DevOps二三事:用持續(xù)集成構建自動模型訓練系統(tǒng)的理論和實踐指南
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)。
近幾年來,機器學習飛速發(fā)展,開展機器學習試驗變成小事一樁。有了scikit-learn和Keras這樣的資源庫,只需幾行代碼,就能創(chuàng)建模型。
然而,把數(shù)據(jù)科學項目轉變成有意義的應用程序(比如公告團隊決策或融入產品的模型)卻愈加困難。傳統(tǒng)的機器學習項目涉及許多不同的技能組合,想同時掌握全部技能,即便不是絕無可能也絕非易事——那些罕見的既能開發(fā)優(yōu)質軟件,又能做工程師的數(shù)據(jù)科學家即為獨角獸!
機器學習領域愈加成熟,許多工作都將融合軟件、工程和數(shù)學知識,一些工作已然如此了。
引用傳奇數(shù)據(jù)科學家、工程師、批判觀察家Vicki Boykis博客《數(shù)據(jù)科學現(xiàn)已不同》中的話:“在熱潮后期,數(shù)據(jù)科學漸漸與工程學靠攏。顯而易見的是,數(shù)據(jù)科學家所需技能的可視性將減弱、數(shù)據(jù)依賴性將降低,且會愈加偏向傳統(tǒng)計算機科學課程。”
為什么數(shù)據(jù)科學家需要了解DevOps
有那么多工程和軟件技能,數(shù)據(jù)科學家應該學習什么呢?我選DevOps。
DevOps是開發(fā)和運營的合稱,它于2009年在比利時的一場會議中誕生。該會議旨在緩解技術組織中開發(fā)、運營因長期的巨大分歧而產生的緊張態(tài)勢。軟件開發(fā)人員需要快速產出、頻繁試驗,而運營團隊則優(yōu)先考慮服務的穩(wěn)定性及可用性(這群人讓服務器全天候運轉)。其目標對立,彼此之間更是競爭關系。
這不禁令人想到當下的數(shù)據(jù)科學。通過實驗,數(shù)據(jù)科學家創(chuàng)造價值:用新方式建模、組合、轉換數(shù)據(jù)。同時,聘用數(shù)據(jù)科學家的技術組織更看重穩(wěn)定性。
這種分歧波及范圍廣泛:最新的Anaconda數(shù)據(jù)科學狀況報告顯示,認為自己能詮釋數(shù)據(jù)科學對其組織影響的受訪者不足一半(48%)。據(jù)估計,數(shù)據(jù)科學家創(chuàng)建的模型大多被束之高閣。我們目前沒有十分可行的方式,能在建模團隊及部署團隊間傳遞模型。數(shù)據(jù)科學家、開發(fā)者及落實二者工作的工程師有著截然不同的工具、限制及技能。
DevOps的出現(xiàn)旨在解決開發(fā)者和運營者之間的軟件僵局,并取得了極大成功:許多團隊部署新代碼的頻率從數(shù)月一次變?yōu)橐惶鞌?shù)次。現(xiàn)在面對的是機器學習和運營的對抗,MLOps這一為數(shù)據(jù)科學服務的DevOps原則閃亮登場。

圖源:unsplash
持續(xù)集成
DevOps既是理論,又是實踐,它包括:
- 自動化一切事物
- 快速獲得新想法的反饋
- 減少工作流中的手動交接
在典型的數(shù)據(jù)科學項目中,存在如下應用:
- 自動化一切事物。重復且可預測的部分數(shù)據(jù)處理、模型訓練及模型測試皆可自動化。
- 快速獲得新想法的反饋。當數(shù)據(jù)、代碼或軟件環(huán)境發(fā)生變化時,在類生產環(huán)境下迅速對其進行測試(即,生產中有依賴項和限制的機器)。
- 減少工作流中的手動交接。盡可能為數(shù)據(jù)科學家找尋模型測試的機會,切勿等到開發(fā)人員在生產環(huán)境下檢測模型效果再行動。
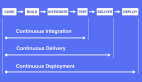
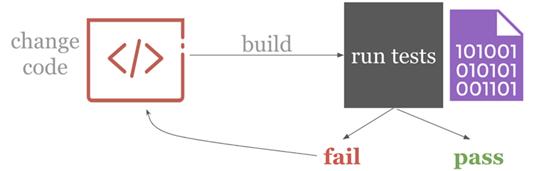
為實現(xiàn)以上目標,DevOps采用的標準是持續(xù)集成(continuous integration, CI)。關鍵在于,改變項目源代碼時(一般是通過git commits更改),軟件被自動創(chuàng)建并測試,每個行為都會得到反饋。通常,CI與創(chuàng)建新功能Git分支的軟件開發(fā)活動模型Git-flow配合使用。功能分支通過自動測試便可候選并入主分支。
CI在軟件開發(fā)過程中的示意圖
由此即可實現(xiàn)自動化——改變代碼觸發(fā)自動構建,測試緊隨其后。由于迅速得到測試結果,便可以得到快速反饋,因此,開發(fā)者能對代碼進行反復迭代。并且,由于一切皆為自動,無需等待他人反饋,實現(xiàn)零切換。
所以,我們?yōu)槭裁床皇褂靡汛嬖谟跈C器學習中的CI呢?我將部分歸因于文化,比如數(shù)據(jù)科學與軟件工程群體的低交叉性。
另一部分就是技術原因。比如,了解模型性能,需查看準確率、特異度和敏感度等指標。要了解模型的性能,就需要查看準確率、特異度和靈感度等指標。數(shù)據(jù)可視化(如混淆矩陣或損失圖)或許會對此有所幫助。所以,測試通過/失敗并不會阻礙反饋。若要了解模型是否得到改進,我們需要了解當前問題領域的知識,所以測試結果需要以高效且可人為詮釋的方式報道。
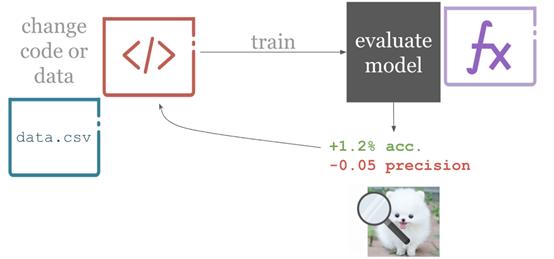
機器學習項目中的連續(xù)集成
持續(xù)集成系統(tǒng)如何運作?
現(xiàn)在,看看典型的CI系統(tǒng)如何運作。多虧了GitHub Actions和GitLab CI這類圖像界面清晰且為新手提供詳細操作文檔的工具,學習CI系統(tǒng)的門檻降至最低。由于GitHub Actions對開源項目完全免費,我們就用它舉例:
其運作方式如下:
(1) 建立一個GitHub倉庫。創(chuàng)建名為.github/workflows的目錄,在目錄中放置一個特殊的.yaml文件,其中包含要運行的腳本,如:
- $ python train.py
(2) 更改項目庫內文件,git commit更新,然后提交到GitHub庫。
- # Create a new git branch for experimenting$ git checkout -b "experiment"
- $ edit train.py# git add, commit, and push your changes
- $ git add . && commit -m "Normalized features"
- $ git push origin experiment
(3) 檢測到推送,GitHub立刻在其中一臺計算機上運行.yaml文件的函數(shù)。
(4) GitHub彈出通知,是否成功運行函數(shù)。

在GitHub倉庫的操作選項卡中找到以上內
就這么簡單!只需更新代碼,并把更新提交到數(shù)據(jù)庫,工作流就自動執(zhí)行。
回到第一步提到的特殊的.yaml文件——快速看一個。隨意命名,文件后綴是.yaml即可,并將其儲存在.github/workflows中。如:
- # .github/workflows/ci.yamlname: train-my-model
- on: [push]jobs:
- run:
- runs-on: [ubuntu-latest]
- steps:
- - uses: actions/checkout@v2
- - name: training
- run: |
- pip install -r requirements.txt
- python train.py
指令多如云,但大多數(shù)都是從一個Action到另一個Action——大可照搬這份GitHubActions指南,記得在“運行”段填寫工作流就好。
若文件在項目庫中,只要GitHub檢測到代碼更新(通過推送變更),GitHub Actions便會部署Ubuntu服務器,嘗試執(zhí)行安裝需求的命令并運行Python腳本。請注意,項目倉庫中必須有工作流程所需文件——在這里為requirements.txt和train.py!
得到更好的反饋
自動訓練很酷,但對所有的結果來說,采用易于理解的格式也很重要。現(xiàn)在,GitHub Actions允許訪問純文本格式的服務器日志。
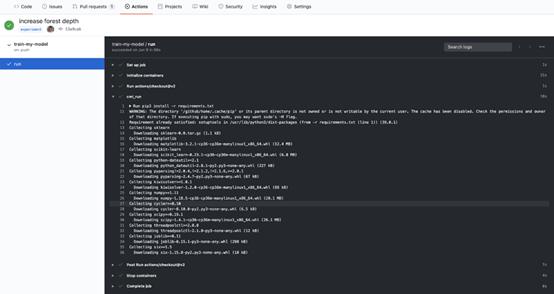
GitHub Actions日志的打印輸出示例
但了解模型性能是個棘手的活兒。模型和數(shù)據(jù)都是高維且非線性的——若無圖片,了解這二者太難了。
我可以展示一種將數(shù)據(jù)可視化放入CI循環(huán)的方法。近幾個月,我在Iterative.ai的團隊(做數(shù)據(jù)版本控制)一直在研究工具包,助力GitHub Actions和GitLab CI在機器學習項目中的使用,稱為持續(xù)機器學習(Continuous Machine Learning ,簡稱CML)。這是開源且免費的。
團隊的基本理念是:“用GitHub Actions訓練機器學習模型”。我們已經建立了一些函數(shù),可給出更詳細的報告而非一個成功/失敗的通知。CML有助于在報告中放置圖片和表格,如這個SciKit-learn生成的混淆矩陣:
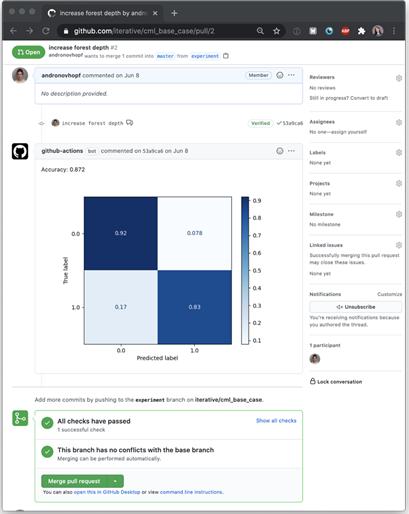
在GitHub中點Pull Request即顯示此報告
為了制作報告,GitHub Actions執(zhí)行Python模型訓練腳本,用CML函數(shù)把模型準確率和混淆矩陣寫入markdown文件。然后CML把markdown文件傳到GitHub。
修改后的.yaml文件包含以下工作流(新添加的行以粗體突出顯示)。
- name: train-my-model
- on: [push]
- jobs:
- run:
- runs-on: [ubuntu-latest]
- container: docker://dvcorg/cml-py3:latest
- steps:
- - uses: actions/checkout@v2
- - name: training
- env:
- repo_token: ${{secrets.GITHUB_TOKEN }}
- run: |
- # train.py outputs metrics.txtand confusion_matrix.png
- pip3 install -rrequirements.txt
- python train.py
- # copy the contents ofmetrics.txt to our markdown report
- cat metrics.txt >>report.md # addour confusion matrix to report.md
- cml-publishconfusion_matrix.png --md >> report.md # send the report to GitHub fordisplay
- cml-send-comment report.md
記住,.yaml現(xiàn)在包含更多詳細配置信息,例如特殊的Docker容器和環(huán)境變量,以及一些要運行的新代碼。每個CML項目中的容器及環(huán)境變量的詳細信息都是固定的,用戶無需操作,只關注代碼就行。
將這些CML函數(shù)添加到工作流中,我們便在CI系統(tǒng)中創(chuàng)建了更完整的反饋循環(huán):
- 建立一個Git分支,在分支上更新代碼。
- 自動訓練模型并生成度量(準確率)和可視化(混淆矩陣)。
- 將這些結果嵌入到Pull Request中的可視報告。
當你和隊友還在考慮更新是否有助于實現(xiàn)建模目標時,各種可參照的可視化表盤就已經新鮮出爐了。另外,該報告通過Git連接到確切項目版本(數(shù)據(jù)和代碼)、訓練所用服務器及服務器的日志。無比詳細!工作空間不再總是漂浮著與代碼無關的圖表了。
這就是CI在數(shù)據(jù)科學項目中的基本概念。明確一下,這只是使用CI的最簡單的實例。實際操作中很可能遇到各種更為復雜的情況。CML也有一些特性,可幫你使用儲存在GitHub庫之外的大數(shù)據(jù)集(使用DVC)并在云端進行訓練,而非在默認的GitHub Actions服務器訓練。這意味著能使用GPU和其它專業(yè)設置。
例如,我用GitHub Actions創(chuàng)建一個項目以部署EC2 GPU,然后訓練神經風格轉換模型。這是我的CML報告:
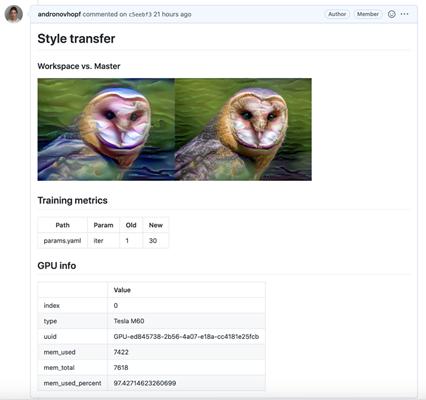
還可使用自己的Docker容器,進一步模擬
CI對機器學習的最后思考
總結一下,DevOps不是一種特定技術。它既是理論,又是一系列原則和實踐,用于徹底重建開發(fā)軟件過程,其高效性在于解決了團隊工作及測試新代碼的系統(tǒng)性瓶頸。
未來,數(shù)據(jù)科學愈加成熟,掌握在機器學習項目中運用DevOps原則的人就更加炙手可熱——薪資可觀,組織影響力大。持續(xù)集成是DevOps的基礎,也是已知的建立具有可靠自動化、快速測試和團隊自治文化的最有效方法之一。
GitHub Actions或GitLab CI之類的系統(tǒng)可實現(xiàn)CI。可使用這些服務構建自動模型訓練系統(tǒng)。其益處頗多:
- 代碼、數(shù)據(jù)、模型和訓練基礎(硬軟件環(huán)境)都是git版本。
- 自動化工作、進行高頻測試并得到迅速反饋(使用CML即可拿到可視化報告)。從長期看,這無疑會加速項目發(fā)展。
- CI系統(tǒng)讓每個團隊成員都能看到工作進展。大家無需絞盡腦汁搜集最佳運行的代碼、數(shù)據(jù)及模型。
圖源:unsplash
一旦入了坑,一鍵git commit就能自動進行模型訓練、記錄并報告,絕對讓你樂翻天。行動起來,感覺棒極了!