增長產品中,量化數據分析的幾個方法
增長為什么要做量化
做增長產品的數據分析,和其他的數據分析,個人認為最大的特色在于量化,為什么要做量化?因為,做增長,是個強數據驅動的方法,要把有限的資源發揮出最大的價值,所以必須準確計算出每個Driver的ROI,才能更有效分配資源,做到效率最大化,把好鋼用在刀刃上。
舉例幾個場景:
-
每次拉新,不但要量化拉新人數,還要量化后續的持續貢獻價值
-
每次拉活,同樣,老板關心后續的持續價值
-
每次活動,老板不但會問,這次活動有多少人參與,還會問,這次活動貢獻了多少增量貢獻,如果沒有這次活動,DAU會是多少?
-
上線新模塊,和活動類似,老板會關心這個模塊為大盤帶來了多少增量貢獻?
可以看出,我把增長產品的量化規為2大類,外部拉量(拉新、拉活)和促進活躍:
-
外部拉量:拉新方面,業界有比較成熟的LTV模型,難點在于對LTV模型的預估,拉活方面,一般我們只計算當次(當然不嚴謹,拉活的后續持續貢獻非常復雜)
-
促進活躍:例如做了運營活動,上線新功能、新模塊,本質上都是在促進活躍,這里問題的關鍵就在于,到底促進了多少活躍,后續滾動下來有多大收益?往往,促進活躍投入的資源是非常大的,準確量化增量貢獻不易,此部分也是本文討論的重點。
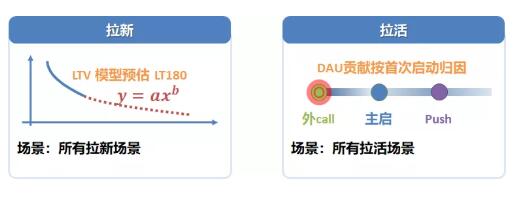
拉新拉活的量化
這部分,只簡單談一下,因為我的業務范圍拉新拉活量化比較少,沒有經驗,借鑒下比較基礎的量化方法
-
拉新,采用y = ax^b分渠道量化預估,雖然還有很多高大上的算法,但是這個公式實現成本最低的,方法還不錯
-
拉活,對于DAU的貢獻,只計算當日首次啟動,對于使用時長的貢獻等等,按每個session計算
促活貢獻的簡單量化方法
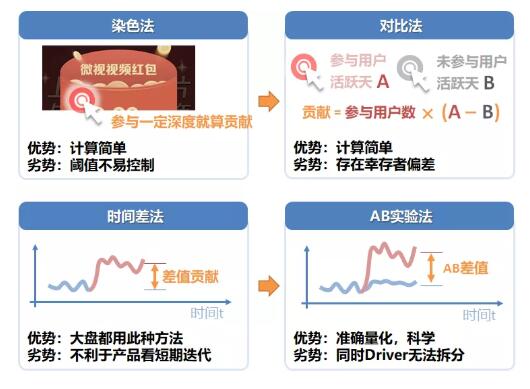
促活方面,有幾個簡單的量化方式,雖然不好,但是較為簡單,可以參考,后續將會討論2種比較復雜的量化方式
-
染色法:對于參與或深度參與的,設定一個閾值,認為是帶來的
-
對比法:對比滲透與未滲透的用戶,對比一個周期內活躍天,或周期內總使用時長,作為貢獻,但是此方法有嚴重的幸存者偏差,需要對滲透有著較為嚴格的定義,例如有一定深度的閾值
-
時間對比法:對小部分用戶做強刺激的時候,常采用對比法,時間上對比,例如對某個渠道做了某些特殊的承接,可以對比渠道不同時間的留存。此方法看似不嚴謹,但是其實想一想,這是我們應用最多的方法,資本市場,每個Q的財報,常用的同比、環比,本質上就是這種方法;一般公司對部門定的KPI或OKR,都是這種方式,公司不會給一個對照組,用絕對值量化貢獻。
-
AB實驗法:我認為AB實驗的對比,是比較好的方法。這里,要注意2點,第一,有的時候AB實驗會層層疊加,簡單的AB實驗無法量化出短期貢獻和長期貢獻,第二,有一些時候,因為網絡效應的存在或者開發排期的原因,不是所有的產品都有AB實驗能力。
多層域AB實驗法——準確量化短期和長期貢獻
以我負責的模塊為例,老板們會關心
-
長期以來貢獻了多少DAU?
-
每次產品迭代,提高了多少?
-
嚴謹一點,我們采用了AB實驗的方式核算,最終可能會發現一個問題:短期迭代貢獻,不等于長期貢獻,為什么呢?(本文重點講述AB實驗,對于1+1≠2話題,詳細請看本人的文章《數據分析中,為什么1+1不等于2?》)
-
有的時候,迭代A和迭代B,有著相互放大的作用,這個時候就會 1+1 > 2
-
還有的時候,迭代A和迭代B,本質上是在做相同的事情,這個時候就會 1+1 < 2
有些場景,我們的業務需要和去年或上個季度的自身對比,同時業務還不斷在多個方面運用AB Test迭代
這個時候,我們準確量化一個長期產品模塊的貢獻,就需要一個【貫穿】所有活動的對照組,在AB實驗系統中通俗稱作貫穿層
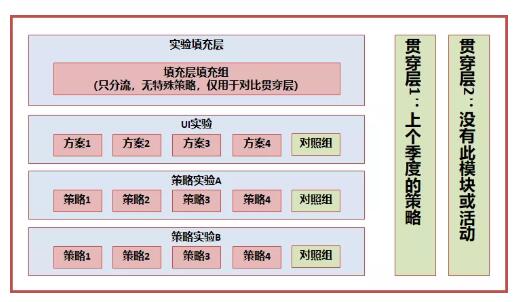
(說明:實驗中,各層的流量是正交的,簡單理解,例如,A層的分流采用用戶ID的倒數第1位,B層的分流采用用戶ID的倒數第2位,在用戶ID隨機的情況下,倒數第1位和倒數第2位是沒有關系的,也稱作相互獨立,我們稱作正交。當然,AB Test實驗系統真實的分流邏輯,是采用了復雜的hash函數、正交表,能夠保證正交性。)
這樣分層后,我們可以按照如下的方式量化貢獻:
-
計算長期的整體貢獻:實驗填充層-填充層填充組 VS 貫穿層2-貫穿層填充
-
每個小迭代對整個系統的貢獻:實驗層中的實驗組 VS 對照組
-
周期內,系統全部迭代與上個周期的比較:實驗填充層 VS 貫穿層1
類似與上面這種層次設計,在推薦系統中較為常見,在某一些產品或系統中,貫穿層不能夠完全沒有策略,那么采用去年或上個季度的策略,代表著基準值,從而量化新一個周期的增量貢獻
詳細可參看《淺談AB Test實驗設計和數據分析(二)——層域模型的設計》 ,https://mp.weixin.qq.com/s/SSRlELhzy3nOkjeYI1nmXg
沒有AB實驗能力,如何盡量評估貢獻?
AB實驗固然好,但是有的時候,因為各種各樣的原因,特殊時期,沒有AB實驗,產品上線了。上線后,數據分析師依然有職責量化出貢獻,以我負責業務為例,2020的微視集令牌活動,如何量化貢獻?
我們思考過程如下:
-
首先,采用對比法,對比參與活動與未參與活動的活躍天差別。(此步,考慮到了有幸存者偏差)
-
接下來,為了解決幸存者偏差,分別對比了下兩組用戶在之前的活躍程度,做了下差分比較。(此步,有考慮同期的其他活動,會因為用戶交集太大,無法分離)
-
最后為了區分同期的其他用戶,將是否參與其他用戶也做了分組,同時做對比差分。

做了上面的處理,我還存在疑問:
-
幸存者偏差仍存在,到底還存在多少?
-
排除幸存者偏差、紅包的干擾,依賴主觀判斷,還有沒有其他因素的干擾?如何證明?
-
評估方法個性化,可否抽象為通用方法?
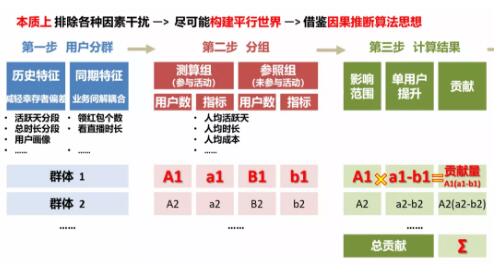
思考:差分計算和按紅包分組,本質上排除各種因素干擾,盡可能構建平行世界,說白了,我們在尋找特征相同的用戶群,因此,在方法層面也許可以統一
按照上面的思路,我們引入了協變量的概念,這個概念借鑒了因果推斷算法
方法如下:
-
通過多種特征,尋找特征相同的用戶群(尋找協變量,協變量非常關鍵,后文會提到幾個原則)
-
每個群內,按照是否參與活動分為2組(構建平行世界),對比參與與未參與的差異,計算每個群組的貢獻
-
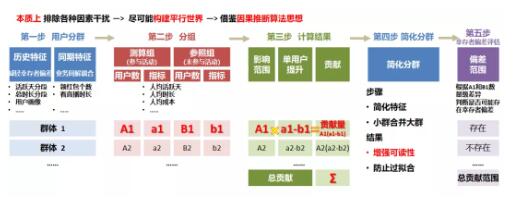
為了增強可解釋性和可讀性,簡化分組,例如:合并小的分組(如合并同特征分段),較少部分特征,原則是簡化分組不影響整體結論,同時簡化分組也有利于解決過擬合問題
-
對于部分分組,仍存在較強的幸存者偏差,做特殊標注(這樣至少可以量化得到范圍)
-
將各個分組的貢獻相加,得到量化貢獻范圍(說明,雖結果不準確,但有一定的范圍,也可以供部門決策,數據分析的很重要作用就是輔助決策)
核心流程如下:
說明下尋找協變量的原則,這個非常關鍵:
-
選擇與評估時間盡可能近的特征,目的是分群盡可能公平,為了構建平行世界,例如:活動前7天的活躍天、使用時長、畫像等
-
選擇需要解耦合的業務特征,例如:同期是否領取紅包、是否參與其他活動等
-
不能選擇與評估指標有因果性的特征,例如:不能按活動期間的活躍天分群,同時要注意選擇解耦合業務的特征,盡可能降低與評價指標的因果性,盡可能用輕度參與特征,例如:是否參與過(1次就算),不能選擇“參與的天數”,因為“參與的天數”本身和我們評價的指標活躍天存在因果性。
總的來說,我還是推崇用AB實驗衡量貢獻,特殊情況下,上面的方法我認為雖然不嚴謹,這種方法有2點優勢,并且我們也在其他業務中推廣
-
統一經驗方法,形成通用方法論,解決平行世界構建和業務間解耦合問題
-
有一定理論支撐(借鑒因果推斷思想),可評估誤差范圍