寶德深度學(xué)習(xí)產(chǎn)品助華人運(yùn)通自動駕駛
華人運(yùn)通技術(shù)有限公司是一家從事新能源汽車、智能網(wǎng)聯(lián)及共享交通系統(tǒng)技術(shù)研發(fā)及生產(chǎn)的高科技創(chuàng)新公司,擁有汽車全產(chǎn)業(yè)鏈包括新能源、自動駕駛和車聯(lián)網(wǎng)等前沿領(lǐng)域多年深厚經(jīng)驗(yàn),致力于創(chuàng)領(lǐng)新能源汽車及智能交通領(lǐng)域核心部件和關(guān)鍵系統(tǒng)的技術(shù)突破,推動人類未來智能交通出行方式的變革。隨著該公司在自動駕駛業(yè)務(wù)的布局,深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)顯得尤為重要,需要超強(qiáng)的數(shù)據(jù)處理能力才能完成自動駕駛深度學(xué)習(xí)訓(xùn)練。
寶德作為國內(nèi)優(yōu)秀服務(wù)器廠商之一,憑借多年來積累的行業(yè)經(jīng)驗(yàn)與資源,與Intel、NVIDIA等國際大廠深度合作,并成為國內(nèi)為數(shù)不多的代理商之一。此次針對該公司的特殊要求,寶德工程師為其推薦了NVIDIA DGX系列產(chǎn)品,包括一臺DGX-1、兩臺DGX-Station。因?yàn)樯疃葘W(xué)習(xí)神經(jīng)網(wǎng)絡(luò)尤其是幾百上千層的神經(jīng)網(wǎng)絡(luò)需對計(jì)算和吞吐能力的需求非常高,GPU對處理復(fù)雜運(yùn)算擁有天然的優(yōu)勢,出色的浮點(diǎn)計(jì)算性能,可以同時(shí)保證分類和卷積的性能以及精準(zhǔn)度,所以搭載GPU的超級計(jì)算機(jī)是訓(xùn)練各種深度神經(jīng)網(wǎng)絡(luò)的不二選擇。
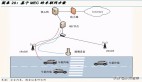
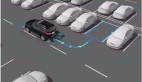
自動駕駛所需要的運(yùn)算能力體現(xiàn)在云端和終端兩個(gè)方面:終端運(yùn)算平臺主要負(fù)責(zé)通過傳感器數(shù)據(jù)感知周圍的環(huán)境,用高精度地圖實(shí)時(shí)定位,并按照算法模型做出駕駛決策。而在云端,則需要數(shù)據(jù)處理能力超強(qiáng)的數(shù)據(jù)中心。所有與云端連接的車輛都會將自己的行駛數(shù)據(jù)上傳到這里。而云端的任務(wù)則是利用這些大量的數(shù)據(jù),通過深度學(xué)習(xí)或者增強(qiáng)學(xué)習(xí)的形式去訓(xùn)練決策和感知的算法模型。經(jīng)過訓(xùn)練優(yōu)化的算法模型在經(jīng)過穩(wěn)定性驗(yàn)證后將會被重新更新到各個(gè)車輛終端中,這就是未來自動駕駛所使用的自我優(yōu)化體系。
NVIDIA DGX-Station
在DGX系列產(chǎn)品中,DGX-1相當(dāng)于把250臺服務(wù)器裝在了一個(gè)盒子里,它配備了7TB固態(tài)硬盤,8塊Tesla P100顯卡和2塊英特爾Xeon處理器——如此的配置也給起帶來了超高的處理性能(170萬億次浮點(diǎn)運(yùn)算/秒),是上代機(jī)型的12倍。而DGX-STATION則擁有高達(dá)480 萬億次浮點(diǎn)運(yùn)算性能,是目前首款也是唯一一款基于4 個(gè)Tesla® V100-加速器構(gòu)建的工作站,同時(shí)采用了下一代NVLink™ 以及全新Tensor核心架構(gòu)等創(chuàng)新技術(shù)。相較現(xiàn)今最快的GPU工作站,深度學(xué)習(xí)訓(xùn)練性能提升了3倍;相較20節(jié)點(diǎn)Spark服務(wù)器集群,大數(shù)據(jù)集分析速度提高100倍;由于采用NVIDIA NVLink技術(shù),I/O 性能較之通過PCIe方式相連的GPU 提升5倍;在深度學(xué)習(xí)訓(xùn)練方面實(shí)現(xiàn)最大通用性,每秒可以推理30,000 張圖像。NVIDIA DGX系列超級計(jì)算機(jī)為該公司提供了海量數(shù)據(jù)和強(qiáng)大的計(jì)算能力,使其可以在深度神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上進(jìn)行快速的機(jī)器學(xué)習(xí)。