













一個數據庫SQL查詢的數次輪回
本文譯自:http://coding-geek.com/how-databases-work
我們使用數據庫,直觀感受上是客戶端發(fā)送一個 SQL,數據庫把這個SQL執(zhí)行一下,查出來數據返回給客戶端。但其實SQL在背后被轉換,優(yōu)化,歷經許多「磨難」才把結果給取回來。
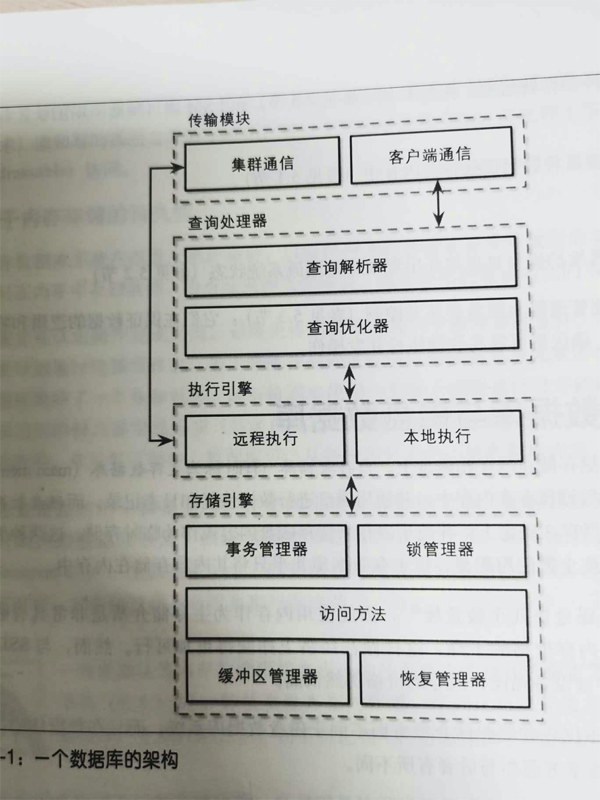
如上圖, 我們看到是從查詢處理器里經過解析器,優(yōu)化器,才進入的執(zhí)行引擎。
今天我們先來看查詢管理器,后面再重點來看查詢的優(yōu)化器是怎樣精打細算的。
查詢管理器
這一部分是數據庫功能體現。在這部分里,會將寫得不好的查詢轉換成可以快速執(zhí)行代碼, 然后執(zhí)行它,并將結果返回給客戶端。這個過程會包含多個步驟:
- 首先解析查詢是否是合法的
- 然后會將查詢重寫,去除沒用的操作符,并做一些預優(yōu)化
- 對查詢優(yōu)化以提升性能,將查詢轉換成執(zhí)行和數據訪問計劃
- 編譯查詢計劃
- 執(zhí)行
這部分里,對最后兩點我們不會說太多,相對來說他倆沒那么關鍵。
查詢解析器
每個SQL語句都會經過分析器去校驗語法是否正確。如果你寫錯了,解析器會拒絕查詢。比如你手誤,把SELECT 寫成了 SLECT,那直接會停止在這兒。
此外,還會檢查關鍵詞順序是否正確。
然后,查詢SQL中的表名和列名也會分析,解析器會通過數據庫的 metadata 來檢查以下內容:
- 表是否存在
- 表中對應的查詢字段是否存在
- 對應的操作符是不是能作用在指定的列上(比如不能把一個數字和字符串比大小,也不能給一個integer用substring)
之后會檢查查詢中對應的表你是否有權限去讀或寫,畢竟這些訪問權限是DBA分配的。
在解析的過程中, 查詢SQL 會被轉換成數據庫的內部表示形式(一般是一棵樹)。如果一切 OK,這個轉換后的內容會發(fā)送給查詢「重寫器」
查詢 Rewriter
在這一步,我們拿到了一個查詢的內部表示形式,重寫器的目標是要:
- 對查詢做預優(yōu)化
- 避免無用的操作
- 幫助優(yōu)化器發(fā)現最佳方案
重寫器會對查詢執(zhí)行一系列已知的規(guī)則。如果查詢符合某個規(guī)則的模式,就會應用這個規(guī)則來重寫查詢。以下是(可選)的規(guī)則:
視圖合并:如果在查詢中使用了視圖,那視圖將會隨著該視圖的SQL代碼進行轉換。
子查詢打平:有子查詢的查詢很難優(yōu)化,因此重寫器將嘗試修改查詢,甚至刪除子查詢。
例如
- SELECT PERSON.*
- FROM PERSON
- WHERE PERSON.person_key IN
- (SELECT MAILS.person_key
- FROM MAILS
- WHERE MAILS.mail LIKE 'christophe%');
就會被這條SQL替換
- SELECT PERSON.*
- FROM PERSON, MAILS
- WHERE PERSON.person_key = MAILS.person_key
- and MAILS.mail LIKE 'christophe%';
- 去除無用的操作符:如果你用了DISTINCT,但你已經有一個UNIQUE約束以保證數據唯一,那DISTINCT關鍵字就會被刪除。
- 消除多余的連接:如果你有兩次相同的連接條件,因為一個連接條件被隱藏在視圖中,或者由于傳遞性而導致無用的連接,則將其刪除。
- 持續(xù)的算術評估:如果查詢是需要計算的內容,那么在重寫過程中將對其進行一次計算。比如,把WHERE AGE> 10 + 2轉換為WHERE AGE> 12,然后將TODATE(“ 日期”)轉換為datetime格式的日期
- (高級)分區(qū)修正:如果你使用了分區(qū)表,重寫器可以找到要使用的分區(qū)。
- (高級)實例化視圖重寫:如果已經有了和查詢子集匹配的實例化視圖,重寫器會檢查該視圖是否是最新視圖,并修改查詢使用實例化視圖而不是原始表。
- (高級)自定義規(guī)則:如果你創(chuàng)建了重寫查詢的自定義規(guī)則,那重寫器會執(zhí)行這些規(guī)則(高級)Olap轉換:分析/窗口函數,星型連接,匯總…也都會進行轉換(但是具體是由重寫器還是優(yōu)化器完成的取決于數據庫,因為這兩個過程鄰近)。
這個重寫后的查詢會發(fā)送給查詢優(yōu)化器,有趣的來了。
統(tǒng)計
在進入數據庫如何優(yōu)化查詢之前,我們需要先談談統(tǒng)計信息,因為沒有統(tǒng)計信息,數據庫就會很傻。如果你不告訴數據庫分析自己的數據,它不會這樣做,而且會做出錯誤的假設。
那數據庫需要什么信息呢?
我們大概說一下論數據庫和操作系統(tǒng)如何存儲數據的。他們使用的最小單位稱為頁或塊(默認為4或8 KB)。也就是說,如果你只需要1 KB,也會占一頁。如果頁面占用8 KB,那就會浪費7 KB。
回到統(tǒng)計來,當你要求數據庫獲取統(tǒng)計信息時,它會計算這些內容:
- 一個表中的行或頁的數量
- 一個表里的每一列
- 單獨的數據內容
- 數據的長度(最小,最大,平均)
- 數據區(qū)間信息(最小、最大、平均)
- 表的索引信息
這些統(tǒng)計信息會幫助優(yōu)化器更好的預估查詢中磁盤I/O,CPU以及內存的使用。
每一列的統(tǒng)計信息都很重要。比如一個 PERSON 表,需要在 LAST_NAME, FIRST_NAME兩列做連接,通過統(tǒng)計,數據庫能知道FIRST_NAME這一列共多少個不同的值,LAST_NAME有多少個不同的值。所以數據庫會使用LAST_NAME,FIRST_NAME來連接,而不是FIRST_NAME,LAST_NAME,因為LAST_NAME不太可能相同,會少產生數據。大多數情況下,數據庫的前兩三個字符比較 LAST_NAME就足夠了。
當然這些是基本的統(tǒng)計信息,你也可以讓數據庫計算 histograms 這種更高階的統(tǒng)計數據。最常使用的值,質量等等,通過這些附加信息,可以幫助數據庫找到更高效的查詢計劃,特別是像等值查詢,以及范圍查詢這種。因為數據庫已經知道這種情況下有多少條記錄。
這些統(tǒng)計信息記錄在數據庫的元數據中。因此也是需要花時間不斷更新的。這也是為啥在大多數數據庫里他都不自動更新。
后面的文章,會描述查詢優(yōu)化器的一些細節(jié)。
讀完這部分之后,擴展閱讀:
- The initial research paper (1979) on cost based optimization: Access Path Selection in a Relational Database Management System. This article is only 12 pages and understandable with an average level in computer science.
- A very good and in-depth presentation on how DB2 9.X optimizes queries here
- A very good presentation on how PostgreSQL optimizes queries here. It’s the most accessible document since it’s more a presentation on “let’s see what query plans PostgreSQL gives in these situations“ than a “let’s see the algorithms used by PostgreSQL”.
- The official SQLite documentation about optimization. It’s “easy” to read because SQLite uses simple rules. Moreover, it’s the only official documentation that really explains how it works.
- A good presentation on how SQL Server 2005 optimizes queries here
- A white paper about optimization in Oracle 12c here
- 2 theoretical courses on query optimization from the authors of the book “DATABASE SYSTEM CONCEPTS”here and there. A good read that focuses on disk I/O cost but a good level in CS is required.
- Another theoretical course that I find more accessible but that only focuses on join operators and disk I/O.
本文轉載自微信公眾號「 Tomcat那些事兒」,可以通過以下二維碼關注。轉載本文請聯(lián)系 Tomcat那些事兒公眾號。














