Redis 陣營,經歷過單實例模式、主從模式、哨兵模式、代理模式,集群模式,真正公司層面用得好的很少,對于 Redis 掌控都很片面,導致實際項目中問題不少。
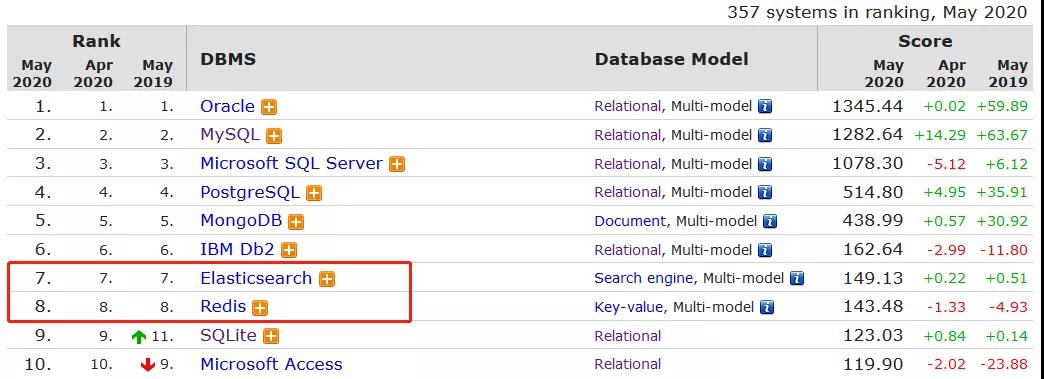
Redis 熱度排名
Redis 要想用得好,需要整體掌握三個層面:
- 開發層面
- 架構層面
- 運維層面
其中架構與運維至關重要,多數中小型企業僅在開發層面滿足常用功能,數據規模稍微大些,業務復雜度高些,就容易出現各種架構與運維問題。
本文主旨是探討 Redis 監控體系,目前業界當然也有很多成熟的產品,但個人覺得都很常規,只做到一些粗粒度的監控,沒有依據業務需求特點因地制宜去細化,從而反向的提供架構開發優化方案。
本文內容將圍繞如下幾個問題展開討論:
- Redis 監控體系有哪些方面?
- 構建 Redis 監控體系我們做了哪些工作?
- Redis 監控體系應該細化到什么程度?
- 為什么使用 ELK 構建監控體系?
需求背景
項目描述
公司業務范圍屬于車聯網行業,有上百萬級的真實車主用戶,業務項目圍繞車主生活服務展開,為了提高系統性能,引入了 Redis 作為緩存中間件。
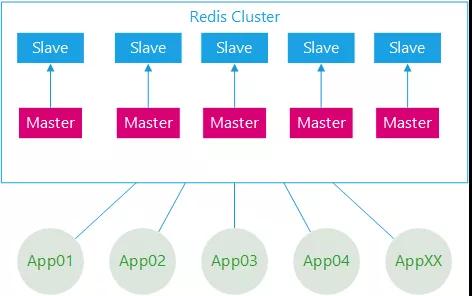
Redis 集群架構與應用架構示意圖
具體描述如下:
- 部署架構采用 Redis-Cluster 模式。
- 后臺應用系統有幾十個,應用實例數超過二百個。
- 所有應用系統共用一套緩存集群。
- 集群節點數幾十個,加上容災備用環境,節點數量翻倍。
- 集群節點內存配置較高。
問題描述
系統剛開始關于 Redis 的一切都很正常,隨著應用系統接入越來越多,應用系統子模塊接入也越來越多,開始出現一些問題,應用系統有感知,集群服務端也有感知。
如下描述:
- 集群節點崩潰。
- 集群節點假死。
- 某些后端應用訪問集群響應特別慢。
其實問題的根源都是架構運維層面的欠缺,對于 Redis 集群服務端的運行監控其實很好做,本身也提供了很多直接的命令方式。
但只能看到服務端的一些常用指標信息,無法深入分析,治標不治本,對于 Redis 的內部運行一無所知。
特別是對于業務應用如何使用 Redis 集群一無所知:
- Redis 集群使用的熱度問題?
- 哪些應用占用的 Redis 內存資源多?
- 哪些應用占用 Redis 訪問數最高?
- 哪些應用使用 Redis 類型不合理?
- 應用系統模塊使用 Redis 資源分布怎么樣?
- 應用使用 Redis 集群的熱點問題?
監控體系
監控的目的不僅僅是監控 Redis 本身,而是為了更好的使用 Redis。
傳統的監控一般比較單一化,沒有系統化,但對于 Redis 來說,個人認為至少包括:
- 服務端
- 應用端
- 服務端與應用端聯合分析
服務端
服務端首先是操作系統層面,常用的 CPU、內存、網絡 IO,磁盤 IO,服務端運行的進程信息等
Redis 運行進程信息,包括服務端運行信息、客戶端連接數、內存消耗、持久化信息 、鍵值數量、主從同步、命令統計、集群信息等;
Redis 運行日志,日志中會記錄一些重要的操作進程,如運行持久化時,可以有效幫助分析崩潰假死的程序。
應用端
應用端、獲取應用端使用 Redis 的一些行為,具體哪些應用哪些模塊最占用 Redis 資源、哪些應用哪些模塊最消耗 Redis 資源、哪些應用哪些模塊用法有誤等。
聯合分析
聯合分析結合服務端的運行與應用端使用的行為,如:一些造成服務端突然阻塞的原因,可能是應用端設置了一個很大的緩存鍵值,或者使用的鍵值列表,數據量超大造成阻塞。
解決方案
為什么會選擇 Elastic-Stack 技術棧呢?
多數的第三方只監控一些指標,對于明細日志還是采用 ELK(Elasticsearch、Logstash、Kibana),也就是說用第三方監控指標之后,還得再搭建一個 ELK 集群看明細日志。
再就是說 Elastic-Stack 技術棧整合的優勢,指標也可以、日志文件也可以,從采集開始到存儲、到最終報表面板都整合得非常好,門檻很低。
下面詳細聊聊我們具體怎么做的,做了哪些工作?
服務端系統
Elastic-Stack 家族有 MetricBeat 產品,支持系統層面的信息收集,簡單的配置下 Elastic 集群地址和系統指標模塊即可上線,并且會在 Kibana 中創建已有的系統監控面板,非常簡單快速,一般運維就可以搞定。
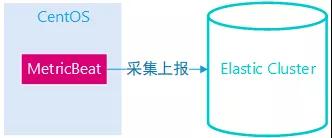
MetrciBeat 示意圖
系統指標信息收集配置樣例如下:

服務端集群
收集 Redis 集群運行信息,業界通常做法都是采用 Redis 提供的 info 命令,定期收集。
info 獲取的信息包括如下:
- server:Redis 服務器的一般信息
- clients:客戶端的連接部分
- memory:內存消耗相關信息
- persistence:RDB 和 AOF 相關信息
- stats:一般統計
- replication:主/從復制信息
- cpu:統計 CPU 的消耗 command
- stats:Redis 命令
- 統計 cluster:Redis 集群信息
- keyspace:數據庫的相關統計
Elastic-Stack 家族的 MetricBeat 產品也支持 Redis 模塊,也是采用 info 命令獲取的。
但是有一些實現的局限性,如下描述:
- Redis 集群的主從關系信息,MetricBeats 表達不出來。
- Redis 集群的一些統計信息,永遠是累計增加的,如命令數,如果要獲取命令數的波峰值,則無法得到;
- Redis 集群狀態信息變化,MetricBeats 是無法動態的,如集群新增節點、下線節點等。
所以這里參考了 CacheCloud 產品(搜狐團隊開源),我們自定義設計開發了 Agent,定時從 Redis 集群采集信息,并在內部做一些統計數值的簡單計算,轉換成 Json,寫入到本地文件,通過 Logstash 采集發送到 Elasticsearch。

Redis 服務端運行信息采集架構示意圖
服務端日志
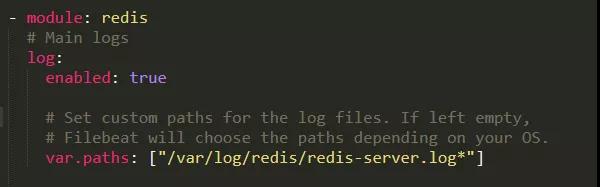
Redis 服務端運行日志采集很簡單,直接通過 Elastic-Stack 家族的 Filebeat 產品,其中有 Redis 模塊,配置一下 Elastic 服務端,日志文件地址即可。

服務端日志采集過程
Redis 運行日志采集配置:
應用端
應用端信息采集是整個 Redis 監控體系最重要的部分,也是實現最麻煩、鏈路最長的。
首先是修改 Jedis(技術棧 Java)源碼,增加埋點代碼,重新編譯并引用到應用項目中,應用端對于 Redis 集群的任何命令操作,都會被捕捉,并記錄下關鍵信息,之后寫入到本地文件。

Redis 應用端行為采集架構圖
應用端采集的數據格式如下:

應用端采集的數據案例
①Jedis 修改
Jedis 改造記錄的信息如下:
- r_host:訪問 Redis 集群的服務器地址與端口,其中某一臺 ip:port。
- r_cmd:執行命令類型、如 get、set、hget、hset 等各種。
- r_start:執行命令開始時間。
- r_cost:時間消耗。
- r_size:獲取鍵值大小或者設置鍵值大小。
- r_key:獲取鍵值名稱。
- r_keys:鍵值的二級拆分,數組的長度不限制。這里有必要強調一下,所有應用系統共用的是一套集群,所以應用系統的鍵值都是有規范的,按照特殊符號分割,如:"應用名稱_系統模塊_動態變量_xxx“,主要便于我們區分。
在 Jedis 改造有幾處地方,如下:
- 類 Connection.java 文件,統計開始,記錄命令執行開始時間;統計結束,記錄命令結束時間、時間消耗等,并寫入到日志流中。
- 類 JedisClusterCommand 文件,獲取鍵的地方 key,方便之后分析應用鍵的行為。
在類 Connection.java 文件中有兩處:
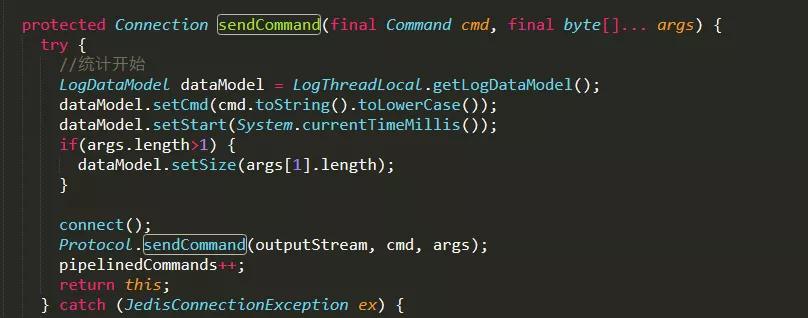
類Connection.java 文件埋點代碼的地方
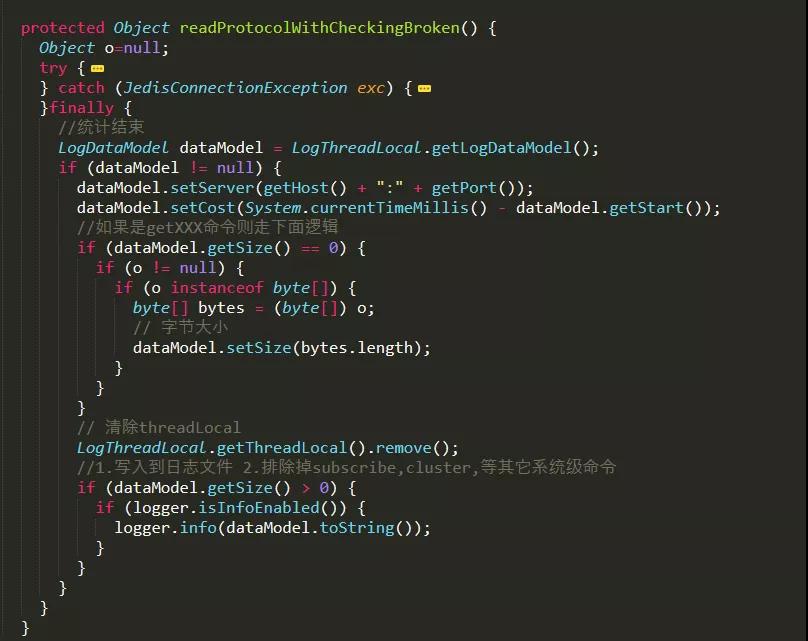
類 Connection.java 文件埋點代碼的地方
類 JedisClusterCommand 文件埋點代碼 .java 文件中有 1 處:
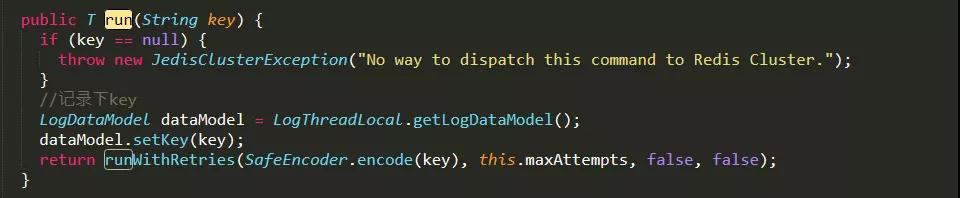
類 JedisClusterCommand 文件埋點代碼
②Logback 修改
應用端都會使用 Logback 寫入日志文件,同時為了更加精準,應用端寫入日志時還需要獲取應用端的一些信息,如下:
- app_ip:應用端部署在服務器上的 IP 地址。
- app_host:應用端部署在服務器上的服務器名稱。
自定義一個 Layout,自動獲取應用端的 IP 地址與服務器名稱:

自定義 Logback 的 Layout
③App 配置
App 配置屬于最后收尾工作,主要是輸出埋點的日志數據,配置日志 logback.xml 文件即可:

配置應用端日志文件 logback.xml
④日志采集
應用端日志采集采用 Logstash,配置日志目錄,指向 Elastic 集群,這樣整體的監控日志采集部分就結束了。
日志分析
Redis 服務端的日志分析比較簡單,常規的一些指標而已,創建好關鍵的圖表,容易看出問題。重點討論應用端的日志分析。
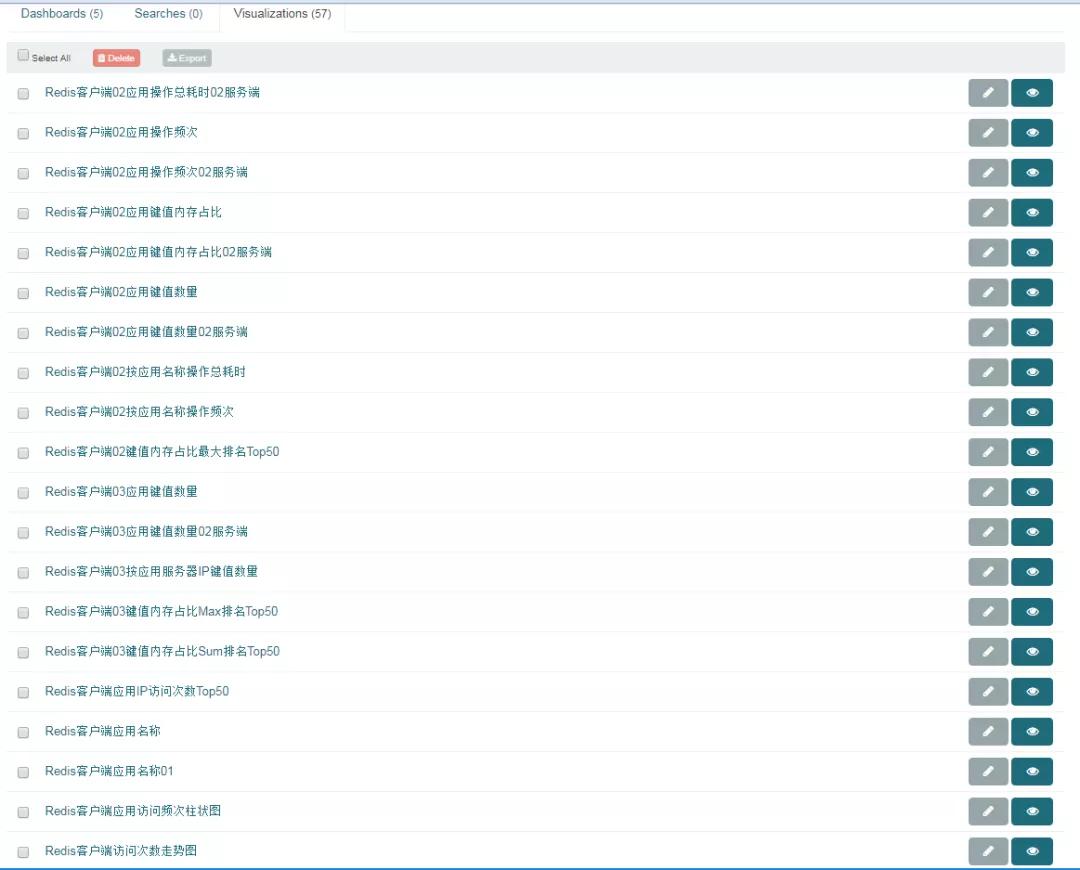
應用端使用 Redis 一些行為圖表
ELK 監控體系上線之后,我們連續觀察分析兩周,獲得了一些監控成果,如:
- 應用端部分鍵值太大,居然超過 1MB,這種鍵值訪問一次消耗時間很大,會嚴重造成阻塞。
- 部分應用居然使用 Redis 當成數據庫使用。
- 有將 List 類型當成消息隊列使用,一次存取幾十萬的數據。
- 某些應用對于集群的操作頻次特別高,幾乎占用了一半以上。
- 還有很多,就不一一描述了。
后續方案
監控體系相當于架構師的眼睛,有了這個,Redis 方面的優化改造方案就很好制定了:
應用端、誤用的使用全部要改掉。
服務端,按照應用的數據,進行一些拆分,拆分出一些專用的集群,特定為一些應用使用或者場景。
開發者,后續有新業務模塊需要接入 Redis 需要告知架構師們評審。
結語
監控體系項目前后經歷過幾個月,服務端部分短期內就完成的,應用端是隨著應用發布逐步完成的。上線完成之后又經歷幾周的跟蹤分析,才確定下來整體的優化方案。
監控體系本身并不是為了監控,而是發現問題、預見問題,最終提前解決問題,監控做得好,下班下得早。
Redis 集群是個好東西,完全掌握還是需要很長的時間,特別是架構、運維層面,如果沒有,請做好監控。
作者:李猛
簡介:數據技術專家,Elastic-Stack 產品深度用戶,ES 認證工程師,對 Elastic-Stack 開發、架構、運維有深入體驗;實踐過多種 ES 項目,最暴力的大數據分析應用,最復雜的業務系統應用。
編輯:陶家龍
出處:轉載自微信公眾號 DBAplus 社群(ID:dbaplus),本文根據李猛老師在〖deeplus 直播第 220 期〗線上分享演講內容整理而成。


















