SVM原理詳細圖文教程!一行代碼自動選擇核函數,還有實用工具
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
SVM?老分類算法了,輕松拿下。
然而,每一次老板讓你講解SVM,或每一次面試被問到SVM,卻總是結結巴巴漏洞百出。
「這些人怎么總能精準發現我的盲點?」
簡直讓人懷疑自己掌握的是假SVM。
如果你有這樣的問題,那這篇SVM數學原理對你會有很大幫助,一起來看看吧。
SVM 由線性分類開始
理解SVM,咱們必須先弄清楚一個概念:線性分類器。
給定一些數據點,它們分別屬于兩個不同的類,現在要找到一個線性分類器把這些數據分成兩類。
如果用x表示數據點,用y表示類別(y可以取1或者-1,分別代表兩個不同的類),一個線性分類器的目標是要在n維的數據空間中找到一個超平面(hyper plane),將x的數據點分成兩類,且超平面距離兩邊的數據的間隔最大。
這個超平面的方程可以表示為( wT中的T代表轉置):
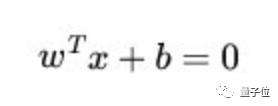
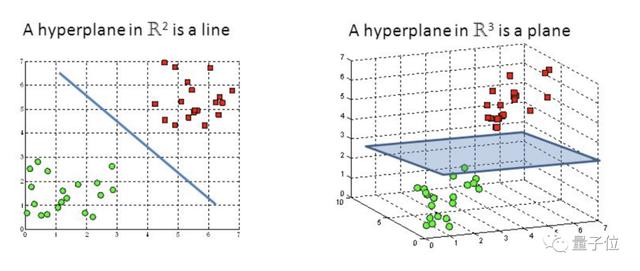
△2維坐標系中,超平面是一條直線
當f(x)等于0的時候,x便是位于超平面上的點,而f(x)大于0的點對應 y=1 的數據點,f(x)小于0的點對應y=-1的點。
SVM 想要的就是找到各類樣本點到超平面的距離最遠,也就是找到最大間隔超平面。任意超平面可以用下面這個線性方程來描述:
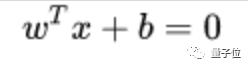
二維空間點(x,y)到直線Ax+By+C=0的距離公式是:
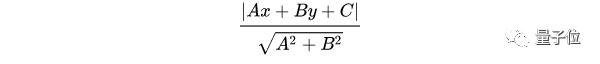
擴展到n維空間后,點x=(x1,x2……xn)到直線wTx+b=0的距離為:
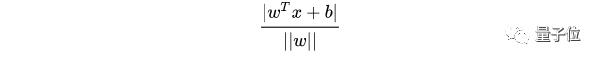
其中 :
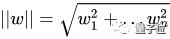
根據支持向量的定義,支持向量到超平面的距離為d,其他點到超平面的距離大于d。
于是有:
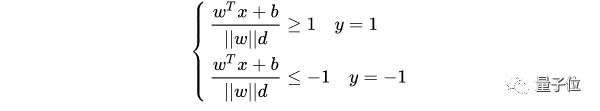
||w||d是正數,令它為 1(之所以令它等于 1,是為了方便推導和優化,且這樣做對目標函數的優化沒有影響),于是:
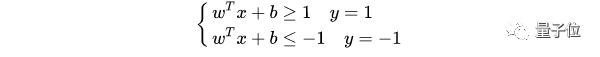
將兩個方程合并,有:
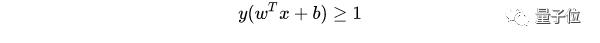
至此,就得到了最大間隔超平面的上下兩個超平面。
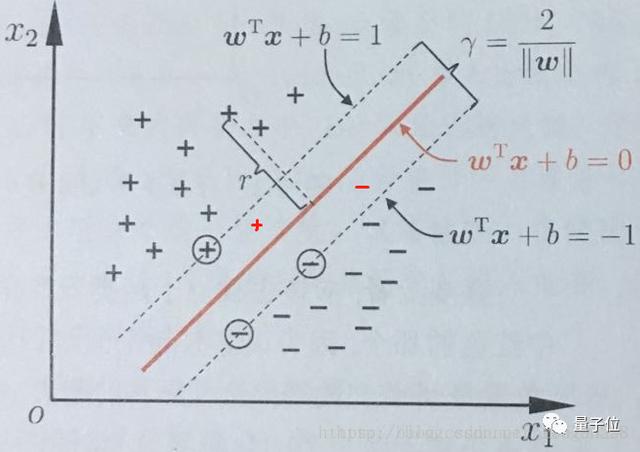
每個支持向量到超平面的距離可以寫為:
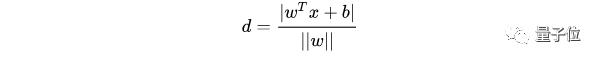
由 y(wTx+b)>1>0 可以得到 y(wTx+b)=|wTx+b|,所以可以將支持向量到超平面距離改寫為:
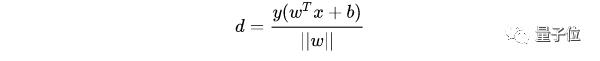
最大化這個距離:
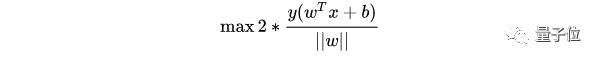
這里乘上 2 倍是為了后面推導方便,對目標函數沒有影響。
帶入一個支持向量,可以得到:
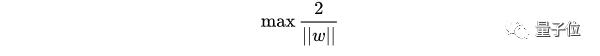
所以得到的最優化問題是:
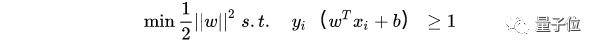
處理異常值
有時,對于某些點(x(i),y(i)),分類器可能會做出錯誤操作。
盡管在開發實際使用的SVM模型時,會設計冗余,避免過擬合,但仍然需要想辦法將誤差控制在一個較小的范圍。
可以通過在模型中增加懲罰機制(用c表示)解決這個問題。
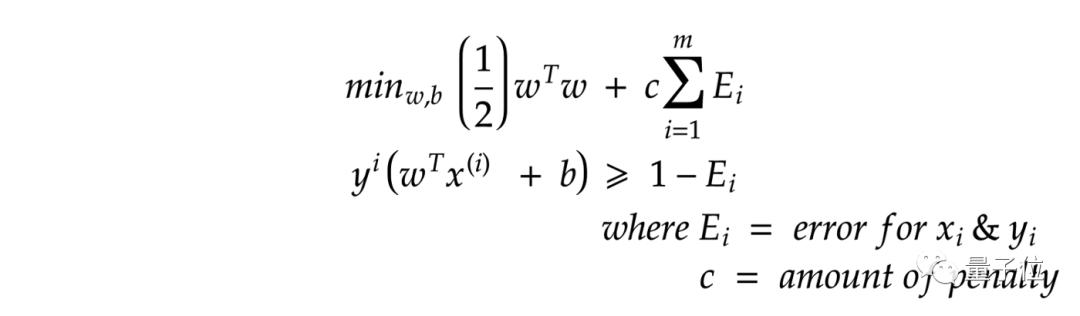
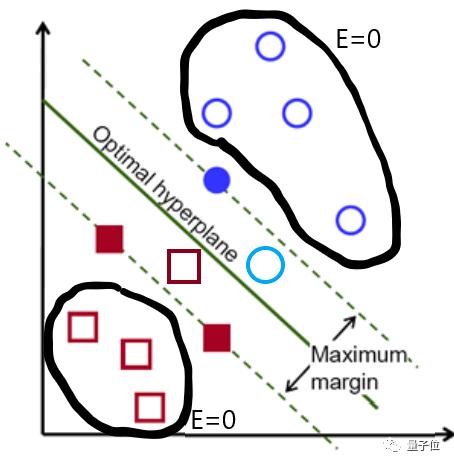
設SVM輸出結果為E,則上圖中出現的E=0則沒有懲罰。
若果c非常大,則模型分類更加精準,但支持向量到超平面距離小,容易出現過擬合。
若c=1,則支持向量到超平面距離最大化,盡管會出現一些分類誤差,但這是一種較好的方案。
約束凸優化問題
為了克服約束凸優化問題,采用PEGASOS算法。
重新構造一個約束獨立性方程:
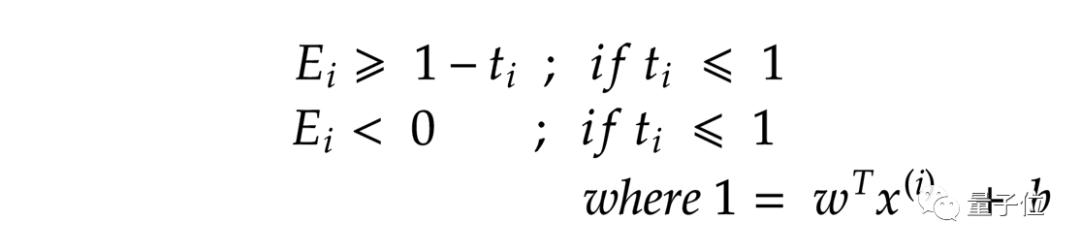
上式表示,如果點遠離直線,則誤差將為零,否則誤差將為(1-t(i))。
我們需要最小化的是:
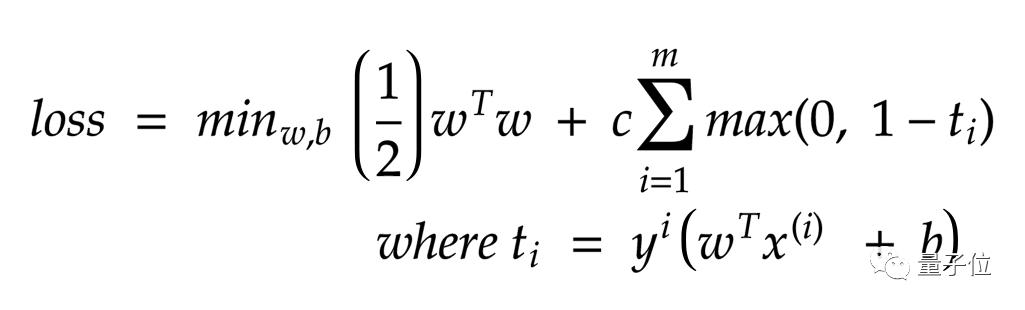
由于消除了約束,因此可以采用梯度下降來最大程度地減少損失。
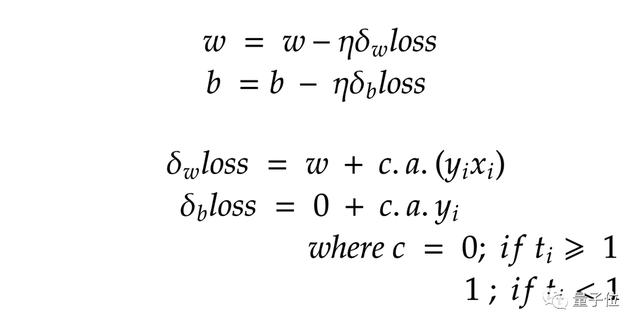
梯度下降算法計算損失:

在SVM上應用梯度下降:

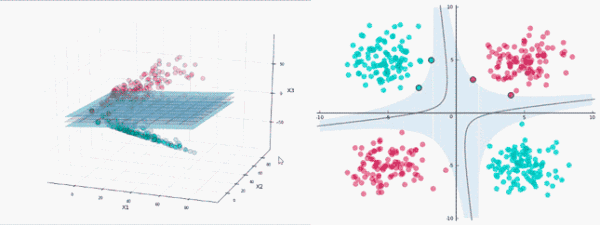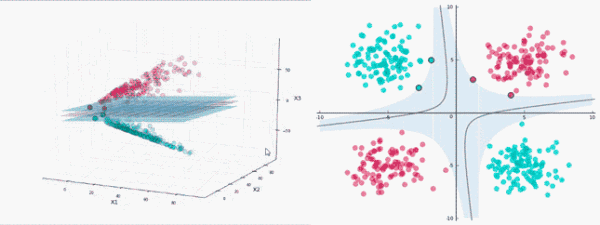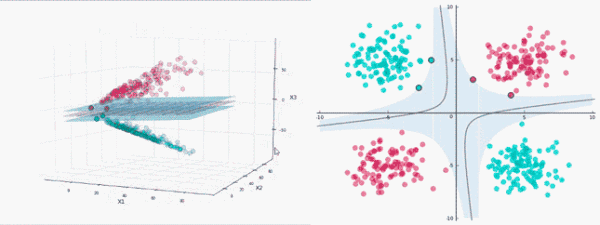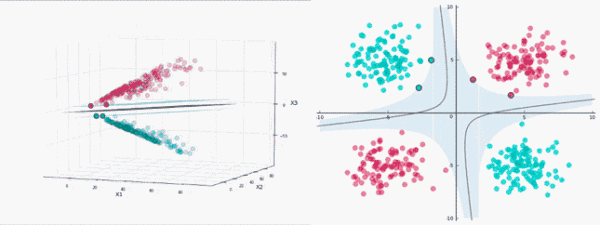
非線性分類
使用SVM對非線性數據進行分類,需要將數據投影到更高的維度,即通過增加低維數據的特征向量將其轉換為高維數據。
增加數據特征向量需要消耗巨大的計算資源,這里采用核函數。
而這種思路最難的點,是為你自己的模型選擇一個合適的核函數。
這里推薦一種自動調參方法GridSearch。
將多種核函數(線性、RBF、多項式、sigmoid等)等標號,依次調用,找到一個最合適自己模型的。
定義一個變量params:
- params = [{‘kernel’:[‘linear’, ‘rbf’, ‘poly’, ‘sigmoid’], ‘c’:[0.1, 0.2, 0.5, 1.0, 2.0, 5.0]}
調用:

以上詳細介紹了SVM背后的數學原理,并提供了一些使用SVM模型時的問題解決辦法。
其中,使用代碼自動選擇核函數的方法來自外國博主Daksh Trehan。
如果你對SVM的原理有更深刻的理解,或有其他實用的技巧,請留言分享給大家吧。