Kubernetes容器網絡模型
1.背景
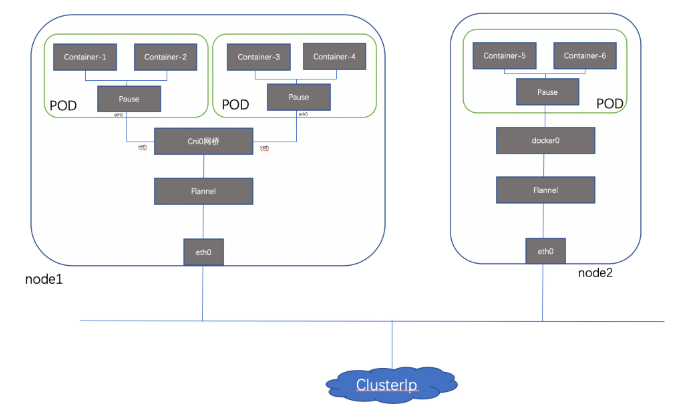
計算、存儲和網絡是云時代的三大基礎服務,作為新一代基礎架構的 Kubernetes 也不例外。而這三者之中,網絡又是一個最難掌握和最容易出問題的服務;本文通過對Kubernetes網絡流量模型進行簡單梳理,希望對初學者能夠提供一定思路。先看一下kubernetes 總體模型:
容器網絡中涉及的幾個地址:
Node Ip:物理機地址。
POD Ip:Kubernetes的最小部署單元是Pod,一個pod 可能包含一個或多個容器,簡單來講容器沒有自己單獨的地址,他們共享POD 的地址和端口區間。
ClusterIp:Service的Ip地址,外部網絡無法ping通改地址,因為它是虛擬IP地址,沒有網絡設備為這個地址負責,內部實現是使用Iptables規則重新定向到其本地端口,再均衡到后端Pod;只有Kubernetes集群內部訪問使用。
Public Ip :Service對象在Cluster IP range池中分配到的IP只能在內部訪問,適合作為一個應用程序內部的層次。如果這個Service作為前端服務,準備為集群外的客戶提供業務,我們就需要給這個服務提供公共IP。
2.容器網絡流量模型
容器網絡至少需要解決如下幾種場景的通信:①POD內容器間通信
②同主機POD間 通信
③跨主機POD間 通信
④集群內Service Cluster Ip和外部訪問下面具體介紹實現方式
2.1 POD內容器間通信
Pod中的容器可以通過“localhost”來互相通信,他們使用同一個網絡命名空間,對容器來說,hostname就是Pod的名稱。Pod中的所有容器共享同一個IP地址和端口空間,你需要為每個需要接收連接的容器分配不同的端口。也就是說,Pod中的應用需要自己協調端口的使用。實驗如下:首先我們創建一個Pod ,包含兩個容器,容器參數如下:
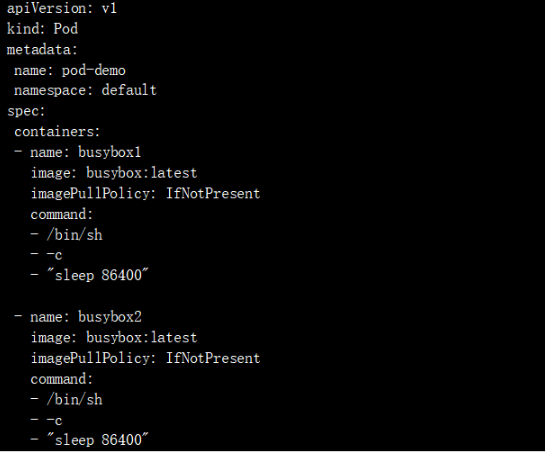
查看:

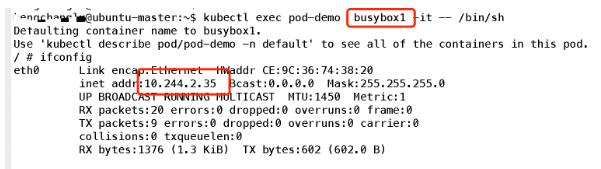
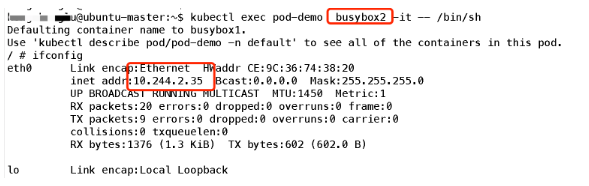
可以看到容器共享Pod 的地址,那么他們是否使用同一端口資源呢,我們可以簡單實驗一下:首先在容器1監聽一個端口:

然后在容器2查看該端口是否被占用:

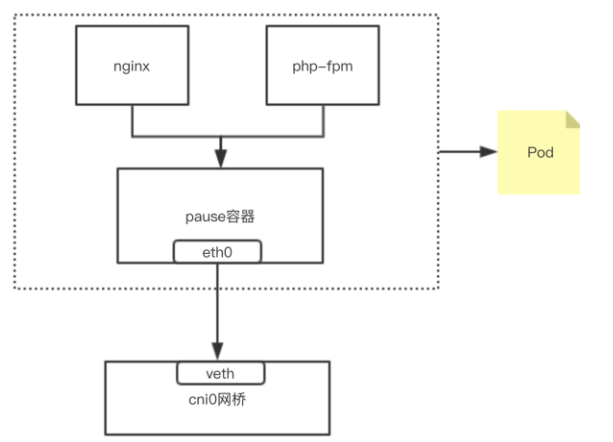
可見端口也是共享的;所以簡單理解,可以把Pod看做一個小系統,容器當做系統中的不同進程;內部實現:同POD 內的容器實際共享同一個Namespace,因此使用相同的Ip和Port空間,該Namespace 是由一個叫Pause的小容器來實現,每當一個Pod被創建,那么首先創建一個pause容器, 之后這個pod里面的其他容器通過共享這個pause容器的網絡棧,實現外部pod進行通信,因此對于同Pod里面的所有容器來說,他們看到的網絡視圖是一樣的,我們在容器中看的地址,也就是Pod地址實際是Pause容器的IP地址。總體模型如下:
我們在node 節點查看之前創建的POD,可以看到該pause容器 :
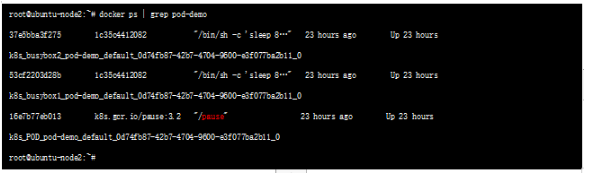
這種新創建的容器和已經存在的一個容器(pause)共享一個 Network Namespace(而不是和宿主機共享) 就是我們常說的container 模式。
2.2 同主機POD間通信
每個節點上的每個Pod都有自己的namespace,同主機上的POD之間怎么通信呢?我們可以在兩個POD之間建立Vet Pair進行通信,但如果有多個容器,兩兩建立Veth 就會非常麻煩,假如有N 個POD ,那么我們需要創建n(n-1)/2個Veth Pair,擴展性非常差,如果我們可以將這些Veth Pair 連接到一個集中的轉發點,由它來統一轉發就就會非常便捷,這個集中轉發點就是我們常說的bridge;如下所示(簡單起見,這里把pause忽略):
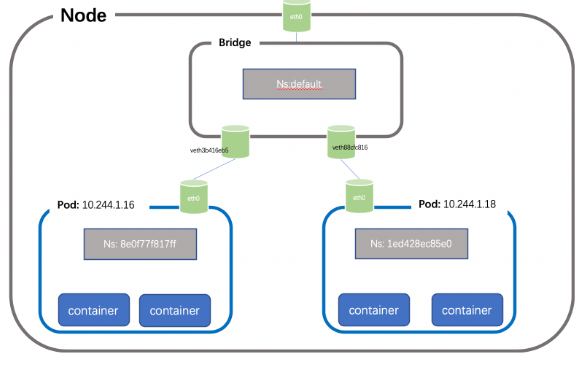
仍然以我們的測試環境為例,創建pod1 和pod2地址分別為:10.244.1.16、10.244.1.18,位于node1 節點
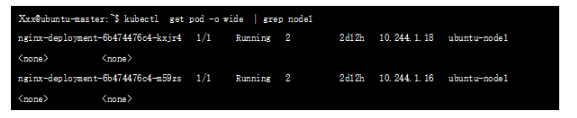
查看節點下的namespace:
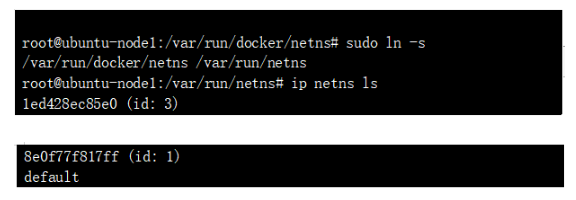
這兩個NS就是上述兩個POD 對應的namespace,查詢對應namespace 下的接口:
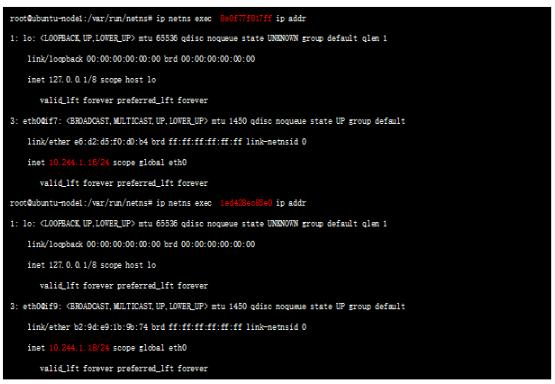
可以看到標紅處的地址,實際就是POD 的ip地址;NS 和對應的POD 地址都找到了,那么如何確認這兩個ns 下的虛接口的另一端呢? 比較直觀的確認方式為:上述接口如 3: eth0@if7,表示本端接口id 為3 ,對端接口id是7,我們看下default namespace(我們平時看的默認都在default下) 的veth口:
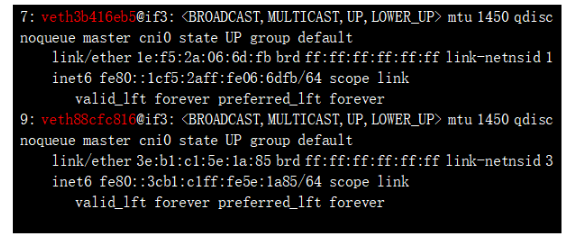
7: veth3b416eb5@if3 ,該接口的id 正是我們要找的id 為7的接口 ,是veth pair的另一端;
2.3 跨主機POD 間通信
簡單來看,對于網絡上兩個端點之間的互通無非兩種方案,一種是underlay 直接互通,那么就需要雙方有彼此的路由信息并且該路由信息在underlay的路徑上存在,一種是overlay 方案,通過隧道實現互通,underlay 層面保證主機可達即可,前者代表方案有 Calico(direct模式)和Macvlan,后者有Overlay,OVS,Flannel和Weave。我們取代表性的Flannel 和calico 插件進行介紹;
2.3.1 Flannel
總體通信流程如下:
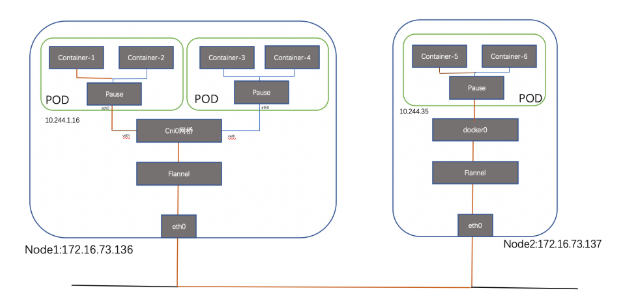
通信過程
2.3.1.1地址分配
flanneld第一次啟動時,從 etcd 獲取配置的 Pod 網段信息,為本節點分配一個未使用的地址段,然后創建 flannedl.1 網絡接口(也可能是其它名稱,如 flannel1 等),flannel 將分配給自己的 Pod 網段信息寫入 /run/flannel/docker 文件(不同k8s版本文件名存在差異),docker 后續使用這個文件中的環境變量設置 docker0 網橋,從而使這個地址段為本節點的所有;
查看flannel 為docker 分配的地址段:

表示該節點創建的POD 地址都從10.244.1.1/24中分配,比如node1 節點的如下2個pod。

2.3.1.2路由下發
每臺主機上,flannel 運行一個daemon 進程叫flanneld,它可以在內核中創建路由表,查看node1節點的路由表如下:
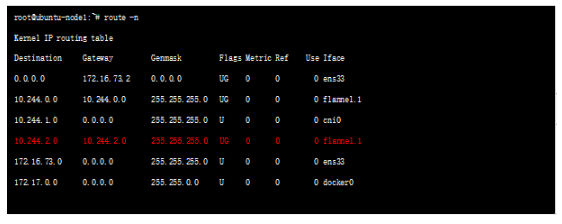
可以看到node2 節點的路由match 10.244.2.0 一行規則,出接口為flannel.1 口(接口名flannel后數字可能不一樣) flannel.1 是flanneld程序創建的一個隧道口;這里有一個問題,就是如何判斷隧道打到那里呢,很顯然,flannld存儲了類似容器-物理節點之間的映射關系,這種信息存放在etcd里面,flannld進程通過讀取etcd中的映射關系信息,決定隧道外層封裝。
2.3.1.3數據面封裝
Flannel 知道外層封裝地址后,對報文進行封裝,源采用自己的物理ip 地址,目的采用對端的,vxlan 外層的udp port 8472(如果是UDP封裝使用8285作為默認目的端口,下文會提到),對端只需監控port 即可,當改端口收到報文后將報文送到flannedld 進程,進程將報文送到flanned 接口接封裝,然后查詢本地路由表:
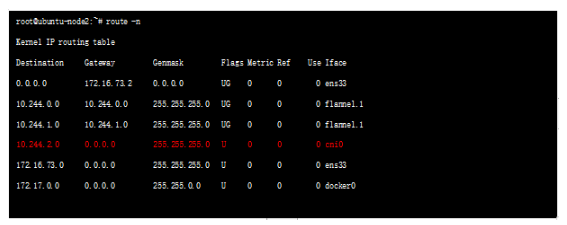
可以看到目的地址為cni0 ;Flannel功能內部支持三種不同后端實現,分別是:
Host-gw:需要兩臺host 在同一網段,不支持跨網,因此不適合大規模部署
UDP:不建議使用,除非內核不支持vxlan 或者debugg時候使用,當前也已經廢棄;
Vxlan : vxlan 封裝,flannel 使用 vxlan 技術為各節點創建一個可以互通的 Pod 網絡,使用的端口為 UDP 8472(需要開放該端口,如公有云 AWS 等)。
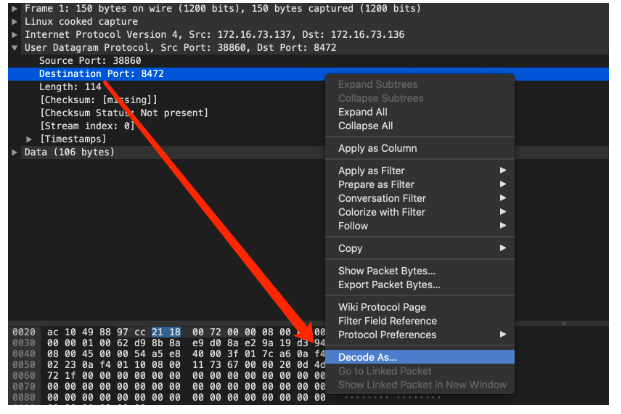
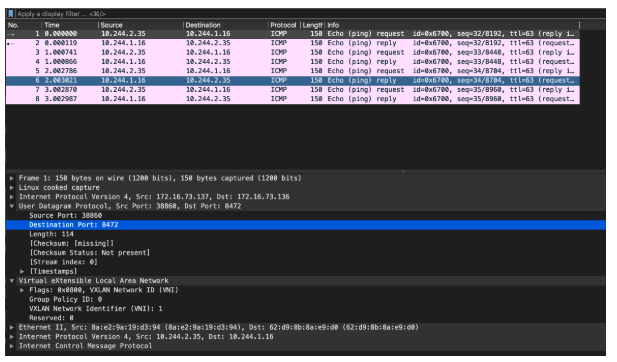
我們在node 節點進行抓包驗證一下:
(注:因為在linux 環境中,Flannel的vxlan 封裝中UDP 目的port 是 8472 ,標準Vxlan 報文的識別依據是目的端口4789,因此需要手動指定按照vxlan 來解析,否則無法識別內層信息)

2.3.2 CalicoCalico支持3種路由模式:
Direct: 路由轉發,報文不做封裝;
Ip-In-Ip:Calico 默認的路由模式,數據面采用ipip封裝;
Vxlan:vxlan 封裝;
這里主要介紹Direct模式,采用軟路由建立BGP 宣告容器網段,使得全網所有的Node和網絡設備都有到彼此的路由的信息,然后直接通過underlay 轉發。Calico實現的總體結構如下:
組件包含:
Felix:Calico agent:運行在每臺node上,為容器設置網絡信息:IP,路由規則,iptable規則等BIRD:
BGP Client:監聽 Host上由 Felix 注入的路由信息,然后通過 BGP 協議廣播告訴其他Host節點,從而實現網絡互通
BGP Route Reflector: BGP peer建立方式多樣,可以在node 之間兩兩建立bgp peer(默認模式),和傳統ibgp peer問題類似,這會帶來n*(n-1)/2 的鄰居量,因此也可以自建RR 反射器(上圖中結構),node 節點和RR 建立peer,當然node也可以和Tor 建peer,詳細的組網討論可以參考官網:
https://docs.projectcalico.org/reference/architecture/design/l3-interconnect-fabric
Calicoctl: calico命令行管理工具。
具體選擇哪種peer方式沒有固定標準,要適配總體網絡規劃,只要最終保證容器網絡可正確發布到物理網絡即可;
數據通信的流程為:數據包先從veth設備對另一口發出,到達宿主機上的Cali開頭的虛擬網卡上,到達這一頭也就到達了宿主機上的網絡協議棧,然后查詢路由表轉發;因為本機通過bird 和RR 建立bgp 鄰居關系,會將本地的容器地址發送到RR 從而反射到網絡其它節點,同樣,其它節點的網絡地址也會傳送到本地,然后由Felix 進程進行管理并下發到路由表中,報文匹配路由規則后正常進行轉發即可(實際還有復雜的iptables 規則,這里不做展開)
下面通過簡單實驗學習下:
具體安裝過程不再討論,可參考官網:https://www.projectcalico.org/進行安裝部署;
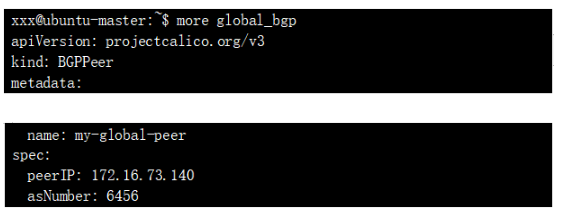
Node節點bgp配置如下:
為了簡化實驗,我們再啟用一臺機器運行FRR 來充當RR(關于Frr參考官網https://frrouting.org/) ,RR配置如下:
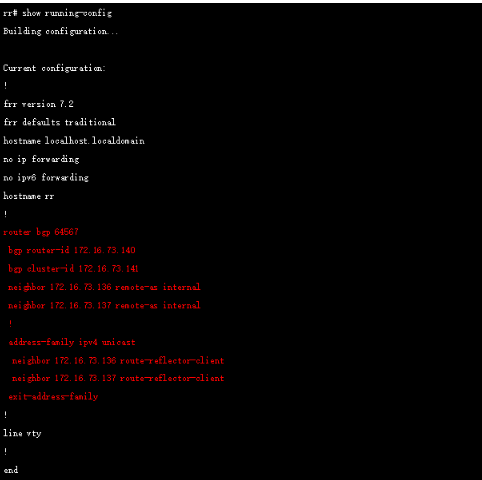
這樣所有節點都和RR 建立了bgp 鄰居,通過如下方式檢查鄰居狀態:
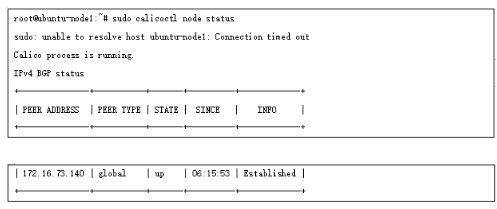
我們新建兩個pod ,分別位于兩個node節點:

默認情況下,當網絡中出現第一個容器,calico會為容器分配一段子網(子網掩碼/26),后續出現該節點上的pod都從這個子網中分配ip地址,這樣做的好處是能夠縮減節點上的路由表的規模.進入容器查看路由我們發現網關地址為169.254.1.1
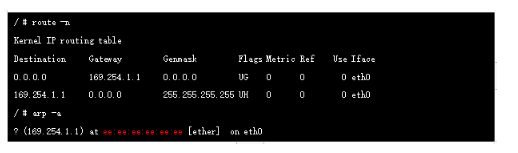
實際上在calico 網絡中,容器網關始終是169.254.1.1,該地址在實際網絡中不存在的,是直接進行的ARP 代理(ee:ee:ee:ee:ee:ee),我們在創建Pod的時候系統會在對應的node 上新增一個cali開頭的虛擬網卡,它就是veth Pair的另一端(本端是容器本地eth0口),它的mac 就是上面的169.254.1.1 對應的mac地址
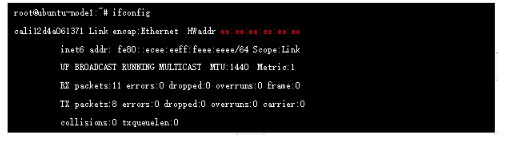
此時的報文已經進入default namespace ,這里開始查看路由表:
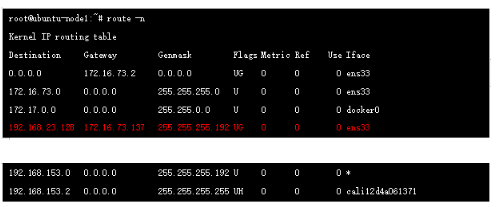
其中192.168.23.128/26 是node2上的地址空間,該路由由node2 節點bird發送到RR,RR 反射到node1節點的bird ,然后由felix來進行管理和下發到路由表中,我們可以在node1節點抓包進一步確認:
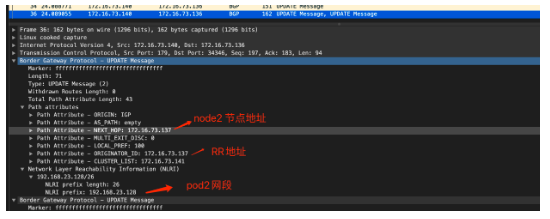
同時因為calico 的代理方式,使得同node的不同POD通信也比較特殊,它也是通過三層轉發來實現,比如node2 節點的2個地址,在路由表中都是/32位存在,下一跳接口為veth-pair的一端,另一端就是對應的pod內接口;
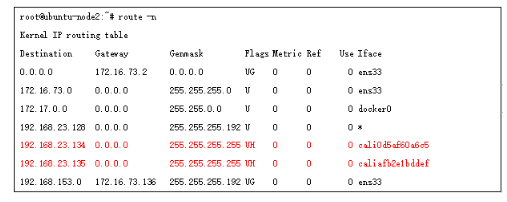
這和flannel 經過bridge 方式實現是不一樣的;
2.3.3 總結
這里我們從網絡角度對flannel 和calico 進行簡單對比:
總體來看,對性能敏感、策略需求較高時偏向于Calio方案,否則的話,采用Flannel會是更好的選擇;
2.4 Service 和外部通信
Serice 和外部通信場景實現涉及較多iptables 轉發原理,限于篇幅這里不再展開,簡單介紹如下:
Pod與service通信: Pod間可以直接通過IP地址通信,但前提是Pod知道對方的IP。在 Kubernetes集群中,Pod可能會頻繁地銷毀和創建,也就是說Pod的IP 不是固定的。為了解決這個問題,Service提供了訪問Pod的抽象層。 無論后端的Pod如何變化,Service都作為穩定的前端對外提供服務。 同時,Service還提供了高可用和負載均衡功能,Service負責將請求轉 給正確的Pod;
外部通信:無論是Pod的IP還是Service的Cluster IP,它們只能在Kubernetes集群中可見,對集群之外的世界,這些IP都是私有的Kubernetes提供了兩種方式讓外界能夠與Pod通信:
NodePort:Service通過Cluster節點的靜態端口對外提供服務, 外部可以通過:訪問Service。
LoadBalancer:Service利用cloud provider提供的load balancer對外提供服務,cloud provider負責將load balancer 的流量導向Service。目前支持的cloud provider有GCP、AWS、 Azur等。
3.結語
容器網絡場景復雜,涉及面廣,希望一些心得體會可以給大家帶來參考,錯誤之處還望指正。