













利用SQL和Python分別實(shí)現(xiàn)人流量查詢,考驗(yàn)邏輯思維的時(shí)候到了
本來這篇是要寫Python的可視化的,但無意中發(fā)現(xiàn)了一道題目,發(fā)現(xiàn)通過這道題可以很好地鍛煉一下邏輯思維能力,而且也可以復(fù)習(xí)下SQL和Python的編寫,于是便決定先寫這篇了。
通過這道題我們會(huì)發(fā)現(xiàn),其實(shí)在分析工作中,最重要的能力是邏輯思維,程序只不過是實(shí)現(xiàn)邏輯的工具,沒有邏輯思維能力,程序就是無本之源。而且,雖然實(shí)現(xiàn)一個(gè)結(jié)果會(huì)有多種邏輯,但好的邏輯會(huì)讓我們的程序更具簡(jiǎn)潔性、可觀性、高效性。
下面是結(jié)合自身理解所總結(jié)的兩類實(shí)現(xiàn)邏輯,我相信肯定還會(huì)有更優(yōu)秀的邏輯在某些大牛的腦中!
案例介紹
案例來源于LeetCode,這樣的需求在時(shí)間序列數(shù)據(jù)中還是較為常見的。
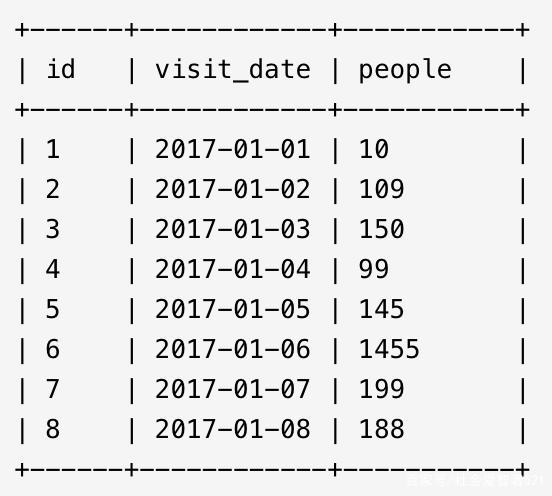
某市體育館每日人流量信息被記錄在stadium表的三列信息中:序號(hào) (id)、日期 (visit_date)、 人流量 (people),找出至少連續(xù)三行人流量不少于100的記錄。
思路分析
最簡(jiǎn)單的思路肯定是對(duì)stadium表進(jìn)行三次笛卡爾積連接,但這種方式在數(shù)據(jù)量大時(shí)不可取,而且也不具備泛化性(譬如需求改成至少連續(xù)十行)。網(wǎng)上也流傳著阿里的編程規(guī)范——禁止三表以上的連接。
總之,這種思路不是我們?cè)摬扇〉模覀冃枰獙ふ移渌悸贰?/p>
(1)構(gòu)建等差數(shù)列
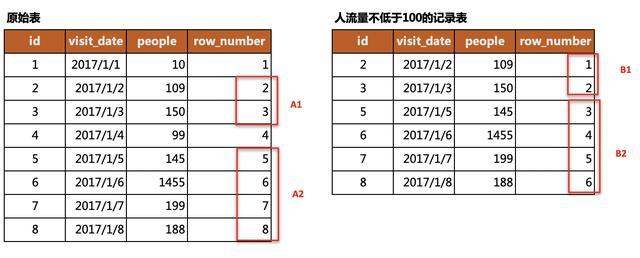
從上圖中我們能發(fā)現(xiàn)一個(gè)規(guī)律,滿足條件的數(shù)據(jù)區(qū)域在原始表和結(jié)果表中的行編號(hào)均是等差數(shù)列,兩個(gè)等差數(shù)列的差值是固定的。譬如,數(shù)列A1和B1的差值均為1;數(shù)列A2和B2的差值均為2。
只要我們保證每塊區(qū)域等差數(shù)列的差值各不相等,那我們就可以通過篩選差值出現(xiàn)的次數(shù)來篩選滿足條件的區(qū)域。例如,差值2出現(xiàn)了4次,滿足條件,那該差值對(duì)應(yīng)的記錄就是我們需要的數(shù)據(jù)。
構(gòu)建差值的方式除了通過行編號(hào)外,也還有其它方式,大家可以想一想。
(2)數(shù)據(jù)切片
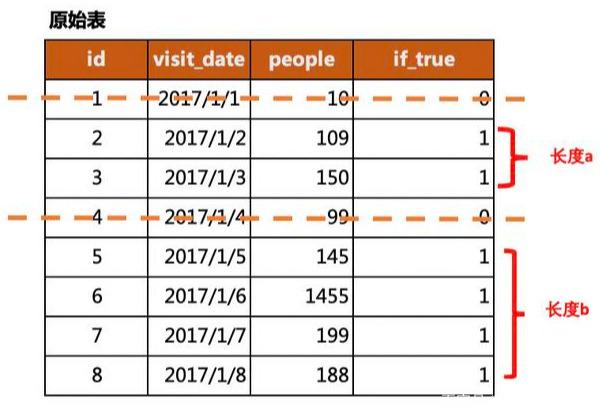
從圖中可看出,if_true是輔助列,表示是否滿足條件,1為True,0為False。我們要選擇滿足條件的區(qū)域,可通過用0對(duì)該列進(jìn)行切片,得到的是全為1的不同長(zhǎng)度的小數(shù)列,根據(jù)每個(gè)小數(shù)列的長(zhǎng)度來篩選滿足條件的區(qū)域。
在圖中就是得到了長(zhǎng)度為a和b的數(shù)列,通過計(jì)算數(shù)列的長(zhǎng)度來找出滿足條件的區(qū)域。
程序?qū)崿F(xiàn)
上節(jié)我們選擇了兩種思路,其中Python兩種思路都可以實(shí)現(xiàn),SQL可實(shí)現(xiàn)第一種思路。本節(jié)用SQL實(shí)現(xiàn)第一種思路,用Python實(shí)現(xiàn)第二種思路。
(1)SQL
- select id,visit_date,people
- from
- (select t2.*,count(1) over(partition by rn2) rn3
- from
- (selectt1.*,rn1 - row_number() over(order by visit_date) rn2
- from
- (select *,row_number() over() as rn1
- from stadium order by visit_date)t1 #t1表對(duì)日期升序排列后生成行編號(hào)
- where people>=100) t2 #t2表篩選人數(shù)不低于100的數(shù)據(jù),并用原行編號(hào)減去新生成的行編號(hào)得到差值
- where 1=1) t3 #t3表統(tǒng)計(jì)每類差值出現(xiàn)的次數(shù)
- where rn3>2 #篩選次數(shù)大于2的數(shù)據(jù)即為所需要的數(shù)據(jù)
因?yàn)閷?shí)際中表中的ID幾乎都不是連續(xù)的數(shù)字,所以為了保證泛化性就先生成了行編號(hào),這樣就不用依賴于ID了。
除此之外也還可以通過用戶變量等方式實(shí)現(xiàn),大家可以試著想一想。
(2)Python
- import pandas as pd
- dt=pd.DataFrame({"id":range(1,9),
- "visit_date":pd.date_range(start="2017-01-01",periods=8),
- "people":[10,109,150,99,145,1455,199,188]})
- dt["col1"]=dt["people"].apply(lambda x : 1 if x>=100 else 0)
- #生成人數(shù)是否不低于100的新列
- dt['counter'] = (dt["col1"]==0).cumsum()
- #按照col1列是否為0計(jì)算累計(jì)和,標(biāo)記每個(gè)連續(xù)區(qū)域
- dt = dt[dt["col1"] !=0]
- #剔除人數(shù)低于100的記錄
- gb=dt.groupby("counter")["id"].count()
- # 統(tǒng)計(jì)各標(biāo)記值的次數(shù)
- result=dt[dt["counter"].isin(gb[gb>2].index)]
- #篩選滿足條件的數(shù)據(jù)
這里有一點(diǎn)需要注意,如果直接將col1列轉(zhuǎn)為字符串按0進(jìn)行切片的話,雖然可以求出滿足條件的區(qū)域數(shù)量和長(zhǎng)度,但很難再尋找到具體的區(qū)域。
- split_col1="".join([str(i) for i in dt["col1"]]).split("0")
原本是按照的這種思路,但發(fā)現(xiàn)尋找長(zhǎng)度符合字符串在原列表中的索引時(shí)會(huì)比較麻煩,尤其是當(dāng)需要查找多個(gè)索引值時(shí)。
但此種思路還是非常重要,因?yàn)樵谥皇怯?jì)算連續(xù)區(qū)域的最大值時(shí)會(huì)非常簡(jiǎn)單。
結(jié)語
以上只是兩種簡(jiǎn)單的邏輯,其實(shí)還有一些邏輯方法,但其本質(zhì)大都差不多,本文就不一一列舉了。至于是否還有更高效的邏輯方法,就等著大牛們來指導(dǎo)吧。
如果有完整看完的朋友就會(huì)發(fā)現(xiàn),一個(gè)簡(jiǎn)單的例子就可以有多種實(shí)現(xiàn)方法,在將每種方法都自己寫一遍的過程中,就是對(duì)已有知識(shí)的一種梳理和復(fù)習(xí)。














