













這款NLP神器火了!關鍵詞提取、結果可視化,從小白進階大神
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
如何快速優雅地處理你的NLP數據集?
試試這款號稱「從小白到大神」的Texthero的工具包。
不僅編寫界面友好美觀,而且功能全面,預處理、表征、可視化樣樣精通,在Reddit上17個小時內就獲得了近1.1k的熱度。
連剛脫機的NLP程序猿看了都想與數據集再戰幾回:

下面是Texthero的使用界面。
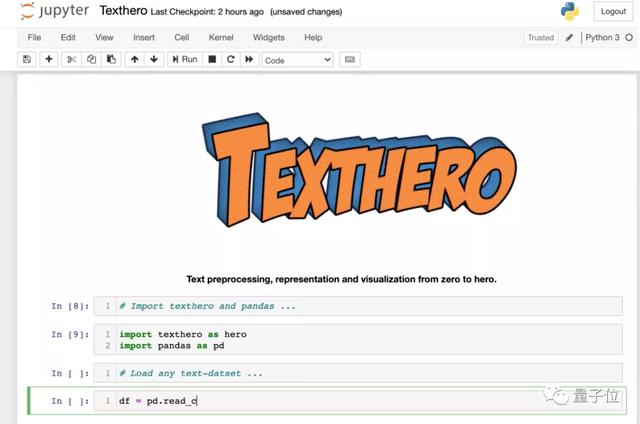
△ 優雅美觀的NLP數據處理界面
事實上,Texthero的優雅絕不僅僅在于界面的友好,最關鍵的是,它省略了大量重復性代碼編寫工作。
只需要幾行代碼,Texthero就能幫你完成想要的數據預處理、表征、可視化等操作,極大程度上解放了你的雙手。
來看看Texthero進行數據預處理、各種算法后的可視化效果。
效果展示
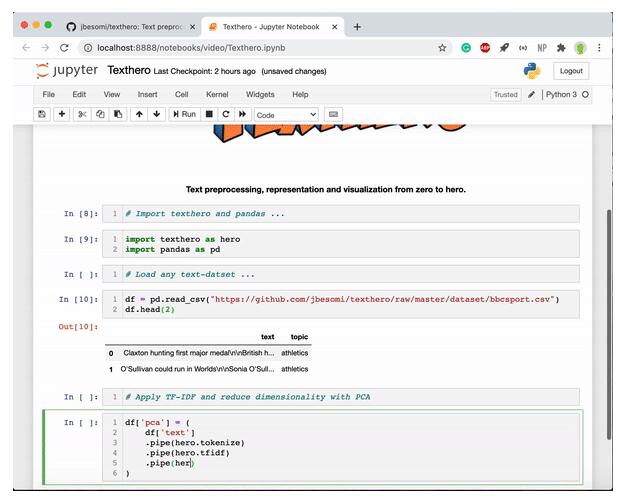
首先,進行文本清理,然后采用TF-IDF算法進行特征表示,并對此可視化:

PCA降維后的效果duangduang的:
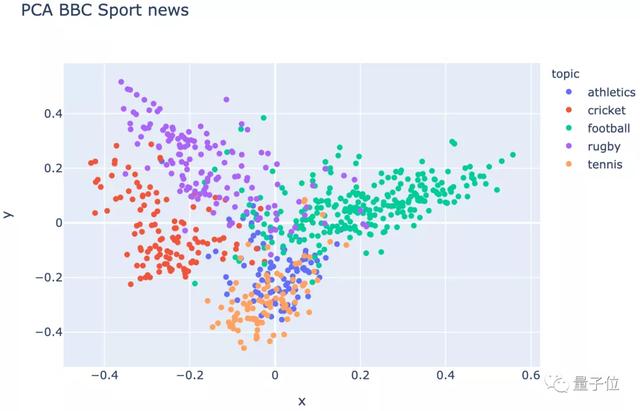
△ 進行文本清理和TF-IDF表征后的可視化效果
這不是你想要的?
那么,除了預處理和表征外,試試加上K均值聚類算法,并進行可視化:

效果如下:
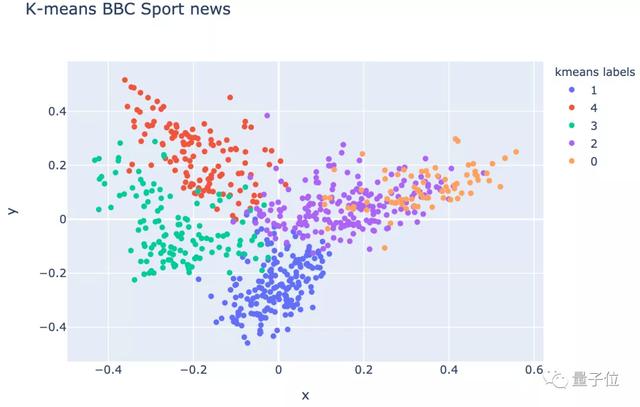
△ 進行預處理、表征和K均值聚類算法后的數據效果
經過K均值聚類算法處理后的結果一目了然。
不僅設計友好,加載代碼后,結果會生成在在同一個界面上,整體邏輯流程顯得非常明了。
△ 使用效果
從展示界面來看,Texthero只需要編寫少量代碼,就能得到你想要的結果,為數據處理省去了不少時間。
事實上,只要掌握基本使用邏輯,萌新也能快速上手這款NLP數據處理神器。
使用指南
pip一下texthero后(或從GitHub上直接下載工具包,文末附代碼鏈接),采用import導入它和pandas:

之后,加載你需要處理的文本信息數據集(這里采用了BBC sport數據庫舉例):

然后就可以開始使用了:
預處理
如果需要進行快速的數據預處理操作,直接使用「文本清理」就行:

當然,如果你需要對文本信息進行更細節的處理操作,例如將所有標點符號替換成空格、或者刪除<>中的所有內容,Texthero也提供了非常完備的工具包,以供使用。

△ 光是預處理欄目就有這么多工具
再也不用編寫一大堆代碼,專門清理文本中的冗余數據了。
表征
同樣,如果需要進行TF-IDF算法特征表示的話,同樣只需要幾行代碼就能實現:

一鍵出結果:
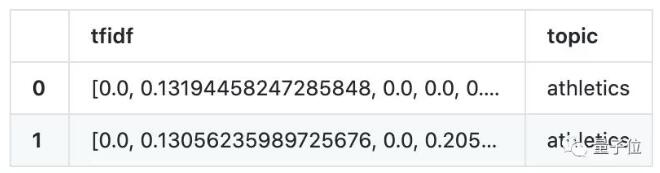
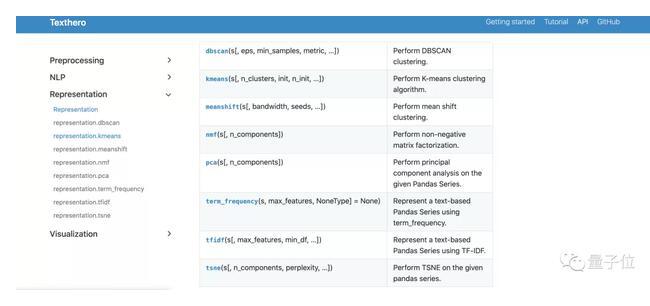
如果需要更多的算法,這里也有meanshift、NMF等算法可以選用,每種算法基本都集成在一行代碼中,你想要的這里都有。
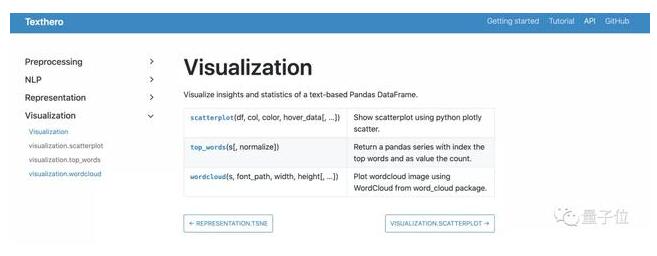
可視化
而在可視化方向上,Texthero同樣展現出了強大的能力,這里以PCA降維后的結果進行展示:

可視化界面非常清晰:

同樣,可視化也可以自定義顏色、界面展示效果等,只需要一點Python的知識就能快速使用。
這么方便的NLP數據處理工具包,趕緊用起來~
傳送門
代碼鏈接:
https://github.com/jbesomi/texthero
項目鏈接:
https://texthero.org/
















