MySQL慢查詢語句分析總結
我們經常會接觸到MySQL,也經常會遇到一些MySQL的性能問題。我們可以借助慢查詢日志和explain命令初步分析出SQL語句存在的性能問題
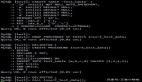
通過SHOW FULL PROCESSLIST查看問題
SHOW FULL PROCESSLIST相當于select * from information_schema.processlist可以列出正在運行的連接線程,
processlist
說明:
- id 連接id,可以使用kill+連接id的方式關閉連接(kill 9339)
- user顯示當前用戶
- host顯示連接的客戶端IP和端口
- db顯示進程連接的數據庫
- command顯示當前連接的當前執行的狀態,sleep、query、connect
- time顯示當前狀態持續的時間(秒)
- state顯示當前連接的sql語句的執行狀態,copying to tmp table、sorting result、sending data等
- info顯示sql語句,如果發現比較耗時的語句可以復制出來使用explain分析。
慢查詢日志
慢查詢日志是MySQL用于記錄響應時間超過設置閾值(long_query_time)的SQL語句,默認情況下未開啟慢查詢日志,需要手動配置。
下面我們要記住幾個常用的屬性:
- slow_query_log:是否開啟慢查詢(ON為開啟,OFF則為關閉)
- long_query_time:慢查詢閥值,表示SQL語句執行時間超過這個值就會記錄,默認為10s
- slow_query_log_file:慢查詢日志存儲的文件路徑
- log_queries_not_using_indexes: 記錄沒有使用索引查詢語句(ON為開啟,OFF為關閉)
- log_output:日志存儲方式(FILE表示將日志寫入文件,TABLE表示寫入數據庫中,默認值為FILE,如果存入數據庫中,我們可以通過select * from mysql.slow_log的方式去查詢,一般性能要求相對較高的建議存文件)
我們可以通過show variables like ‘%關鍵字%’的方式查詢我們設置的屬性值
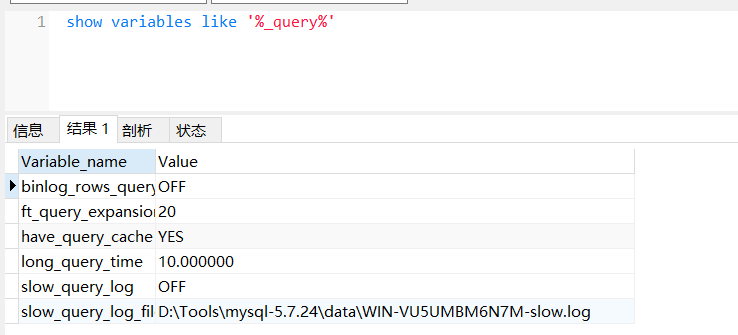
slow
我們有兩種方式設置我們的屬性,一種是set global 屬性=值的方式(重啟失效),另一種是配置文件(重啟生效)
命令方式:
- set global slow_query_log=1;
- set global long_query_time=1;
- set global slow_query_log_file='mysql-slow.log'
配置文件方式:
- slow_query_log = 'ON'
- slow_query_log_file = D:/Tools/mysql-8.0.16/slow.log
- long_query_time = 1
- log-queries-not-using-indexes
pt-qurey-digest分析慢查詢語句
percona-toolkit包含了很多實用強大的mysql工具包,pt-qurey-digest只是其中一個用于分析慢查詢日志是工具。需要去官網下載,使用方法也很簡單:
- ./pt-query-digest slow2.log >> slow2.txt
即可得出一個分析結果:
- # Query 9: 0.00 QPS, 0.00x concurrency, ID 0xF914D8CC2938CE6CAA13F8E57DF04B2F at byte 499246
- # This item is included in the report because it matches --limit.# Scores: V/M = 0.22
- # Time range: 2019-07-08T03:56:12 to 2019-07-12T00:46:28
- # Attribute pct total min max avg 95% stddev median
- # ============ === ======= ======= ======= ======= ======= ======= =======# Count 8 69
- # Exec time 1 147s 1s 3s 2s 3s 685ms 2s
- # Lock time 0 140ms 2ms 22ms 2ms 3ms 2ms 2ms
- # Rows sent 0 0 0 0 0 0 0 0
- # Rows examine 0 23.96M 225.33k 482.77k 355.65k 462.39k 81.66k 345.04k
- # Query size 2 17.72k 263 263 263 263 0 263
- # String:# Databases xxxx# Hosts xx.xxx.xxx.xxx# Users root# Query_time distribution# 1us
- # 10us
- # 100us
- # 1ms
- # 10ms
- # 100ms
- # 1s ################################################################
- # 10s+
- # Tables# SHOW TABLE STATUS FROM `xxxx` LIKE 'xxxxx_track_exec_channel'\G
- # SHOW CREATE TABLE `xxxx`.`xxxxxxxx_exec_channel`\G
- # SHOW TABLE STATUS FROM `xxx` LIKE 'xxxxx_TRACK_ASSIGN'\G
- # SHOW CREATE TABLE `xxxx`.`xxxxx_EFFECTIVE_TRACK_ASSIGN`\G
- # SHOW TABLE STATUS FROM `xxx` LIKE 'xxxx_task_exec'\G
- # SHOW CREATE TABLE `xxxx`.`xxxxx_task_exec`\G
- UPDATExxxxxx_effective_track_exec_channel a SET EXEC_CHANNEL_CODE=(SELECT GROUP_CONCAT(DISTINCT(channel_id)) FROM xxxxxx_EFFECTIVE_TRACK_ASSIGN WHERE status in (1,2,4) AND id IN (SELECT assgin_id FROM xxxxxx_task_exec WHERE task_id=a.task_id))\G
explain分析SQL語句
上面幾點大概的介紹到了幾種獲取慢查詢SQL語句的方式,現在,我們就需要借助explain來分析查找SQL語句慢的原因。explain使用也很簡單,直接在SELECT|UPDATE等語句前加上EXPLAIN即可

explain
id
表的執行順序,復制的sql語句往往會分為很多步,序號越大越先執行,id相同執行順序從上往下
select_type
數據讀取操作的操作類型:
- SIMPLE(簡單SELECT,不使用UNION或子查詢等)
- PRIMARY(子查詢中最外層查詢,查詢中若包含任何復雜的子部分,最外層的select被標記為PRIMARY)
- UNION(UNION中的第二個或后面的SELECT語句)
- DEPENDENT UNION(UNION中的第二個或后面的SELECT語句,取決于外面的查詢)
- UNION RESULT(UNION的結果,union語句中第二個select開始后面所有select)
- SUBQUERY(子查詢中的第一個SELECT,結果不依賴于外部查詢)
- DEPENDENT SUBQUERY(子查詢中的第一個SELECT,依賴于外部查詢)
- DERIVED(派生表的SELECT, FROM子句的子查詢)
- UNCACHEABLE SUBQUERY(一個子查詢的結果不能被緩存,必須重新評估外鏈接的第一行)
table
數據來源于那張表,關聯等復雜查詢時會用臨時虛擬表
type
檢索數據的方式
- system:表只有一行記錄
- const:通過索引查找并且一次性找到
- eq_ref:唯一性索引掃描
- ref:非唯一行索引掃描
- range:按范圍查找
- index:遍歷索引樹
- all:全表掃描
possible_keys
顯示可能使用的索引
Key
實際使用的索引
key_len
索引的長度,一般來說,長度越短越好
ref
列與索引的比較,表示上述表的連接匹配條件,即哪些列或常量被用于查找索引列上的值
rows
估算查找的結果記錄條數
Extra
SQL查詢的詳細信息
- Using where:表示使用where條件過濾
- Using temporary:使用了臨時表暫存結果
- Using filesort:說明mysql對數據使用一個外部索引排序。未按照表內的索引順序進行讀取。
- Using index:表示select語句中使用了覆蓋索引,直接從索引中取值
- Using join buffer:使用了連接緩存
- Using index condition:表示查詢的列有非索引的列