99.999%,提升ElasticSearch穩定性的秘密
作者:empeliu,騰訊 TEG 后臺開發工程師
ElasticSearch 是一個分布式的開源搜索和分析引擎,因其功能強大、簡單易用而被應用到很多業務場景。在生產環境使用 ES 時,如果未進行優化則服務的穩定性可能得不到保障,目前我們使用 ES 作為賬單平臺的基礎組件為微信支付提供服務時就遇到這種問題。本文即從當前的業務場景出發,分析 ES 穩定性未到達要求的原因并提供相應的解決思路。
一、背景
微信支付的賬單系統是方便用戶獲取交易記錄,針對不同的用戶群,賬單也分為三類:
- 個人賬單:針對普通用戶群,這類用戶特點是基數大,單個用戶數據量小,使用賬單系統主要是獲取列表以及基礎統計;
- 商戶賬單:針對商戶用戶群,這類用戶特點是基數小,單個用戶數據量非常大,使用賬單系統主要是獲取列表,并且在獲取列表時需要支持豐富查詢條件;
- 業務賬單:針對用戶群介于普通用戶和商戶之間,比如微商或面對面小商戶,使用賬單系統主要是獲取列表以及豐富統計功能;
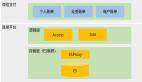
目前賬單平臺為微信支付的這三類賬單提供寫入、存儲和查詢服務,基本架構如下:
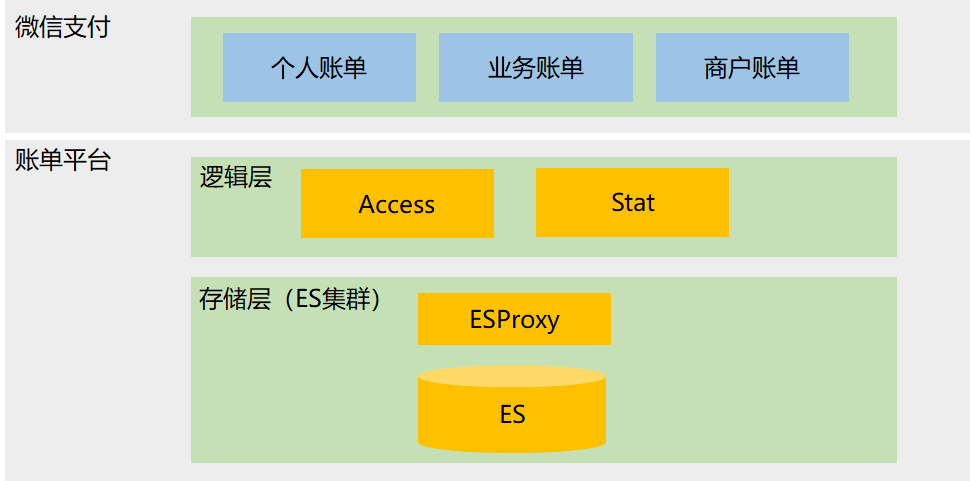
賬單平臺主要包括兩部分:
- 邏輯側:業務側直接對接模塊,主要是降低業務接入成本,提高接入效率;
- 存儲側:包含 ES 以及接入層 ESProxy,接入層對上屏蔽索引劃分機制,方便上層使用;
當前微信支付對整體質量要求非常高,體現在可用性方面是需要達到 99.99%,同樣賬單平臺也需要達到甚至超過該要求。但是在 ES 及系統環境未做優化的情況下,讀寫成功率是沒有達到要求,在個人賬單 ES 索引場景下,寫成功率為 99.85%,讀成功率為 99.95%,所以這里亟需優化。
二、內存回收慢優化
問題分析
針對讀寫成功率低問題,我們首先查看存儲側接入層 ESProxy 超時失敗的情況,對應如下圖:
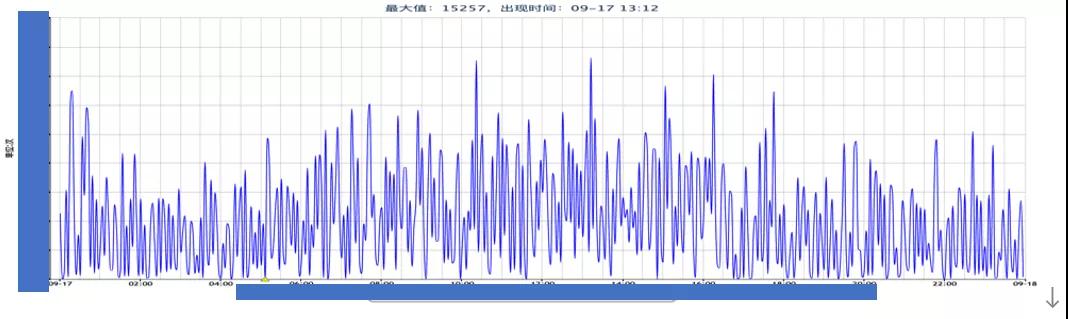
可以看出接入層訪問 ES 節點出現了大量超時,在排除接入層自身的問題后,基本上把問題源鎖定到 ES 節點。
通過進一步確認 ES 節點負載情況(如下圖),機器會出現 CPU 抖動,而抖動時上層會出現超時,這就表明讀寫成功率低是 CPU 抖動導致的,于是我們重心就是解決 CPU 抖動問題。
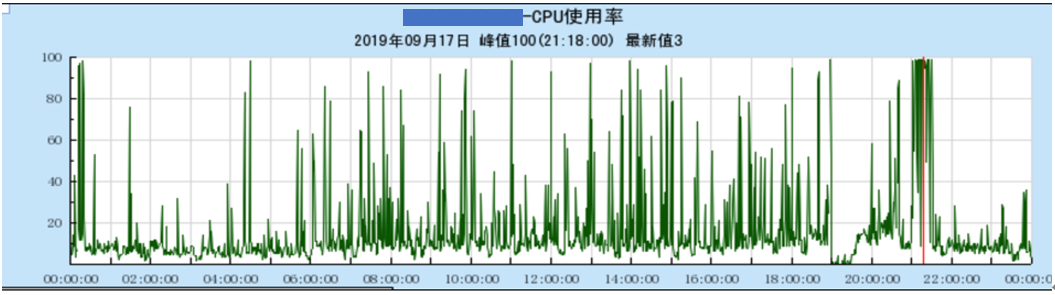
那么是什么原因導致 ES 節點的 CPU 抖動呢?首先我們先確定 CPU 抖動時系統具體在做什么,根據已有經驗,很有可能是 ES 熱點線程或 GC 導致的,但是在分析 CPU 抖動時 user 和 system 進程占比情況,其中 user 進程 CPU 占比基本沒有變化,而 system 進程 CPU 卻增長很多,由于 ES 熱點線程或 GC 是 user 進程,所以排除了這里的影響。通過系統相關統計以及 perf 得到下面現象:
- 抖動時系統在大量掃描可回收內存
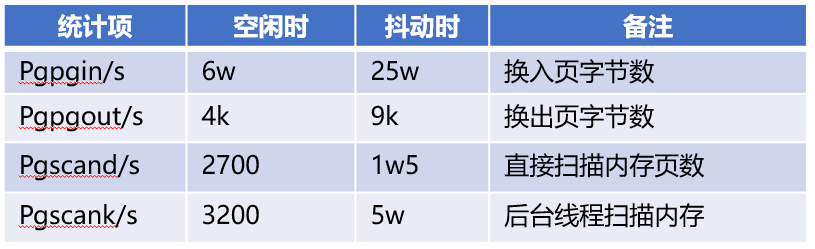
- 系統在不斷進行內存回收
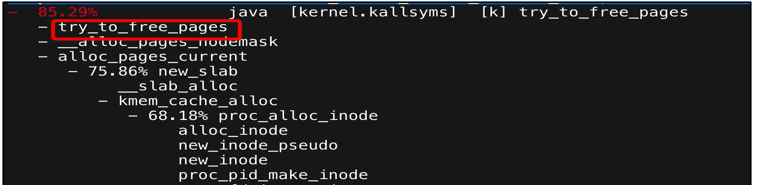
- 系統分配內存時出現了失敗
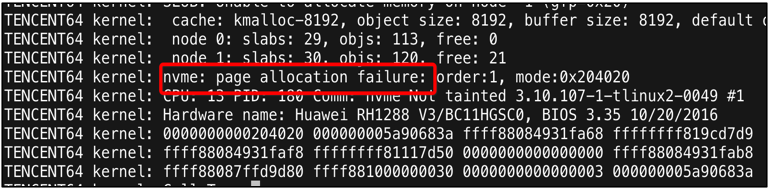
通過這三個現象,我們也得出了一個結論,CPU 抖動是因為內存不足導致。
優化方案
明確了抖動問題原因后,那么我們接下來的優化方向就是保證有足夠的空閑內存,避免內存不斷回收而出現 CPU 抖動。針對內存不足問題,我們首先確認系統當前的內存分布情況,具體數據如下:

進一步分析如下:
- ES 節點內存主要是被 JVM 以及 PageCache 內存占用
- Jvm 內存是被 java 獨占,該部分內存是不會被回收
- PageCache 內存由操作系統維護,該部分內存是可以被回收的
正常情況下,如果系統內存不足,則內核通過回收 PageCache 的內存即可提供足夠的空閑內存,即不會內存不足的情況;反過來說,當前出現內存不足,則說明 PageCache 未被正常回收,于是針對內存優化則聚焦到 PageCache 回收問題上。
針對 PageCache 回收問題,首先我們先明確什么因素導致 PageCache 不能及時回收,其中 MMap 就可能導致 PageCache 不能正常回收,原因是 MMap 后應用程序會引用到這部分內存,則內核在回收內存時會忽略這部分內存。而 ES 節點讀取文件的方式默認就是 MMap,整體的內存關聯關系如下圖:
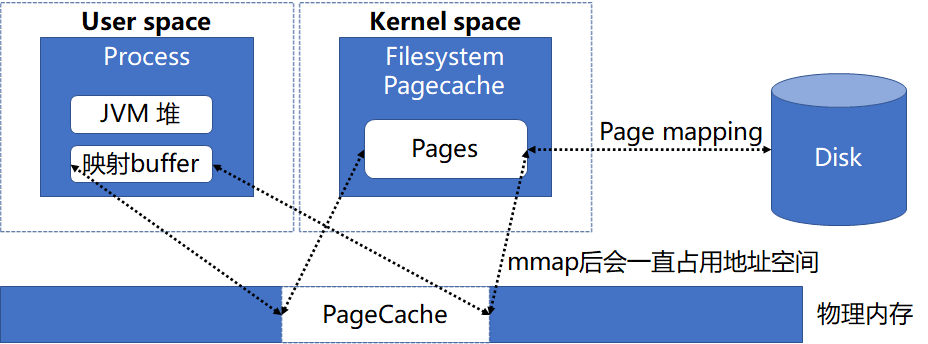
既然 MMap 方式會導致 PageCache 不能及時回收,那么自然考慮是采用其他方式替換 MMap 去訪問文件,在 Java 中即可采用 NIO 方式讀取文件,對應內存關聯關系如下:
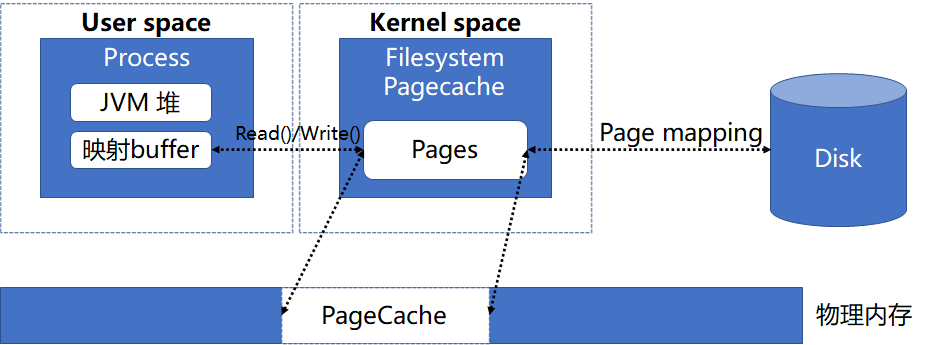
采用 NIO 方式訪問文件,PageCache 內存只被操作系統維護,則內核可以及時回收 PageCache 以保證足夠的內存使用,這樣就解決了內存不足問題,進而解決 CPU 抖動問題,從而提高讀寫成功率;
但是采用 NIO 訪問文件也存在問題,即數據會多一次內存復制,會導致延遲方面比 MMap 方式的高,經過測試發現延遲會高 30%左右,這樣的結果也不是我們想要的,于是我們考慮將兩者結合起來,目的是加快內存回收的同時降低延遲,采取的策略是根據訪問頻率來確定文件的讀寫方式(即高頻采用 MMap 方式,這樣可以保證延遲低,低頻采用 Nio 方式,這樣可以加快內核回收 PageCache),具體不同文件類型讀取方式如下表:

優化效果
采用 MMap+Nio 的方式后,通過測試驗證:
- 延遲方面和 MMap 基本一致
- 內存回收方面也比 MMap 好
采用 MMap+Nio 組合方式上線后,對應現網寫成功率由 99.85%提升到 99.99%。
三、高階內存優化
問題分析
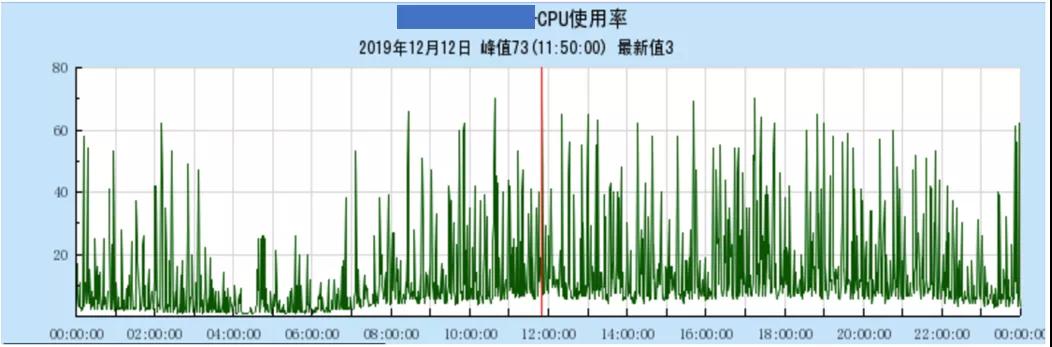
在系統運行一段時間后,現網的成功率逐漸降低,由 99.99%降低到 99.97%,對應接入層的超時失敗也相應增多,有了之前的經驗,我們相應查看了 ES 節點的負載情況,發現仍然有 CPU 抖動的現象(如下圖)。考慮到之前已經優化了內存回收慢的問題,此時應是新的問題導致的 CPU 抖動,于是接下來優化點依舊是解決抖動。
和之前分析 CPU 抖動問題一樣,我們先確認 CPU 抖動系統在做什么。通過 perf 分析,如下圖所示:
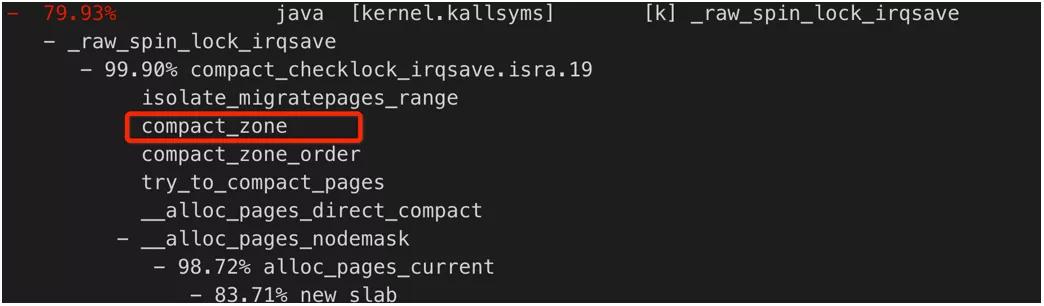
采樣的結果可以明確 CPU 抖動時,系統在進行內存碎片整合(即有 compact_zone()等函數調用),這就意味著此時系統高階內存是不足,為了進一步驗證當前的高階內存不足,通過 cat/proc/buddyinfo 查看當前系統空閑內存的分布情況,如下圖所示:

分析上面數據可以得出,當前空閑內存有 4G 左右,86%的內存是 0 階內存,大于等于 2 階的高階內存占比只有 4%左右,這里驗證當前空閑內存是基本都是碎片化的,碎片化內存示意圖如下所示:

優化方案
明確了當前的問題后,那么接下來重點就是考慮將碎片化的內存變成連續內存。前文我們明確了當前 ES 節點的內存主要有兩部分組成,分別是 JVM 內存和 PageCache 內存,并且在我們現網環境中,這兩部分內存基本上是獨立的(當前現網機器內存有兩個 NODE,每個 NODE 占了一半的物理內存,其中 JVM 和 PageCache 分布在不同的 NODE 上),這就意味著我們可以只優化 PageCache 間的內存碎片,這樣就可以滿足我們需求;對應優化流程如下:
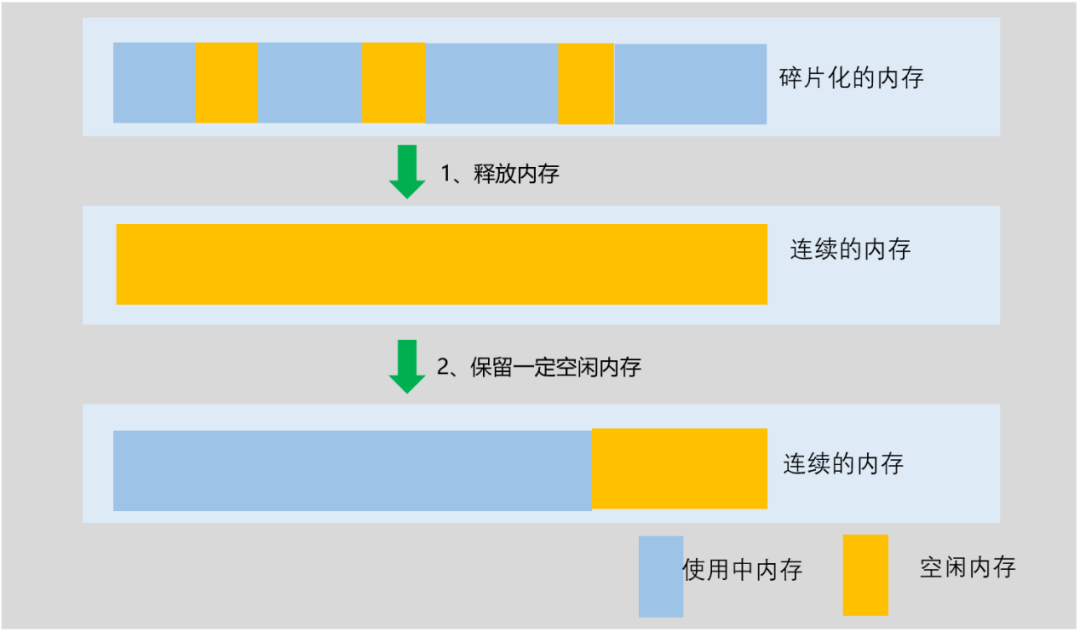
具體分為兩個步驟:
1、釋放內存:釋放 PageCache 內存,保證新的空閑內存盡可能連續,具體的處理措施是 echo1 > /proc/sys/vm/drop_cache
2、保留一定空閑內存:目的是避免內存的不斷申請和回收,導致內存碎片化再次變的嚴重,具體處理措施是限制 PageCache 的大小(這里依賴 tlinux 的實現),具體的命令是 echo36 > /proc/sys/vm/pagecache_limit_ratio
優化效果
經過上述的優化之后,系統的空閑內存分布如下:

此時的空閑也是在 4G 左右,但是大于等于 2 階的高階內存占比達到 95%左右,即高階內存當前是非常充足的,并且機器的 CPU 幾乎沒有抖動(如下圖所示)。
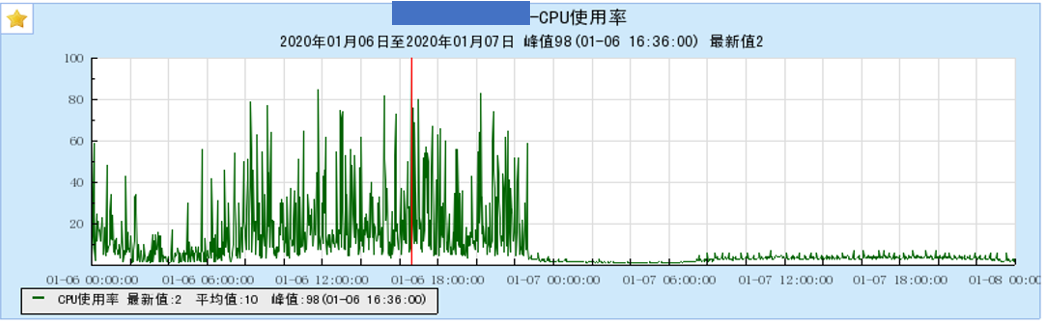
在現網進行相應調整之后,讀寫成功率提升效果如下:
寫成功率由 99.85%提升到 99.999%
讀成功率由 99.95%提升到 99.999%
四、結論
針對賬單平臺的 ES 系統的讀寫成功率未滿足要求,進行了如下優化措施:1、內存回收慢優化:優化 ES 文件讀取方式,加快內存回收,降低 CPU 在內存回收方面消耗;2、高階內存不足優化:整理碎片化內存,保證有充足高階內存,降低 CPU 在內存碎片整理消耗;
經過上述優化措施后,ES 系統的讀寫成功率達到 99.999%,超出當前的可用性要求,保障 ES 在生產環境穩定性。
參考:
1、Node Hot threadsAPI
2、Physical PageAllocation
3、Describing PhysicalMemory