













關于DevOps,數據科學家需要了解這些
【編者的話】本文是使用持續集成(通過GitHub Actions)構建自動模型訓練系統的哲學和實踐指南。
隨著機器學習(ML)在過去幾年的快速發展,開始ML實驗變得非常容易。多虧了像scikit-learn和Keras這樣的庫,用幾行代碼就可以創建模型。
但是,將數據科學項目轉化為有意義的應用程序比以往任何時候都更加困難,比如將模型轉化為團隊決策或成為產品的一部分。典型的ML項目涉及到許多不同的技能集,對于任何一個人來說,如果不是完全不可能的話,那也是一種挑戰——如此困難,少有的同時還能開發高質量軟件和游戲工程師的數據科學家被稱為獨角獸!
隨著這一領域的成熟,很多工作將需要軟件、工程和數學技能的結合,有些人說他們已經這么做了。
引用一位無與倫比的數據科學家/工程師/評論家Vicki Boykis在她的博客data science is different now里的話:
越來越清楚的是,在炒作周期的后期階段,數據科學正逐漸接近工程,數據科學家需要的技能不再是可視化和基于統計的,而是與傳統的計算機科學課程更加一致。
為什么數據科學家需要了解DevOps
那么,在眾多的工程和軟件技能中,數據科學家應該學習哪一種呢?我的錢花在DevOps上了。
DevOps是development和operations的合成詞,于2009年在比利時的一次會議上正式誕生。這次會議的召開是為了應對科技公司在歷史上經歷過深刻分歧的兩個方面之間的緊張關系。軟件開發人員需要快速行動并經常進行試驗,而運維團隊則優先考慮服務的穩定性和可用性(這些人讓服務器每天都在運行)。他們的目標不僅是對立,而且是競爭。
這聽起來很像今天的數據科學。數據科學家通過實驗創造價值:數據建模、組合和轉換的新方法。與此同時,雇傭數據科學家的組織受到穩定的激勵。
這種劃分的后果是深遠的:在最新的Anaconda數據科學狀態”報告中,“不到一半(48%)的受訪者認為他們可以證明數據科學對他們的組織的影響”。據估計,絕大多數由數據科學家創建的模型最終都被束之高閣。我們還沒有強大的實踐來在創建模型的團隊和部署模型的團隊之間傳遞模型。數據科學家和實現他們工作的開發人員和工程師擁有完全不同的工具、約束條件和技能集。
DevOps的出現就是為了解決軟件中的這種僵局,就像開發人員vs運維一樣。它取得了巨大的成功:許多團隊已經從每幾個月部署一次新代碼發展到一天部署幾次。既然我們已經有了機器學習和操作,那么現在就該考慮MLOps了——來自DevOps的用于數據科學的原則。
引入持續集成
DevOps既是一種哲學,也是一套實踐,包括:
- 自動化你所能做到的一切
- 快速獲得對新想法的反饋
- 減少工作流程中的手工交接
在一個典型的數據科學項目中,我們可以看到一些應用:
- 自動化你所能做到的一切。自動化部分重復和可預測的數據處理、模型訓練和模型測試。
- 快速獲得對新想法的反饋。當你的數據、代碼或軟件環境發生變化時,立即在類似生產的環境(即具有預期在生產中具有的依賴關系和約束的機器)中進行測試。
- 減少工作流程中的手工交接。為數據科學家尋找機會,盡可能多地測試他們自己的模型。不要等到有開發人員時才查看模型在類似生產環境中的行為。
實現這些目標的標準DevOps方法是一種稱為持續集成(CI)的方法。
要點是,當你更改項目的源代碼時(通常通過Git提交注冊更改),你的軟件將被自動構建和測試。每個動作都會引發反饋。CI通常與Git-flow一起使用,Git-flow是一種開發架構,其中的新特性構建在Git分支上。當一個特性分支通過自動化測試時,它就成為了一個候選分支,可以合并到主分支中。
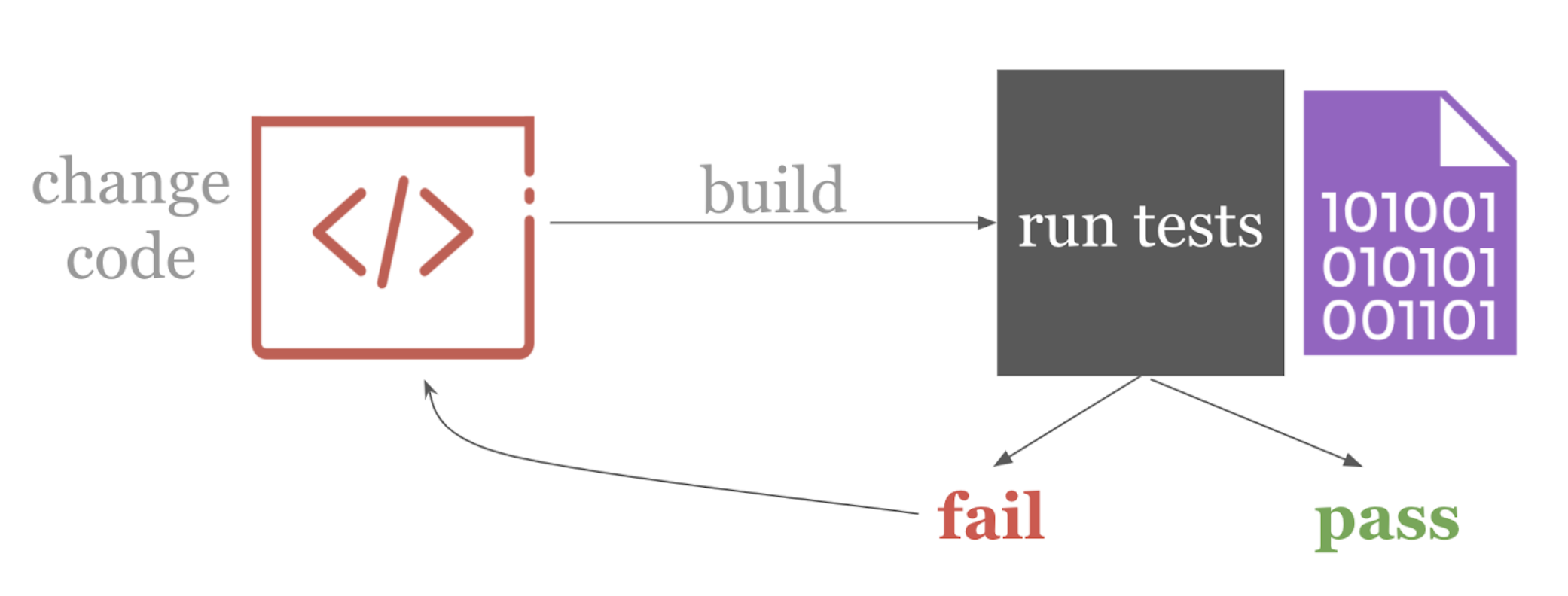
通過這種設置,我們有了自動化——代碼更改觸發一個自動構建,然后進行測試。我們有快速的反饋,因為我們可以快速得到測試結果,所以開發人員可以不斷迭代他們的代碼。而且因為所有這些都是自動發生的,你不需要等待其他人得到反饋——少了一個切換!
那么我們為什么不在ML中使用持續集成呢?一些原因是文化上的,比如數據科學和軟件工程社區之間的低交叉。其他的則是技術性的——例如,為了理解模型的性能,你需要查看諸如準確性、特異性和敏感性等指標。數據可視化可能會幫助你,比如混淆矩陣或損失圖。所以通過/失敗的測試不會減少反饋。理解一個模型是否得到了改進需要一些關于手頭問題的領域知識,因此測試結果需要以一種有效的和可理解的方式進行報告。
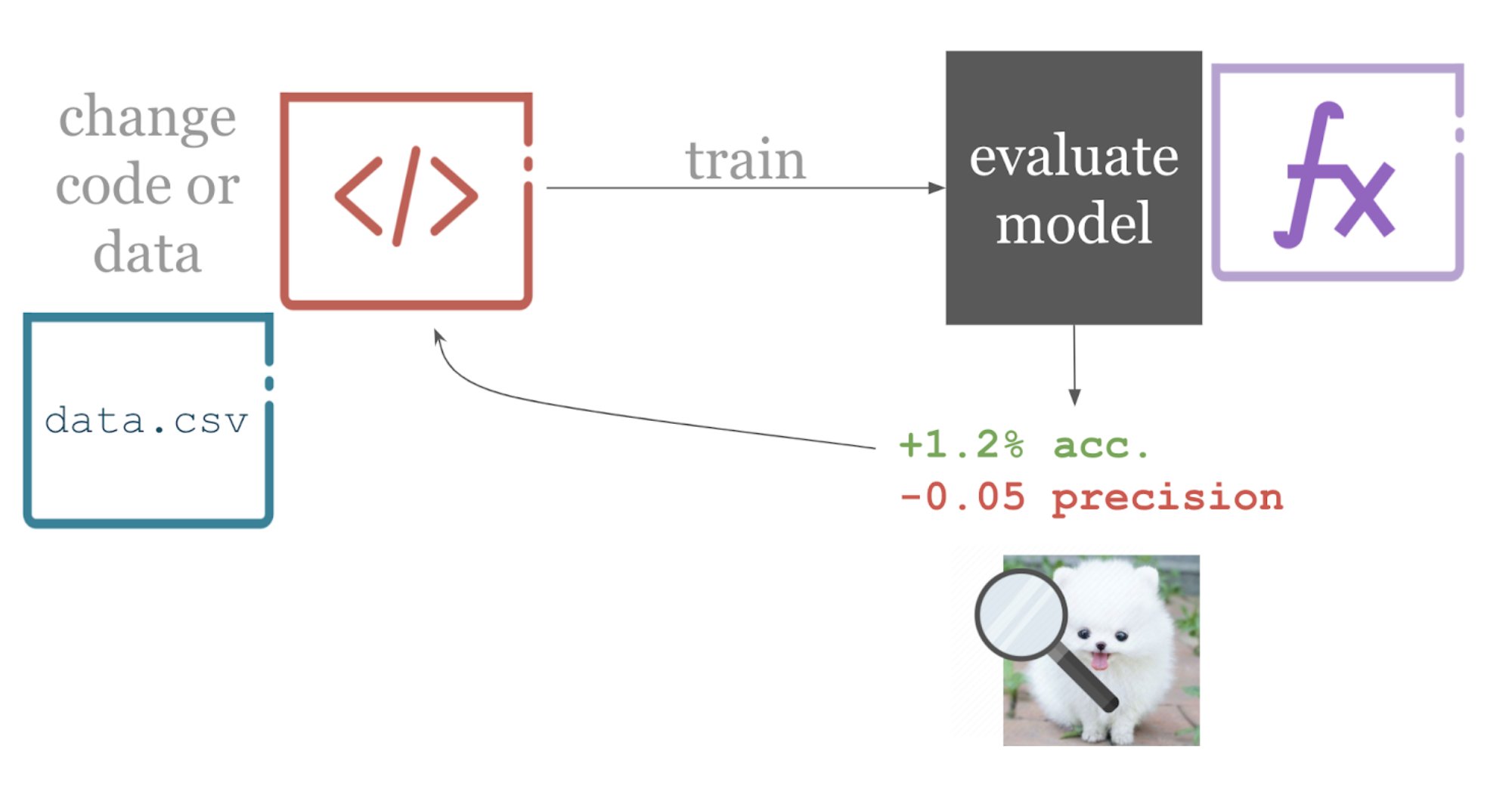
CI系統是如何工作的?
現在我們要更實際一些,讓我們看看典型的CI系統是如何工作的。對于學習者來說,幸運的是,由于GitHub Actions和GitLab CI等工具的出現,障礙從來沒有降低過——它們有清晰的圖形界面和為首次用戶準備的優秀文檔。由于GitHub操作對于公共項目是完全免費的,所以我們將在本例中使用它。
它是這樣工作的:
1、你創建了一個GitHub存儲庫。你創建了一個名為.github/workflows的目錄,并在其中放置了一個特殊的.yaml文件,其中包含你想要運行的腳本。
- $ python train.py
2、你可以以某種方式更改項目存儲庫中的文件,然后Git提交更改。然后,推到GitHub存儲庫。
- # Create a new git branch for experimenting
- $ git checkout -b "experiment"
- $ edit train.py
- # git add, commit, and push your changes
- $ git add . && commit -m "Normalized features"
- $ git push origin experiment
3、一旦GitHub檢測到push,GitHub就會部署他們的一臺計算機來運行.yaml中的函數。
4、如果函數運行成功或失敗,GitHub會返回一個通知。

在GitHub存儲庫的Actions選項卡中找到它
就是這樣!真正奇妙的是,你正在使用GitHub的計算機來運行你的代碼。你所要做的就是更新代碼并將更改推送到存儲庫中,工作流就會自動發生。
回到我在第1步中提到的特殊的.yaml文件——讓我們快速查看一個。它可以有任何你喜歡的名稱,只要文件擴展名是.yaml,并且它存儲在.github/workflows目錄中。這里有一個:
- # .github/workflows/ci.yaml
- name: train-my-model
- on: [push]
- jobs:
- run:
- runs-on: [ubuntu-latest]
- steps:
- - uses: actions/checkout@v2
- - name: training
- run: |
- pip install -r requirements.txt
- python train.py
有很多操作在進行,但大多數操作都是相同的——你可以復制粘貼這個標準的GitHub動作模板,但在“運行”字段中填寫你的工作流。
如果這個文件在你的項目repo中,每當GitHub檢測到對你的代碼的更改(通過push注冊),GitHub Actions就會部署一個Ubuntu運行程序,并嘗試執行你的命令來安裝需求并運行Python腳本。請注意,你必須在項目repo中包含你的工作流所需的文件——這里是requirementes .txt和train.py。
得到更好的反饋
正如我們之前提到的,自動訓練是非常酷的,但重要的是要有一個容易理解的形式的結果。目前,GitHub操作允許你訪問運行的純文本日志。
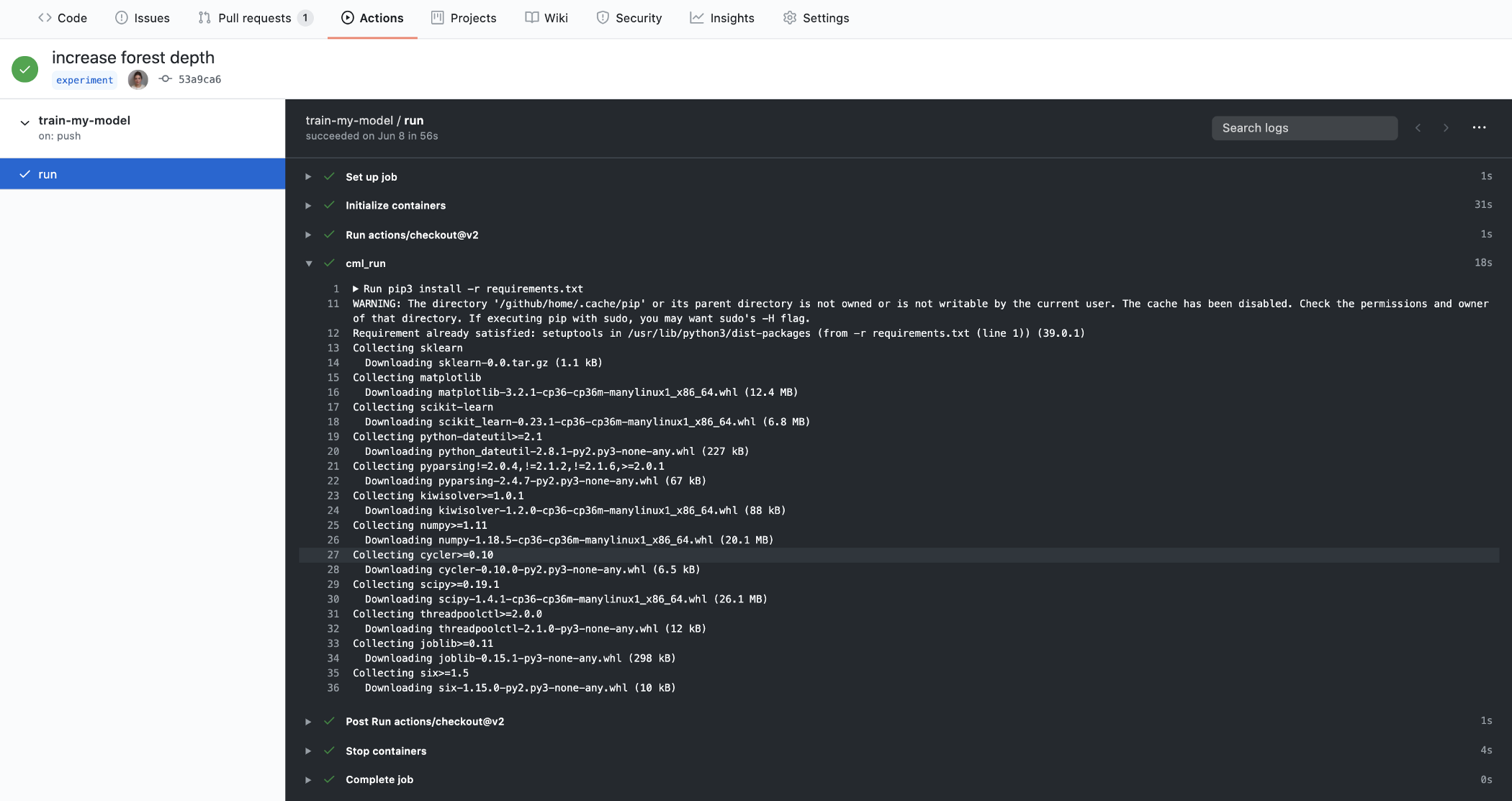
從GitHub動作日志中打印出來的示例
但是理解你的模型的性能是很棘手的。模型和數據是高維的,并且通常是非線性的——如果沒有圖片,這兩件事是特別難以理解的。
我可以向你展示一種將數據viz放入CI循環的方法。在過去的幾個月里,我的團隊在Iterative.ai(我們做數據版本控制)正在開發一個工具包,幫助在機器學習項目中使用GitHub動作和GitLab CI。它被稱為持續機器學習(簡稱CML),并且是開源免費的。
從“讓我們使用GitHub動作來訓練ML模型”的基本思想出發,我們構建了一些函數來提供比通過/失敗通知更詳細的報告。CML幫助你在報告中放入圖像和表格,就像這個由SciKit-learn生成的混淆矩陣:
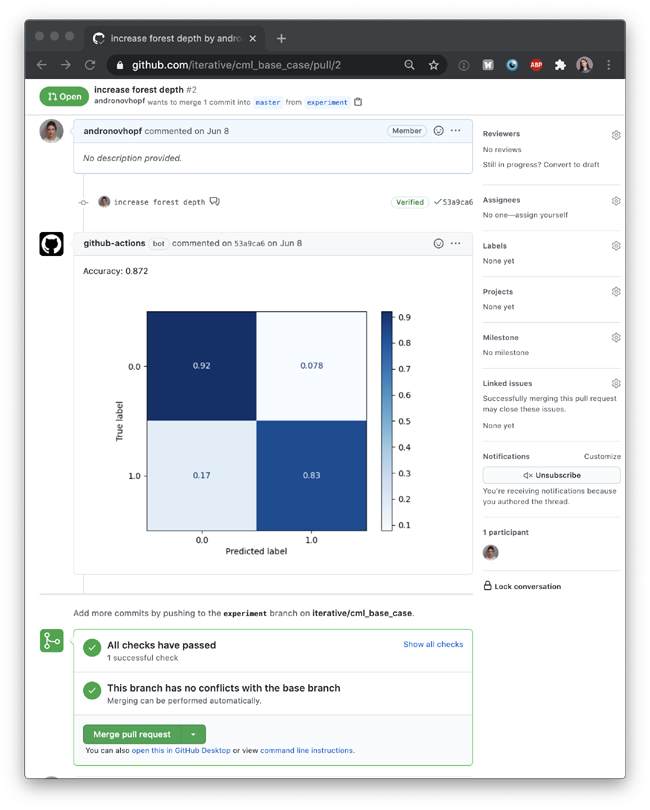
為了制作這個報告,我們的GitHub操作執行了一個Python模型訓練腳本,然后使用CML函數將我們的模型準確性和混淆矩陣寫入一個markdown文檔。然后CML將減價文檔傳遞給GitHub。
我們修改后的.yaml文件包含以下工作流(新添加的行被加粗以示強調):
- name: train-my-model
- on: [push]
- jobs:
- run:
- runs-on: [ubuntu-latest]
- container: docker://dvcorg/cml-py3:latest
- steps:
- - uses: actions/checkout@v2
- - name: training
- env:
- repo_token: ${{ secrets.GITHUB_TOKEN }}
- run: |
- # train.py outputs metrics.txt and confusion_matrix.png
- pip3 install -r requirements.txt
- python train.py
- # copy the contents of metrics.txt to our markdown report
- cat metrics.txt >> report.md
- # add our confusion matrix to report.md
- cml-publish confusion_matrix.png --md >> report.md
- # send the report to GitHub for display
- cml-send-comment report.md
你可以在這里看到整個項目存儲庫。注意,我們的.yaml現在包含更多的配置細節,比如一個特殊的Docker容器和一個環境變量,以及一些要運行的新代碼。容器和環境變量細節在每個CML項目中都是標準的,而不是用戶需要操作的東西,所以請關注代碼。
在工作流中添加了這些CML功能后,我們在CI系統中創建了一個更完整的反饋循環:
- 創建一個Git分支并更改該分支上的代碼。
- 自動訓練模型并產生度量(準確性)和可視化(混淆矩陣)。
- 將這些結果嵌入到Pull請求的可視報告中。
現在,當你和你的團隊成員決定你的變更是否對你的建模目標有積極的影響時,你就有了一個可以檢查的儀表板。另外,Git還將此報告鏈接到你的確切項目版本(數據和代碼)、用于訓練的跑步器以及那次運行的日志。很徹底,不再有那些很久以前就失去了與代碼的任何連接的圖形在你的工作空間中浮動。
這就是數據科學項目中CI的基本思想。明確地說,這個示例是使用CI的最簡單方法之一。在現實生活中,你可能會遇到相當復雜的場景。CML還有一些功能可以幫助你使用存儲在GitHub存儲庫之外的大型數據集(使用DVC),并在云實例上進行訓練,而不是使用默認的GitHub動作運行器。這意味著你可以使用GPU和其他專門的設置。
例如,我做了一個使用GitHub Actions部署EC2 GPU的項目,然后訓練一個神經類型的傳輸模型。以下是我的CML報告:
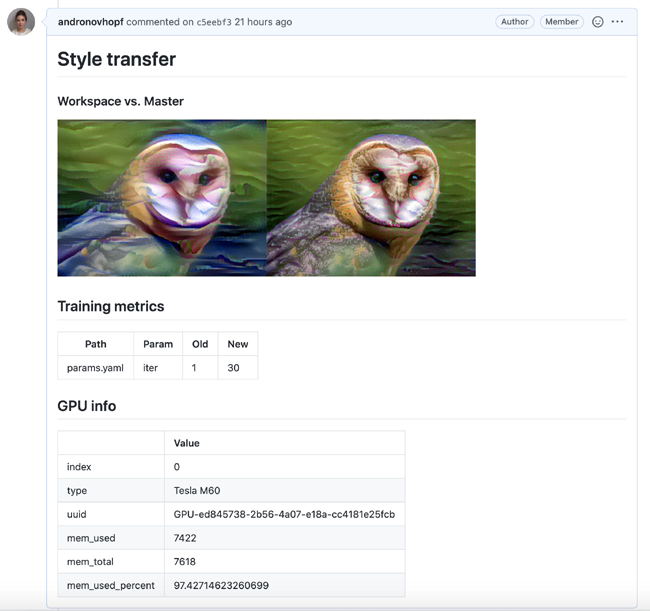
你還可以使用自己的Docker容器,這樣就可以在生產中緊密地模擬模型的環境。以后我將更多地介紹這些高級用例。
關于ML的CI的最后思考
總結一下我們到目前為止所說的:
DevOps不是一種特定的技術,而是一種哲學、一套原則和實踐,用于從根本上重構創建軟件的過程。它之所以有效,是因為它解決了團隊如何工作和試驗新代碼的系統瓶頸。
隨著數據科學在未來幾年的成熟,懂得如何將DevOps原則應用到他們的機器學習項目中的人將成為一種有價值的商品——無論是從薪水還是從組織影響的角度。持續集成是DevOps的主要內容,也是構建具有可靠自動化、快速測試和團隊自治的文化的最有效的已知方法之一。
CI可以通過GitHub Actions或GitLab CI等系統實現,你可以使用這些服務來構建自動模型培訓系統。好處很多:
- 你的代碼、數據、模型和培訓基礎設施(硬件和軟件環境)都是Git版本化的。
- 你正在自動化工作,頻繁地進行測試并獲得快速的反饋(如果使用CML,則使用可視化的報告)。從長遠來看,這幾乎肯定會加速項目的開發。
- CI系統使你的工作對團隊中的每個人都可見。沒有人需要非常費力地搜索你的最佳運行的代碼、數據和模型。
我保證,一旦你進入最佳狀態,通過一個Git提交自動啟動你的模型訓練、記錄和報告是非常有趣的。
你會覺得很酷。















