













Redis面試常見問答
1. 什么是緩存雪崩?怎么解決?
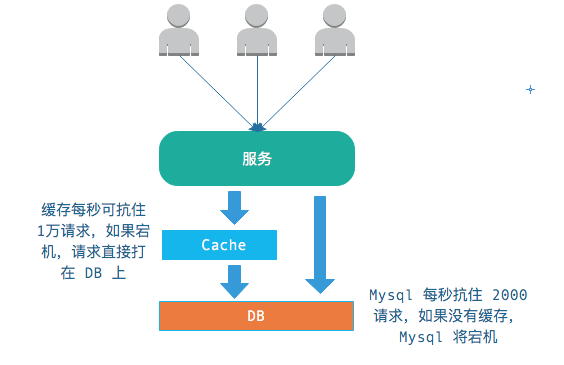
通常,我們會使用緩存用于緩沖對 DB 的沖擊,如果緩存宕機,所有請求將直接打在 DB,造成 DB 宕機——從而導致整個系統宕機。
如何解決呢?
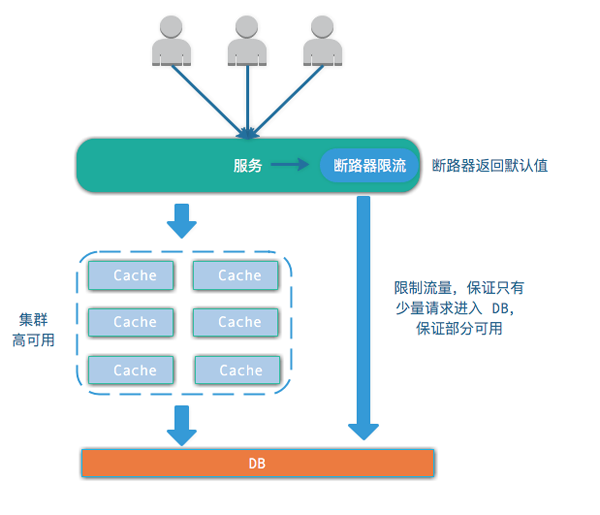
2 種策略(同時使用):
- 對緩存做高可用,防止緩存宕機
- 使用斷路器,如果緩存宕機,為了防止系統全部宕機,限制部分流量進入 DB,保證部分可用,其余的請求返回斷路器的默認值。
2. 什么是緩存穿透?怎么解決?
解釋 1:緩存查詢一個沒有的 key,同時數據庫也沒有,如果黑客大量的使用這種方式,那么就會導致 DB 宕機。
解決方案:我們可以使用一個默認值來防止,例如,當訪問一個不存在的 key,然后再去訪問數據庫,還是沒有,那么就在緩存里放一個占位符,下次來的時候,檢查這個占位符,如果發生時占位符,就不去數據庫查詢了,防止 DB 宕機。
解釋 2:大量請求查詢一個剛剛失效的 key,導致 DB 壓力倍增,可能導致宕機,但實際上,查詢的都是相同的數據。
解決方案:可以在這些請求代碼加上雙重檢查鎖。但是那個階段的請求會變慢。不過總比 DB 宕機好。
3. 什么是緩存并發競爭?怎么解決?
解釋:多個客戶端寫一個 key,如果順序錯了,數據就不對了。但是順序我們無法控制。
解決方案:使用分布式鎖,例如 zk,同時加入數據的時間戳。同一時刻,只有搶到鎖的客戶端才能寫入,同時,寫入時,比較當前數據的時間戳和緩存中數據的時間戳。
4.什么是緩存和數據庫雙寫不一致?怎么解決?
解釋:連續寫數據庫和緩存,但是操作期間,出現并發了,數據不一致了。
通常,更新緩存和數據庫有以下幾種順序:
- 先更新數據庫,再更新緩存。
- 先刪緩存,再更新數據庫。
- 先更新數據庫,再刪除緩存。
三種方式的優劣來看一下:
先更新數據庫,再更新緩存。
這么做的問題是:當有 2 個請求同時更新數據,那么如果不使用分布式鎖,將無法控制最后緩存的值到底是多少。也就是并發寫的時候有問題。
先刪緩存,再更新數據庫。
這么做的問題:如果在刪除緩存后,有客戶端讀數據,將可能讀到舊數據,并有可能設置到緩存中,導致緩存中的數據一直是老數據。
有 2 種解決方案:
- 使用“雙刪”,即刪更刪,最后一步的刪除作為異步操作,就是防止有客戶端讀取的時候設置了舊值。
- 使用隊列,當這個 key 不存在時,將其放入隊列,串行執行,必須等到更新數據庫完畢才能讀取數據。
總的來講,比較麻煩。
先更新數據庫,再刪除緩存
這個實際是常用的方案,但是有很多人不知道,這里介紹一下,這個叫 Cache Aside Pattern,老外發明的。如果先更新數據庫,再刪除緩存,那么就會出現更新數據庫之前有瞬間數據不是很及時。
同時,如果在更新之前,緩存剛好失效了,讀客戶端有可能讀到舊值,然后在寫客戶端刪除結束后再次設置了舊值,非常巧合的情況。
有 2 個前提條件:緩存在寫之前的時候失效,同時,在寫客戶度刪除操作結束后,放置舊數據 —— 也就是讀比寫慢。設置有的寫操作還會鎖表。
所以,這個很難出現,但是如果出現了怎么辦?使用雙刪!!!記錄更新期間有沒有客戶端讀數據庫,如果有,在更新完數據庫之后,執行延遲刪除。
還有一種可能,如果執行更新數據庫,準備執行刪除緩存時,服務掛了,執行刪除失敗怎么辦???
這就坑了!!!不過可以通過訂閱數據庫的 binlog 來刪除。
















