













Google開源Java字符編碼檢測工具介紹
作者:程序猿解碼
產品經理要求上傳文件到服務器,但是文件沒有模板,文件的編碼格式不定,因此不能通過指定的編碼格式解析文件,否則會出現亂碼。
背景
產品經理要求上傳文件到服務器,但是文件沒有模板,文件的編碼格式不定,因此不能通過指定的編碼格式解析文件,否則會出現亂碼。
文件編碼識別
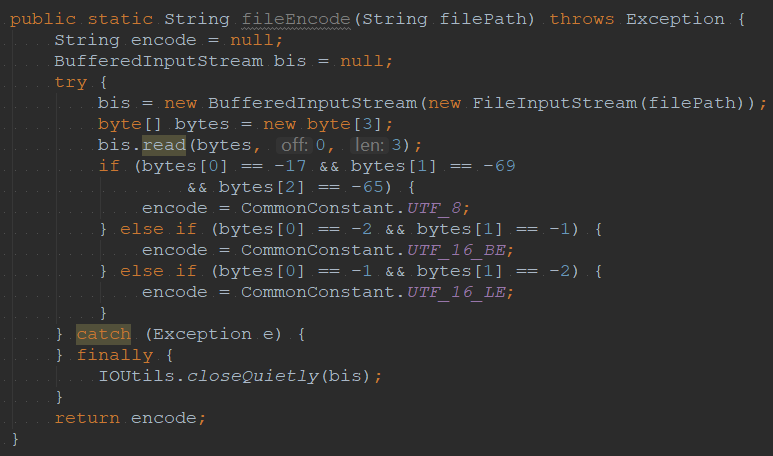
(1)UTF-8 BOM編碼的文件,前3個字節轉換成10進制數后分別是:-17、-69、-65。
(2)UTF-16BE BOM編碼的文件,前2個字節轉換成10進制數后分別是:-2、-1。
(3)UTF-16LE BOM編碼的文件,前2個字節轉換成10進制數后分別是:-1、-2。
因此,這三種編碼格式的文件檢測起來比較簡單,只需要拿到文件的前三個字節,然后根據上面的規則就可以確定文件是什么編碼。問題是這種檢測方式只能區分UTF-8 BOM、UTF-16BE BOM和UTF-16LE BOM編碼的文件,不能區分UTF-8和GBK編碼的文件。
Google字符編碼檢測工具
需要引入Maven依賴,Maven坐標如下:
- <dependency>
- <groupId>
- com.googlecode.juniversalchardet </groupId>
- <artifactId>juniversalchardet</artifactId>
- <version>1.0.3</version>
- </dependency>
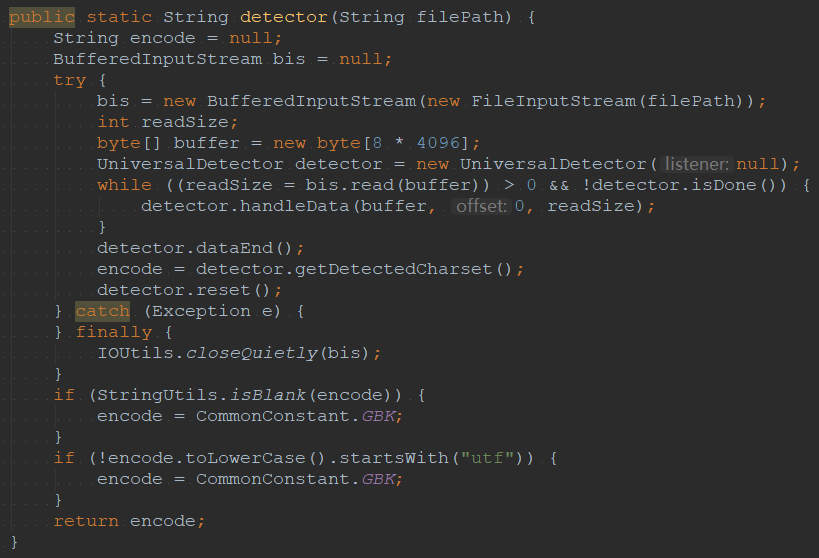
Google字符編碼檢測工具Java代碼示例,目前來看檢查UTF-8和GBK編碼沒有問題,但是其它編碼存在問題,由于上傳的文件只有中文和英文,因此稍微做了點兼容性處理,當編碼獲取錯誤時,默認取GBK編碼。編碼檢測工具在生產環境運行了一段時間,目前來看沒發現什么問題。
總結
由于上傳的文件只有中文和英文,在生產環境運行了一段時間,目前來看是滿足要求的。比如Google的字符編碼檢測工具會返回WINDOWS-1252這樣的編碼格式,這種默認用GBK編碼就可以。還有一些檢測不出來的編碼格式,返回null,這種也用默認的GBK就行。
責任編輯:張燕妮
來源:
今日頭條















