輸入示例,自動生成代碼:TensorFlow官方工具TF-Coder已開源
如何使編程更加便捷?最近,谷歌 TensorFlow 開源了一個幫助開發者寫 TensorFlow 代碼的程序合成工具 TF-Coder。
- 項目地址:https://github.com/google-research/tensorflow-coder
- Google Colab 試用地址:https://colab.research.google.com/github/google-research/tensorflow-coder/blob/master/TF-Coder_Colab.ipynb
- 論文地址:https://arxiv.org/pdf/2003.09040.pdf
用過 TensorFlow 框架的應該都知道,在操縱張量時,需要跟蹤多個維度、張量形狀和數據類型兼容性,當然還需要考慮數學正確性。此外,TensorFlow 有數百種操作,找到要使用的正確操作也是一項挑戰。
那么,除了直接對張量操縱進行編碼以外,如果僅通過一個說明性示例進行演示,就能自動獲取相應的代碼呢?這個想法聽起來很誘人,而 TensorFlow Coder(TF-Coder)使這成為可能!
TF-Coder 的原理是:給出期望張量變換的輸入 - 輸出示例,TF-Coder 運行組合搜索,找出能夠執行此變換的 TensorFlow 表達式,并最終輸出對應的 TensorFlow 代碼。

給出輸入 - 輸出示例,TF-Coder 在 1.3 秒內找出解決方案。
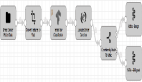
TF-Coder 的合成算法如下所示:

下面的動圖展示了使用 TF-Coder 解決張量操縱問題的過程:

那么,TF-Coder 工具可以在哪些場景中起到作用呢?
TF-Coder:通過示例進行 TensorFlow 編程
假如你想將包含 M 個元素的向量(下例中指‘rows’)和包含 N 個元素的向量(下例中指‘cols’)依次進行相加,生成一個包含所有成對和的 M x N 矩陣。
使用 TF-Coder,你只需提供一個輸入 - 輸出示例(M=3,N=4)即可完成該操作,無需逐行進行編程。
例如輸入張量為:
- inputs = {
- 'rows': [10, 20, 30],
- 'cols': [1, 2, 3, 4],
- }
對應的輸出張量為:
- output = [[11, 12, 13, 14],
- [21, 22, 23, 24],
- [31, 32, 33, 34]]
基于以上輸入 - 輸出信息(默認情況下已經輸入到 TF-Coder Colab 中),TF-Coder 工具將在一秒內自動找到合適的 TensorFlow 代碼:
- tf.add(cols, tf.expand_dims(rows, 1))
這個簡單的例子旨在說明 TF-Coder 利用示例進行編程的思想。而 TF-Coder 的功能不止于此,它還可用于更難的編程問題中。
TF-Coder 幫你找到正確的函數
假設你正在處理數值特征,如某個物品的價格。數據集中的價格范圍很廣,例如從低于 10 美元到超出 1000 美元不等。如果這些價格被直接用作特征,則模型可能出現過擬合,在模型評估階段可能難以處理異常價格。
為了解決上述問題,你可能需要使用 bucketing,來將數字價格轉換為類別特征。例如,使用 bucket 邊界 [10, 50, 100, 1000] 意味著低于 10 美元的價格應歸入 bucket 0,10 美元至 50 美元的價格應歸入 bucket 1,依此類推。
在選擇 bucket 邊界之后,如何使用 TensorFlow 將數值價格映射到 bucket 索引呢?例如,給出以下 bucket 邊界和物品價格:
- # Input tensors
- boundaries = [10, 50, 100, 1000]
- prices = [15, 3, 50, 90, 100, 1001]
計算每個項的 bucket 編號:
- # Output tensor
- bucketed_prices = [1, 0, 2, 2, 3, 4]
盡管 TensorFlow 具備多種 bucketing 操作,但要弄清楚哪種操作適合執行這種 bucketing,也是比較棘手的事情。由于 TF-Coder 可以通過行為識別數百個 Tensor 操作,因此你可以通過提供輸入 - 輸出示例來查找正確的操作:
- # Input-output example
- inputs = {
- 'boundaries': [10, 50, 100, 1000],
- 'prices': [15, 3, 50, 90, 100, 1001],
- }
- output = [1, 0, 2, 2, 3, 4]
只需幾秒鐘,TF-Coder 就能輸出以下解決方案:
- tf.searchsorted(boundaries, prices, side='right')
TF-Coder:用聰明的方式結合函數
現在我們來看另一個問題:計算一個 0-1 張量,它可以找出輸入張量每一行中的最大元素。
- # Input tensor
- scores = [[0.7, 0.2, 0.1],
- [0.4, 0.5, 0.1],
- [0.4, 0.4, 0.2],
- [0.3, 0.4, 0.3],
- [0.0, 0.0, 1.0]]
- # Output tensor
- top_scores = [[1, 0, 0],
- [0, 1, 0],
- [1, 0, 0],
- [0, 1, 0],
- [0, 0, 1]]
注意,如果一行內相同的最大元素重復出現(如 scores 中的第三行),則標記第一次出現的最大元素,這樣 top_scores 的每一行都只有一個 1。
與上一個問題不同,這里不存在可執行該計算的 TensorFlow 函數。在文檔中搜索「max」,你可能找到 tf.reduce_max、tf.argmax 和 tf.maximum,但也不清楚到底該用哪一個?tf.reduce_max 輸出 [0.7, 0.5, 0.4, 0.4, 1.0],tf.argmax 輸出 [0, 1, 0, 1, 2],tf.maximum 不合適,因為它只能容納兩個參數。這些函數似乎都與該示例的期望輸出關聯不大。
而 TF-Coder 可以幫你解決這類棘手問題。你可以將這個問題寫成輸入 - 輸出示例的形式:
- # Input-output example
- inputs = {
- 'scores': [[0.7, 0.2, 0.1],
- [0.4, 0.5, 0.1],
- [0.4, 0.4, 0.2],
- [0.3, 0.4, 0.3],
- [0.0, 0.0, 1.0]],
- }
- output = [[1, 0, 0],
- [0, 1, 0],
- [1, 0, 0],
- [0, 1, 0],
- [0, 0, 1]]
TF-Coder 結合使用 tf.one_hot 和 tf.argmax,得到問題的解:
- tf.cast(tf.one_hot(tf.argmax(scores, axis=1), 3), tf.int32)
通過對 TensorFlow 操作組合進行詳細搜索,TF-Coder 通常能夠發現優雅的解決方案,從而簡化步驟,加速 TensorFlow 程序。
TF-Coder:用更少的 debug,寫出準確的代碼
考慮通過將每一行除以該行之和,把整數出現次數列表歸一化為概率分布。例如:
- # Input tensor
- counts = [[0, 1, 0, 0],
- [0, 1, 1, 0],
- [1, 1, 1, 1]]
- # Output tensor
- normalized = [[0.0, 1.0, 0.0, 0.0],
- [0.0, 0.5, 0.5, 0.0],
- [0.25, 0.25, 0.25, 0.25]]
即使你知道可用的函數(tf.reduce_sum followed by tf.divide),寫出正確的代碼也并非易事。第一次嘗試可能是這樣的:
- # First attempt
- normalized = tf.divide(counts, tf.reduce_sum(counts, axis=1))
但是以上代碼是正確嗎?我們需要考慮許多潛在的問題:
- 代碼中 axis 的值正確嗎?是否應改為 axis=0?
- counts 和 tf.reduce_sum(counts, axis=1) 的形狀與除法兼容嗎?需要改變形狀或執行轉置操作嗎?
- counts 和 tf.reduce_sum(counts, axis=1) 都是 tf.int32 張量。tf.int32 張量可以被除嗎?是否需要先將其轉換為 float 數據類型?
- 兩個參數的順序對嗎?是否需要調換位置?
- 輸出的類型是 tf.int32、tf.float32,還是別的什么?
- 是否存在更簡單或更好的方式?
而使用 TF-Coder,你只需要給出以下輸入 - 輸出示例:
- # Input-output example
- inputs = {
- 'counts': [[0, 1, 0, 0],
- [0, 1, 1, 0],
- [1, 1, 1, 1]],
- }
- output = [[0.0, 1.0, 0.0, 0.0],
- [0.0, 0.5, 0.5, 0.0],
- [0.25, 0.25, 0.25, 0.25]]
TF-Coder 給出解決方案:
- tf.cast(tf.divide(counts, tf.expand_dims(tf.reduce_sum(counts, axis=1), axis=1)), tf.float32)
TF-Coder 生成以上解決方案時,可以確保代碼在示例輸入上運行時能夠準確生成示例輸出。TF-Coder 的解決方案避免了不必要的步驟。你可以快速找出以上潛在問題的答案:需要采用額外的 tf.expand_dims 步驟,使張量形狀與除法兼容;tf.divide 的答案必須是 tf.float32 類型。
通過這種方式,TF-Coder 可以幫助開發者編寫簡單準確的代碼,且無需痛苦的 debug 過程。
局限性
不過,TF-Coder 也有其局限性。目前它可以在一分鐘內找到涉及 3 到 4 種運算的解決方案,但短時間內找到涉及 6 種及以上操作的解決方案,對它來說還是太過復雜。此外,TF-Coder 尚不支持復張量、字符串張量或 RaggedTensor。
TF-Coder 支持操作的完整列表,參見:https://colab.research.google.com/github/google-research/tensorflow-coder/blob/master/TF-Coder_Colab.ipynb#scrollTo=Q6uRr4x9WHRC
此外,TF-Coder 只能保證解決方案對給出的輸入 - 輸出示例有效。該工具會搜索一個與給定輸入 - 輸出示例相匹配的簡單 TensorFlow 表達式,但有時候「過于簡單」,不能按預期進行泛化。盡可能讓示例無歧義會有所幫助,這一般可以通過向輸入和輸出張量添加更多數值來實現。