













TensorFlow 2入門指南,初學者必備!
什么是Tensorflow?
TensorFlow是谷歌推出的深度學習框架,于2019年發布了第二版。 它是世界上最著名的深度學習框架之一,被行業專家和研究人員廣泛使用。
Tensorflow v1難以使用和理解,因為它的Pythonic較少,但是隨著Keras發行的v2現在與Tensorflow.keras完全同步,它易于使用,易學且易于理解。
請記住,這不是有關深度學習的文章,所以我希望您了解深度學習的術語及其背后的基本思想。
我們將使用非常著名的數據集IRIS數據集探索深度學習的世界。
廢話不多說,我們直接看看代碼。
導入和理解數據集
- from sklearn.datasets import load_iris
- iris = load_iris()
現在,這個 iris 是一個字典。 我們可以使用下面的代碼查看鍵值
- >>> iris.keys()
- dict_keys([‘data’, ‘target’, ‘frame’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
因此,我們的數據在 data 鍵中,目標在 targe 鍵中,依此類推。 如果要查看此數據集的詳細信息,可以使用 iris[ ['DESCR']。
現在,我們必須導入其他重要的庫,這將有助于我們創建神經網絡。
- from sklearn.model_selection import train_test_split #to split data
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import tensorflow as tf
- from tensorflow.keras.layers import Dense
- from tensorflow.keras.models import Sequential
在這里,我們從tensorflow中導入了2個主要的東西,分別是Dense和Sequential。 從tensorflow.keras.layers導入的Dense是緊密連接的一種層。 密集連接的層意味著先前層的所有節點都連接到當前層的所有節點。
Sequential是Keras的API,通常稱為Sequential API,我們將使用它來構建神經網絡。
為了更好地理解數據,我們可以將其轉換為數據幀。 我們開始做吧。
- X = pd.DataFrame(data = iris.data, columns = iris.feature_names)
- print(X.head())
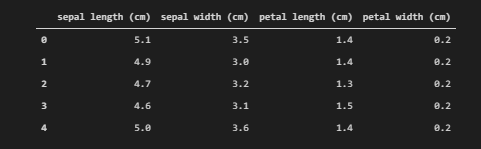
- X.head()
請注意,這里我們設置了column = iris.feature_names,其中feature_names是具有所有4個特征名稱的鍵。
同樣對于目標,
- y = pd.DataFrame(data=iris.target, columns = [‘irisType’])

- y.head()
要查看目標集合中的類數量,我們可以使用
- y.irisType.value_counts()
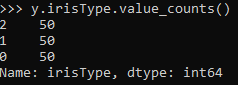
這里我們可以看到我們有3個類,每個類都有標簽0、1和2。
- iris.target_names #它是iris詞典的鍵值

這些是我們必須預測的類名稱。
機器學習的數據預處理
目前,機器學習的第一步就是數據預處理。數據預處理的主要步驟是:
- 填入缺失值
- 將數據分割成為訓練集以及驗證集
- 對數據進行標準化處理
- 將類別性數據轉換成為獨熱向量
缺失值
為了檢查是否存在缺失值,我們可以用pandas.DataFrame.info()來進行檢查工作。
- X.info()
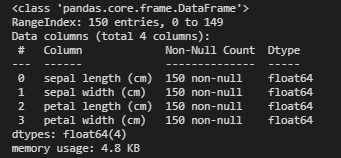
這樣我們就可以看到我們(很幸運地)沒有缺失值,并且所有特征都是float64格式的。
分割為訓練集和測試集
為了將數據集分割為訓練集和測試集,我們可以使用先前已經引入過的sklearn.model_selection中的train_test_split。
- X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.1)
其中test_size是一種聲明,它說明我們希望整個數據集的10%被用來做為測試數據。
數據的標準化
一般情況下,當數據的偏差非常大的時候,我們會對數據進行標準化。為了查看偏差值,我們可以使用pandas.DataFrame中的var()函數來檢查所有列的偏差值。
- X_train.var(), X_test.var()
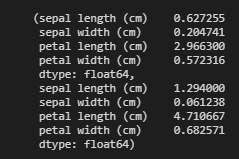
這樣我們便可以看到,X_train和X_test的偏差值都非常低,因此無需對數據進行標準化。
將分類數據轉換為一個獨熱向量
因為我們知道我們的輸出數據是已經使用iris.target_name檢查過的3個類之一,所以好消息是,當我們加載目標時,它們已經是0、1、2格式,其中0=1類,1=2類,依此類推。
這種表示方式的問題在于,我們的模型可能會賦予越高的數字更高的優先級,這可能會導致結果有偏差。 因此,為了解決這個問題,我們將使用單熱點表示法。 你可以在這里了解更多關于一個熱門載體的信息。 我們可以使用內置的KERS TO_CATEGRICAL,也可以使用skLearn中的OneHotEncoding。 我們將使用to_classical。
- y_train = tf.keras.utils.to_categorical(y_train)
- y_test = tf.keras.utils.to_categorical(y_test)
我們將只檢查前5行,以檢查它是否已正確轉換。
- y_train[:5,:]
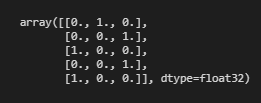
是的,我們已經把它轉換成了獨熱的表達方式。
最后一件事
我們可以做的最后一件事是將我們的數據轉換回Numpy數組,這樣我們就可以使用一些額外的函數,這些函數將在稍后的模型中對我們有所幫助。 要做到這一點,我們可以使用
- X_train = X_train.values
- X_test = X_test.values
讓我們看看第一個訓練示例的結果是什么。
- X_train[0]

在這里,我們可以看到第一個訓練示例中4個特征的值,它的形狀是(4),
當我們在它們上使用to_Category時,我們的目標標簽已經是數組格式。
機器學習模型
現在,我們終于準備好創建我們的模型并對其進行訓練。 我們將從一個簡單的模型開始,然后我們將轉到復雜的模型結構,在那里我們將介紹Keras中的不同技巧和技術。
讓我們對我們的基本模型進行編碼
- model1 = Sequential() #Sequential Object
首先,我們必須創建一個Sequential對象。 現在,要創建一個模型,我們所要做的就是根據我們的選擇添加不同類型的層。 我們將制作一個10層的Dense層模型,這樣我們就可以觀察到過擬合,并在以后通過不同的正則化技術來減少它。
- model1.add( Dense( 64, activation = 'relu', input_shape= X_train[0].shape))
- model1.add( Dense (128, activation = 'relu')
- model1.add( Dense (128, activation = 'relu')
- model1.add( Dense (128, activation = 'relu')
- model1.add( Dense (128, activation = 'relu')
- model1.add( Dense (64, activation = 'relu')
- model1.add( Dense (64, activation = 'relu')
- model1.add( Dense (64, activation = 'relu')
- model1.add( Dense (64, activation = 'relu')
- model1.add( Dense (3, activation = 'softmax')
請注意,在我們的第一層中,我們使用了一個額外的參數INPUT_Shape。 此參數指定第一層的尺寸。 在這種情況下,我們不關心訓練示例的數量。 相反,我們只關心功能的數量。 因此,我們傳入任何訓練示例的形狀,在我們的示例中,它是(4,)在input_Shape內。
請注意,我們在輸出層中使用了Softmax(激活函數),因為它是一個多類分類問題。 如果這是一個二進制分類問題,我們會使用Sigmoid激活函數。
我們可以傳入任何我們想要的激活函數,如Sigmoid或linear或tanh,但實驗證明relu在這類模型中表現最好。
現在,當我們定義了模型的形狀后,下一步是指定它的損耗、優化器和度量。 我們在keras中使用Compile方法指定這些參數。
- model1.compile(optimizer='adam', loss= 'categorical_crossentropy', metrics = ['acc'])
在這里,我們可以使用任何優化器,如隨機梯度下降、RMSProp等,但我們將使用Adam。
我們在這里使用CATEGRICAL_CROSENTROPY是因為我們有一個多類分類問題,如果我們有一個二進制分類問題,我們將使用BINARY_CROSENTROPY。
衡量標準對于評估一個人的模型是很重要的。 我們可以根據不同的度量標準來評估我們的模型。 對于分類問題,最重要的衡量標準是準確度,它表明我們的預測有多準確。
我們模型的最后一步是將其匹配到訓練數據和訓練標簽上。 讓我們對它進行編碼。
- history = model1.fit(X_train, y_train, batch_size = 40, epochs=800, validation_split = 0.1
fit返回一個回調,其中包含我們訓練的所有歷史記錄,我們可以使用它來執行不同的有用任務,如繪圖等。
歷史回調有一個名為history的屬性,我們可以將其作為history.history進行訪問,這是一個包含所有損失和指標歷史的字典,即,在我們的示例中,它具有Loss、Acc、val_loses和val_acc的歷史記錄,并且我們可以將每個單獨的歷史記錄作為 history.history.loss 或 history.history['val_acc'] 等進行訪問。
我們有一個指定的epoch數為800,batch大小為40,驗證拆分為0.1,這意味著我們現在有10%的驗證數據,我們將使用這些數據來分析我們的訓練。 使用800個epoch將過度擬合數據,這意味著它將在訓練數據上執行得非常好,但在測試數據上則不會。
當模型進行訓練時,我們可以看到我們在訓練集和驗證集上的損失和準確性。

在此,我們可以看到,訓練集上的準確率是100%,驗證集上的準確率則為67%,這對于這樣一個模型來說已經很出色了。接下來就讓我們畫出圖像。
- plt.plot(history.history['acc'])
- plt.plot(history.history['val_acc'])
- plt.xlabel('Epochs')
- plt.ylabel('Acc')
- plt.legend(['Training', 'Validation'], loc='upper right')
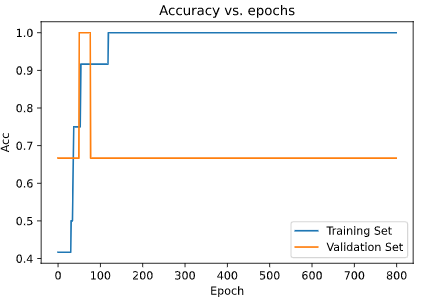
我們可以很清楚地看到,訓練集上的準確率要比驗證集上高得多了。
類似地,我們用如下方法畫出損失:
- plt.plot(history.history['loss'])
- plt.plot(history.history['val_loss'])
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend(['Training', 'Validation'], loc='upper left')
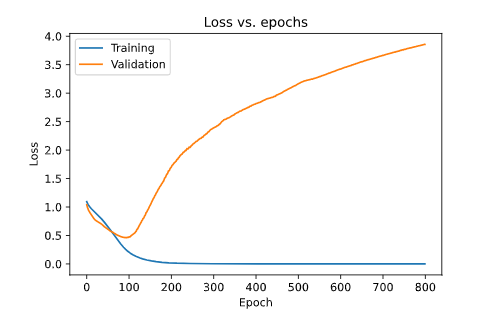
在此,我們可以很清楚地看到,驗證集上的損失比訓練集上要大得多了,這是因為數據被過擬合了。
為了看看模型的表現是不是好,我們可以使用model.evaluate來查看。我們要將數據和標簽放入評估函數中。
- model1.evaluate(X_test, y_test)

這樣,我們就可看到模型的準確率為88%,這對于一個過擬合的模型來說已經很好了。
正則化
讓我們通過將正則化添加到我們的模型中來使它變得更好。 正則化將減少我們模型的過度擬合,并將改進我們的模型。
我們將在我們的模型中添加L2正則化。 單擊 此處了解有關L2正則化的更多信息。 要在我們的模型中添加L2正則化,我們必須指定要添加正則化的層,并給出一個附加參數kernel_Regularizer,然后傳遞tf.keras.Regularizers.l2()。
我們還將在我們的模型中實現一些dropout,這將幫助我們更好地減少過擬合,從而獲得更好的性能。 要閱讀更多關于dropout背后的理論和動機,請參閱這篇文章。
讓我們重新定義這個模型吧。
- model2 = Sequential()
- model2.add(Dense(64, activation = 'relu', input_shape= X_train[0].shape))
- model2.add( Dense(128, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add( Dense (128, activation = 'relu',kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add(tf.keras.layers.Dropout(0.5)
- model2.add( Dense (128, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add(Dense(128, activation = 'relu', kernel_regularizer = tf.keras.regularizers.l2(0.001)
- ))
- model2.add( Dense (64, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add( Dense (64, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add(tf.keras.layers.Dropout(0.5)
- model2.add( Dense (64, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add( Dense (64, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
- model2.add( Dense (3, activation = 'softmax', kernel_regularizer=tf.keras.regularizers.l2(0.001)
- ))
如果你仔細觀察,我們所有的層和參數都是一樣的,除了我們在每個dense層中增加了2個dropout層和正則化。
我們將保留所有其他東西(損失、優化器、epoch等)一樣。
- model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
- history2 = model2.fit(X_train, y_train, epochs=800, validation_split=0.1, batch_size=40)
現在讓我們評估一下模型。

你猜怎么著? 通過加入正則化和dropout層,我們的準確率從88%提高到94%。 如果我們增加了BN層,它將會進一步改善。
讓我們把它畫出來。
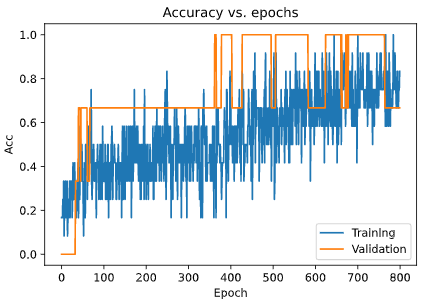
準確率
- plt.plot(history2.history['acc'])
- plt.plot(history2.history['val_acc'])
- plt.title('Accuracy vs. epochs')
- plt.ylabel('Acc')
- plt.xlabel('Epoch')
- plt.legend(['Training', 'Validation'], loc='lower right')
- plt.show()
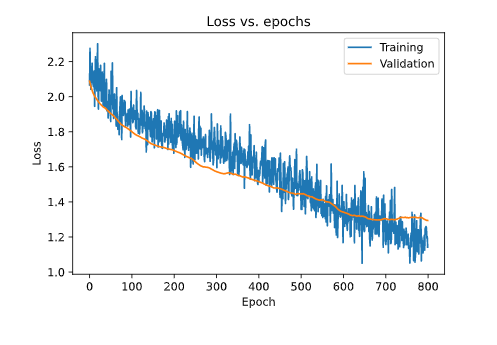
- plt.plot(history2.history['loss'])
- plt.plot(history2.history['val_loss'])
- plt.title('Loss vs. epochs')
- plt.ylabel('Loss')
- plt.xlabel('Epoch')
- plt.legend(['Training', 'Validation'], loc='upper right')
- plt.show()
洞見
如此一來,我們就非常成功地改善了模型的過擬合,并且將模型準確率提升了幾乎6%,這對于一個小數據集來說是很好的改善。
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。





















