Redis的跳躍表確定不了解下嗎?
本文轉載自微信公眾號「 學習Java的小姐姐」,作者學習Java的小姐姐0618。轉載本文請聯系學習Java的小姐姐公眾號。
前言
hello,大家好,前面幾周我們一起看了Redis底層數據結構,如動態字符串SDS,雙向鏈表Adlist,字典Dict,如果有對Redis常見的類型或底層數據結構不明白的請看上面傳送門。
今天我們來看下ZSET的底層架構,如果不知道ZSET是什么的,可以看上面傳送門第一篇。簡單來說,ZSET是Redis提供的根據數據和分數來判斷其排名的數據結構。最常見的就是微信運動的排名,每個用戶對應自己的步數,每天晚上可以給出用戶的排名。
有小伙伴可能會想,如果是實現排名的話,各種排序方法都可以實現的,沒必要引入Redis的ZSET結構啊?
當然,如果是采用排序方法的話,是可以實現相同功能的,但是代碼里面需要硬編碼,會添加工作量,還會提供代碼的Bug哦,哈哈哈。而且Redis的底層是C實現的,直接操作內存,速度也會比Java方法實現提升。
綜上,使用Redis的ZSET結構,好處多多。那話不多說,開始把。在正式開始之前,我們需要引入下跳躍表的概念,其是ZSET結構的底層實現。以下可能有點枯燥,我盡量說的簡單點哈。(一定要看哦,這寫的太累了哈)
什么是跳躍表?
對于數據量大的鏈表結構,插入和刪除比較快,但是查詢速度卻很慢。那是因為無法直接獲取某個節點,需要從頭節點開始,借助某個節點的next指針來獲取下一節點。即使數據是有序排放的,想要查詢某個數據,只能從頭到尾遍歷變量,查詢效率會很低,時間復雜度為O(n)。
如果我們需要快速查詢鏈表有啥辦法呢?有同學說用數組存放,但是如果不改數據結構呢?
我們可以先想想在有序數組結構中有二分法,每次將范圍都縮小一半,這樣查詢速度提升了很多,那么在鏈表中能不能也使用這種思想。
這就到了今天講的主角——跳躍表。(一點也生硬的引出概念😊)
步驟一 新建有序單項鏈表
先看下圖有序單向鏈表,存放了1,2,3,4,5,6,7這7個元素。

步驟二 抽取二級索引節點
我們可以在鏈表中抽取部分節點,下圖抽取了1,3,5,7四個節點,也就是每兩個節點提取了一個節點到上級,抽取出來的叫做索引。
注意不是每次都能抽取到這么完美,這其實就跟拋硬幣一樣,每個硬幣的正反兩面的概率是一樣的,都是1/2。當數據量小的時候,正反的概率可能差別較大。但是隨著數據量的加大,正反的概率越來越接近于1/2。類比過來是一個意思,每個節點的機會都是一樣的,要么停留原級,要么提取到上級,概率都是1/2。但是隨著節點數量的增加,抽取的節點越來越接近與1/2。

步驟三 抽取三級索引節點
我們可以在鏈表中抽取部分節點,下圖抽取了1,5兩個節點,也就是每兩個節點提取了一個節點到上級,抽取出來的叫做索引。
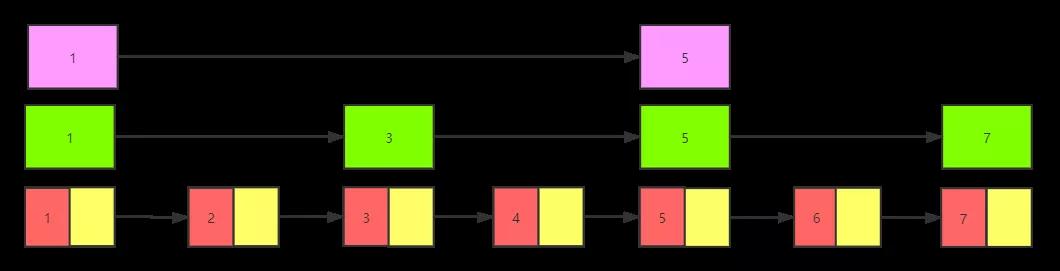
步驟四 類二分法查詢
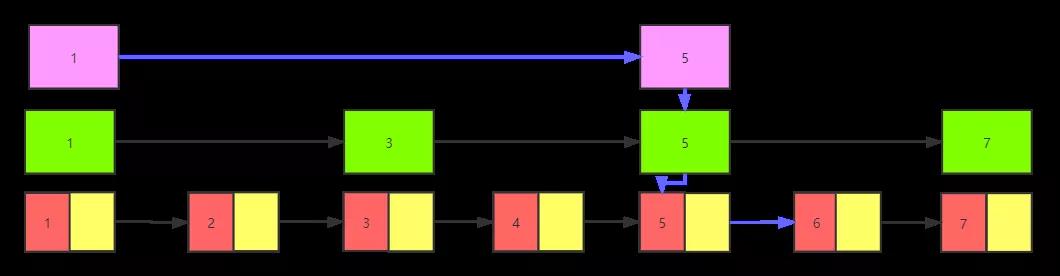
我們假設要查找值為6的節點,先從三級索引開始,找到值為1的節點,發現比5小,根據值為1節點的next指針,找到值為5的節點,5后面沒有其他的三級索引啦。
于是順著往下找,到了二級索引,根據值為5的節點的next指針找到值為7的節點,發現比6小,說明要找到的節點6在此范圍內。
再接著到了一級索引位置,根據值為5的節點next指針指向值為6的節點,發現是想要查詢的數據,所以查詢過程結束。
根據上面的查詢過程(下圖的藍色連線),我們發現其采用的核心思想是二分法,不斷縮小查詢范圍,如果在上層索引找到區間,則順延深入到下一層找到真正的數據。
總結
從上面的整個過程中可以看出,數據量小的時候,這種拿空間換時間,消耗內存方法的并不是最優解。所以Redis的zset結構在數據量小的時候采用壓縮表(這邊先放著哈,下下篇說,立個flag),數據量大的時候采用跳躍表。
像這種鏈表加多級索引的結構,就是跳躍表。這名字起的形象,過程是跳躍著來查詢的。旋轉跳躍,我閉著眼,bgm響起來。
Redis中跳躍表圖解
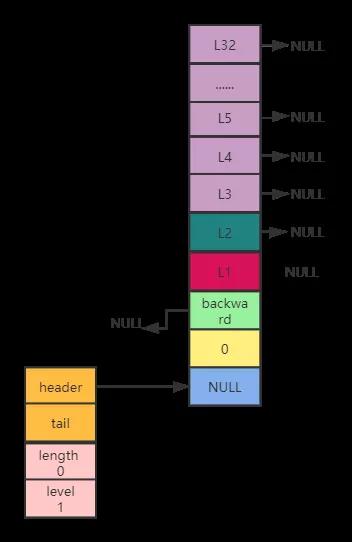
下圖簡單來說是對跳躍表的改進和再封裝,首先引入了表頭的概念,這與雙向鏈表,字典結構一樣,都是對數據的封裝,因為他們都是采用的指針,而指針必然導致在計算長度,獲取最后節點的數據問題上會產生查詢太慢的性能問題,所以封裝表頭是為了在這些問題上提升速度,浪費的只是添加,刪除等操作的時間,與此對比,是可以忽略的。
其次是引入管理所有節點的層數數組,我們可以看到有32層,即32個數組,這和后面的數據節點結構是一樣的。引入它是為了便于直接根據此數組的層數定位到每個元素。
再其次是數據節點的每個level都有層級和span(也就是下圖箭頭指針上的數字,其是為了方便統計兩個節點相距多少長度)。
最后就是數據節點的后退指針backward,引入目的是Level數組只有前指針,即只能指向下一個節點地址,而后退指針是為了能往回找節點。
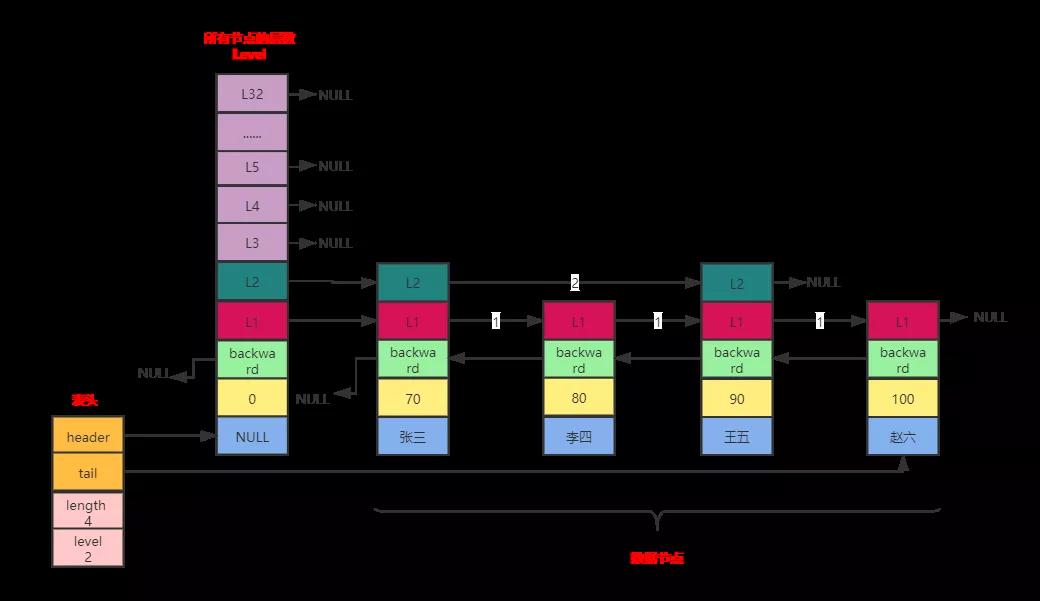
上圖主要分為3大塊:(這邊大致看下就行,下面將對各模塊進行代碼詳細解釋)
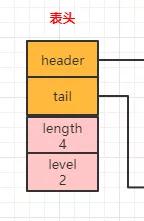
表頭
主要包括四個屬性,分別是頭指針header,尾指針tail,節點長度length,所有節點的最大level。
header:指向跳躍表的表頭節點,通過這個指針地址可以直接找到表頭,時間復雜度為O(1)。
tail:指向跳躍表的表尾節點,通過這個指針可以直接找到表尾,時間復雜度為O(1)。
length:記錄跳躍表的長度,即不包含表頭節點,整個跳躍表中有多少個元素。
level:記錄當前跳躍表內,所有節點層數最大的level(排除表頭節點)。
管理所有節點層數level的數組
其對象值為空,level數組為32層,目的是為了管理真正的數據節點。關于具體的level有哪些屬性放在數據節點來說。
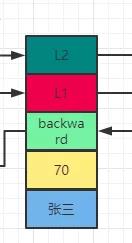
數據節點
主要包括四個屬性對象值obj,分數score,后退指針backward和level數組。每個數據的Level數組有多少層,是隨機產生的,這跟上面說過的跳躍表是一樣的。
成員對象obj:真正的實際數據,每個節點的數據都是唯一的,但是節點的分數可能相同。兩個相同分數的節點是按照成員對象在字典中的大小進行排序的,成員對象較小的節點會排在前面,成員對象較大的節點會排在后面。
分數score:各個節點中的數字是節點所保存的分數,在跳躍表中,節點按各自所保存的分數從小到大排列。
后退指針backward:用于從表尾向表頭遍歷,每個節點只有一個后退指針,即每次只能后退一步。
層級level:節點中用1,2,3等字樣標記節點的各個層,L1代表第一層,L2代表第二層,L3代表第三層,并以此類推。
跳躍表的定義
表頭結構zskiplist
- typedef struct zskiplist {
- //表頭的頭指針header和尾指針tail
- struct zskiplistNode *header, *tail;
- //一共有多少個節點length
- unsigned long length;
- // 所有節點最大的層級level
- int level;
- } zskiplist;
具體數據節點zskiplistNode
- //跳表的具體節點
- typedef struct zskiplistNode {
- sds ele; //具體的數據,對應張三
- double score;//分數,對應70
- struct zskiplistNode *backward;//后退指針backward
- //層級數組 struct zskiplistLevel {
- struct zskiplistNode *forward;//前進指針forward
- unsigned int span;//跨度span
- } level[];
- } zskiplistNode;
跳躍表的實現(源碼分析)
redis關于跳躍表的API都定義在t_zset.c文件中。
千萬不要看到源碼分析就跑開了,一定要看哦。
創建跳躍表
創建空的跳躍表,其實就是創建表頭和管理所有的節點的level數組。首先,定義一些變量,嘗試分配內存空間。其次是初始化表頭的level和length,分別賦值1和0。接著創建管理所有節點的Level的數組,是調用zslCreateNode函數,輸入參數為數組大小宏常量ZSKIPLIST_MAXLEVEL(32),分數為0,對象值為NULL。(此為跳躍表得以實現重點)。再接著就是為此數組每個元素的前指針forword和跨度span初始化。最后初始化尾指針并返回值。
可以參照下面的圖解和源碼:
- //創建一個空表頭的跳躍表
- zskiplist *zslCreate(void) {
- int j;
- zskiplist *zsl;
- //嘗試分配內存空間
- zsl = zmalloc(sizeof(*zsl));
- //初始化level和length
- zsl->level = 1;
- zsl->length = 0;
- //調用下面的方法zslCreateNode,傳入的參數有數組長度ZSKIPLIST_MAXLEVEL 32
- //分數0,對象值NuLL
- //這一步就是創建管理所有節點的數組
- //并且設置表頭的頭頭指針為此對象的地址
- zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
- //為這32個數組賦值前指針forward和跨度span
- for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
- zsl->header->level[j].forward = NULL;
- zsl->header->level[j].span = 0;
- }
- //設置尾指針
- zsl->header->backward = NULL;
- zsl->tail = NULL;
- //返回對象
- return zsl;
- }
- zskiplistNode *zslCreateNode(int level, double score, sds ele) {
- zskiplistNode *zn =
- zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
- zn->score = score;
- zn->ele = ele;
- return zn;
- }
插入節點
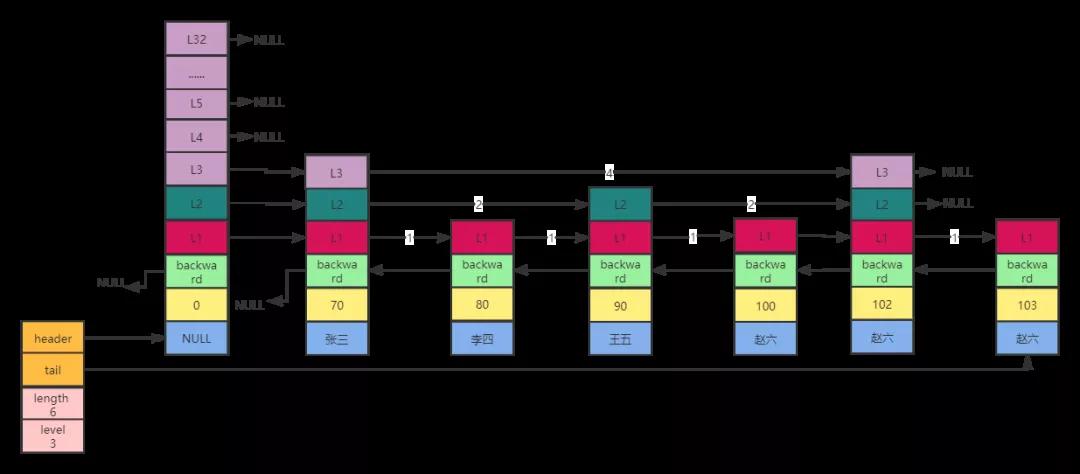
比如有下圖6個元素,需要插入值為趙六,分數為101的元素,我們大致想一想,大致的步驟包括找到要插入的位置,新建一個數據節點,然后調整與之相關的頭尾指針的level數組。那就看看redis咋做的,和我們想的一樣不一樣呢?
噔噔噔噔,答案揭曉。當然了大框架是相同的。
正文開始了:(先來圖片)

1.遍歷管理所有節點的level數組,從最大的level開始,即3,挨個對比值,如果有分數比他大的值或者分數相同,但是數據的值比他大,記錄到數組里面,同時記錄跨度。
這樣說太抽象了。拿上圖舉個例子,從表頭的level即3開始,首先到張三的L3,發現分數70,比目標分數101小跳過,根據其前指針找到趙六的L3,發現分數102,比目標分數101大,將趙六L3記錄在待更新數組update中,同時記錄跨度span為4。接著到下一層,張三的L2層,發現分數70比目標分數101小跳過,根據前指針找到王五的L2,發現分數90,比目標分數101小跳過,根據前指針找到趙六的L2,發現分數102比目標分數101大,將趙六的L2記錄到待更新數組update中,同時記錄跨度span為2。最后到下一層,張三的L1層,邏輯和剛才一樣的,也是記錄趙六的L1層和跨度span為1。
2.為新節點隨機生成層級數level(通過位運算),如果生成的level大于目前level最大值3,則將將大于部分挨個遍歷,并將跨度等信息記錄到上面update表中。
比如,新節點生成的level為5,目前level最大值為3,說明這個節點只會有一個,并且跨越了之前的所有節點,那么我們將從第四層和第五層都遍歷下,記錄到待更新數組update中。
3.準備工作都做好了,找到了該節點將插入到哪一位置,處于哪一層,每層對應的跨度是多少,下面就要新增數據節點了。把上兩步的信息都添加到新節點上,并且調整位置前后指針即可。
4.最后就是一些收尾工作,比如修改表頭的層級level,節點大小length和尾指針tail等屬性。
綜上,整個流程就已經結束了。可能看著有點復雜,可以對照下面代碼來。
- //插入節點,輸入參數為
- //zsl:表頭
- //score:插入元素的分數score
- //ele:插入元素的具體數據ele
- zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
- //使用update數組記錄每層待插入元素的前一個元素
- zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
- //記錄前置節點與第一個節點之間的跨度,即元素在列表中的排名-1
- unsigned int rank[ZSKIPLIST_MAXLEVEL];
- int i, level;
- serverAssert(!isnan(score));
- x = zsl->header;
- //從最大的level開始遍歷,從頂到底,找到每一層待插入的位置
- for (i = zsl->level-1; i >= 0; i--) {
- /* store rank that is crossed to reach the insert position */
- rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
- //直接找到第一個分數比該元素大的位置
- //或者分數與該元素相同但是對象的ASSICC碼比該元素大的位置
- while (x->level[i].forward &&
- (x->level[i].forward->score < score ||
- (x->level[i].forward->score == score &&
- sdscmp(x->level[i].forward->ele,ele) < 0)))
- {
- //將已走過元素的跨越元素進行計數,得到元素在列表中排名,或者是已搜尋的路徑長度
- rank[i] += x->level[i].span;
- x = x->level[i].forward;
- }
- //記錄待插入位置
- update[i] = x;
- }
- //隨機產生一個層數,在1到32之間,層數越高,生成的概率越低
- level = zslRandomLevel();
- //如果產生的層數大于現有的最高層數,則超出層數都需要初始化
- if (level > zsl->level) {
- //開始循環
- for (i = zsl->level; i < level; i++) {
- rank[i] = 0;
- //該元素作為這些層的第一個節點,前節點就是header
- update[i] = zsl->header;
- //初始化后這些層每層有兩個元素,走一步就是跨越所有元素
- update[i]->level[i].span = zsl->length;
- }
- zsl->level = level;
- }
- //創建節點
- x = zslCreateNode(level,score,ele);
- for (i = 0; i < level; i++) {
- //將新節點插入到各層鏈表中
- x->level[i].forward = update[i]->level[i].forward;
- update[i]->level[i].forward = x;
- // rank[0]是第0層的前置節點P1(也就是底層插入節點前面那個節點)與第一個節點的跨度
- // rank[i]是第i層的前置節點P2(這一層里在插入節點前面那個節點)與第一個節點的跨度
- // 插入節點X與后置節點Y的跨度f(X,Y)可由以下公式計算
- // 關鍵在于f(P1,0)-f(P2,0)+1等于新節點與P2的跨度,這是因為跨度呈扇形形向下延伸到最底層
- // 記錄節點各層跨越元素情況span, 由層與層之間的跨越元素總和rank相減而得
- x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
- // 插入位置前一個節點的span在原基礎上加1即可(新節點在rank[0]的后一個位置)
- update[i]->level[i].span = (rank[0] - rank[i]) + 1;
- }
- /* increment span for untouched levels */
- for (i = level; i < zsl->level; i++) {
- update[i]->level[i].span++;
- }
- // 第0層是雙向鏈表, 便于redis常支持逆序類查找
- x->backward = (update[0] == zsl->header) ? NULL : update[0];
- if (x->level[0].forward)
- x->level[0].forward->backward = x;
- else
- zsl->tail = x;
- zsl->length++;
- return x;
- }
- int zslRandomLevel(void) {
- int level = 1;
- while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
- level += 1;
- return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
- }
獲取節點排名
擔心大家忘了這張圖,再粘貼一遍。如下圖,這部分邏輯比較簡單,就不寫了,具體參考代碼分析。
- //得到節點的排名
- //輸入參數為表頭結構zsl,分數score,真正的數據ele
- unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
- zskiplistNode *x;
- unsigned long rank = 0;
- int i;
- //先獲取表頭的頭指針,即找到管理所有節點的level數組
- x = zsl->header;
- //從表頭的level,即最大值開始循環遍歷
- for (i = zsl->level-1; i >= 0; i--) {
- //如果找到分數小于目標分數的,排名加上其跨度
- //或者分數相同,但是具體數據小于目標數據的,排名也加上跨度
- while (x->level[i].forward &&
- (x->level[i].forward->score < score ||
- (x->level[i].forward->score == score &&
- sdscmp(x->level[i].forward->ele,ele) <= 0))) {
- rank += x->level[i].span;
- x = x->level[i].forward;
- }
- //確保在第i層找到分值相同,且對象相同時才會返回排位值
- if (x->ele && sdscmp(x->ele,ele) == 0) {
- return rank;
- }
- }
- return 0;
- }
結語
該篇主要講了Redis的ZSET數據類型的底層實現跳躍表,先從跳躍表是什么,引出跳躍表的概念和數據結構,剖析了其主要組成部分,進而通過多幅過程圖解釋了Redis是如何設計跳躍表的,最后結合源碼對跳躍表進行描述,如創建過程,添加節點過程,獲取某個節點排名過程,中間穿插例子和過程圖。
如果覺得寫得還行,麻煩給個贊👍,您的認可才是我寫作的動力!
如果覺得有說的不對的地方,歡迎評論指出。
好了,拜拜咯。
原文鏈接:https://mp.weixin.qq.com/s/EDGrGabrdorgKUdaw6OK5A