一步到位,服務器監控就是這么簡單
對于運維的日常工作來說,服務器監控是必須且最基礎的一項內容。在企業基礎設施運維過程中,管理員必須能夠掌握所有服務器的運行狀況,以便及時發現問題,盡可能減少故障的發生。通常我們會借助一些監控的軟件來獲取每個服務器的基礎指標并進行集中的查看、分析、監控。
市面上開源、收費的服務器監控系統非常多,例如老牌的zabbix、nagios、NewRelic、CollectD等,近期開始流行的Telegraf、Prometheus。各類系統都有其出彩的點,例如Zabbix強大的生態、NewRelic的服務、Prometheus的云原生友好等。服務器監控相對中間件、業務監控更加基礎,關注點主要集中在監控的易用性、穩定性、實時性、報警豐富度、報表使用便捷度等。
本期為大家介紹如何使用阿里云SLS來快速構建一套完整的服務器/主機基礎指標實時監控方案。
SLS時序存儲簡介
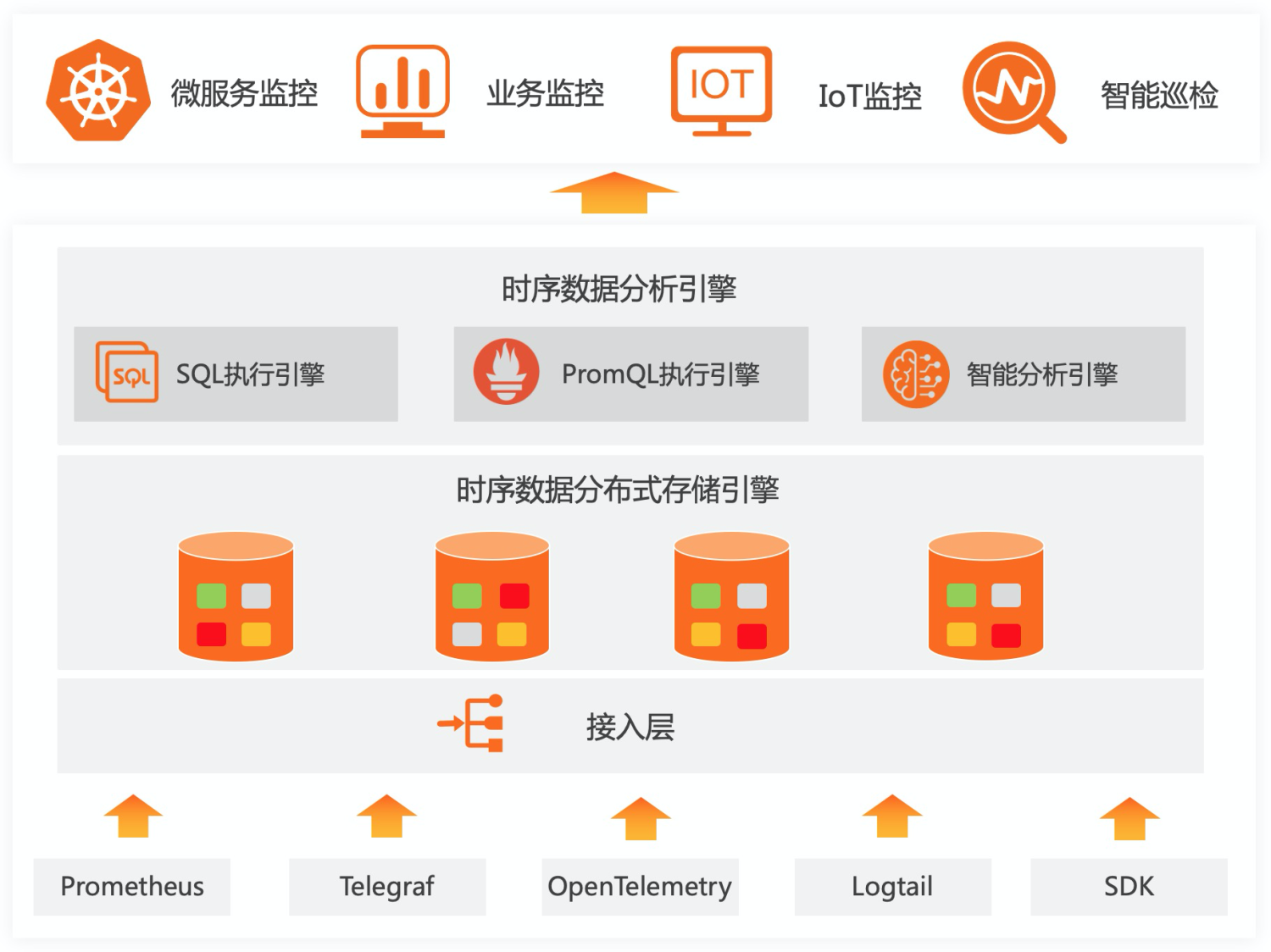
SLS的日志存儲引擎在2016年對外發布,目前承接阿里內部以及眾多企業的日志數據存儲,每天有數十PB的日志類數據寫入。其中有很大一部分屬于時序類數據或者用來計算時序指標,為了讓用戶能夠一站式完成整個DevOps生命周期的數據接入、清洗、加工、提取、存儲、可視化、監控、問題分析等過程,我們專門推出了時序存儲的功能,與日志存儲一道為大家解決各類機器數據的存儲問題。
SLS時序存儲從設計之初就是為了解決阿里內部與眾多頭部企業客戶的時序存儲需求,并借助于阿里內部多年的技術積累,使之可以適應絕大部分企業級時序監控/分析訴求。SLS時序存儲的特點主要有:
- 豐富上下游:數據接入上SLS支持眾多采集方式,包括各類開源Agent以及阿里云內部的監控數據通道;同時存儲的時序數據支持對接各類的流計算、離線計算引擎,數據完全開放;
- 高性能:SLS存儲計算分離架構充分發揮集群能力,尤其在大量數據下端對端的速度提升顯著;
- 免運維:SLS的時序存儲完全是服務化,無需用戶自己去運維實例,而且所有數據都是3副本高可靠存儲,不用擔心數據的可靠性問題;
- 開源友好:SLS的時序存儲原生支持Prometheus的寫入和查詢,并支持SQL92的分析方法,可以原生對接Grafana等可視化方案;
- 智能:SLS提供了各種AIOps算法,例如多周期估算、預測、異常檢測、時序分類等各類時序算法,可以基于這些算法快速構建適應于公司業務的智能報警、診斷平臺。
服務器監控方案概述
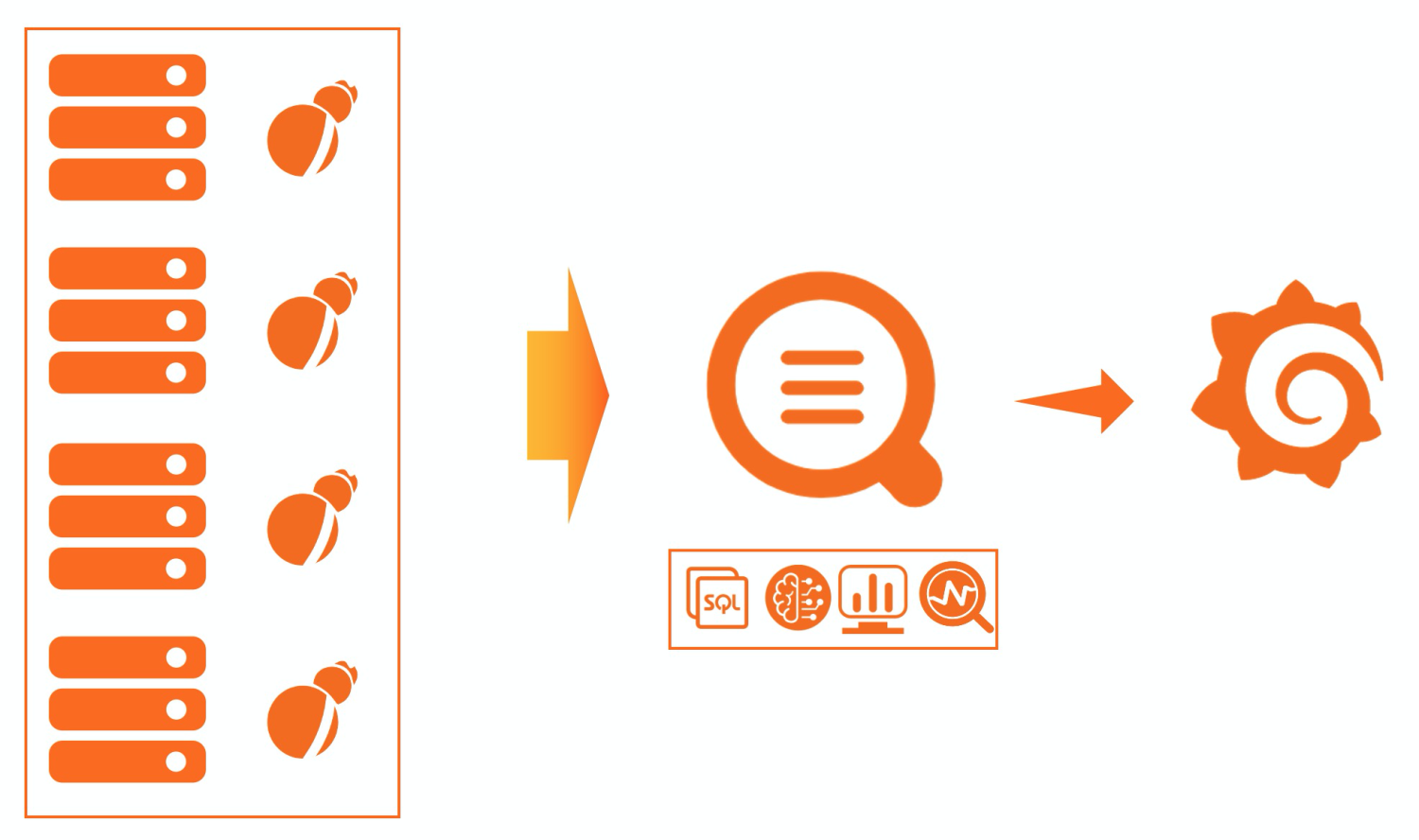
SLS的主機監控方案非常簡單,只需要安裝一個Logtail就可以采集各個主機的基礎指標,服務端都是云化,無需運維,默認SLS提供了可視化的儀表盤,也可以通過Grafana來進行更加專業的可視化。
目前Logtail采集了主機常用的基礎指標,包括CPU、內存、網絡、磁盤等,其中對較為關鍵的指標都做了可視化,便于直接查看。
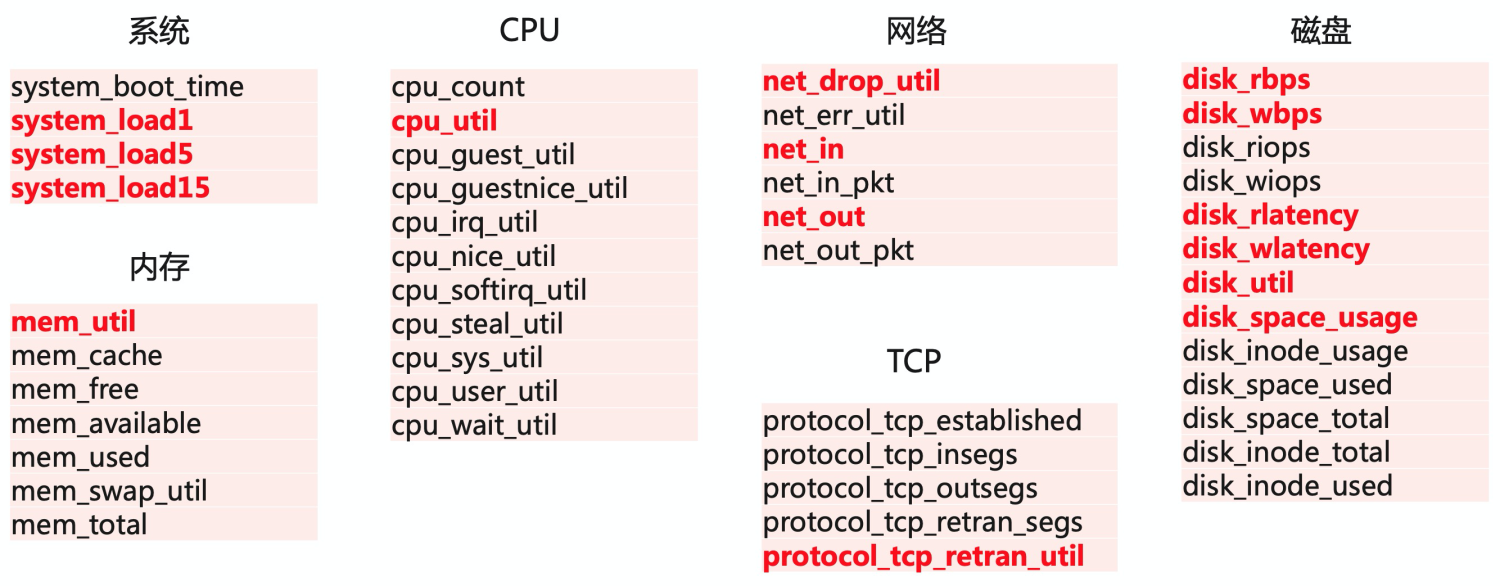
數據接入
數據接入的流程非常簡單,只需要在SLS控制臺上操作即可完成(對于非阿里云的服務器,需要在服務器上額外執行2條命令),具體接入的方法可參見:采集主機監控數據。
接入過程中最核心的就是給每臺主機的Logtail增加一個采集配置,Logtail的采集配置可以完全云化管理,無需登錄每臺服務器手動配置。
- {
- "inputs": [
- { "detail": {
- "IntervalMs": 30000
- }, "type": "metric_system_v2"
- } ]}
可視化
在運維可視化領域Grafana是當前大家接受度最高的可視化方案,SLS為主機監控專門增加了2個Dashboard模板,包括一張集群級別的監控大盤和單機的詳細指標大盤。這些大盤可以一鍵導入到Grafana中。
Grafana的配置流程如下:
- 在Grafana中把SLS的時序庫作為Prometheus的數據源,設置方式可參考:Grafana可視化配置。
- 導入Grafana模板市場中的SLS模板:主機監控集群指標、主機監控單機指標。
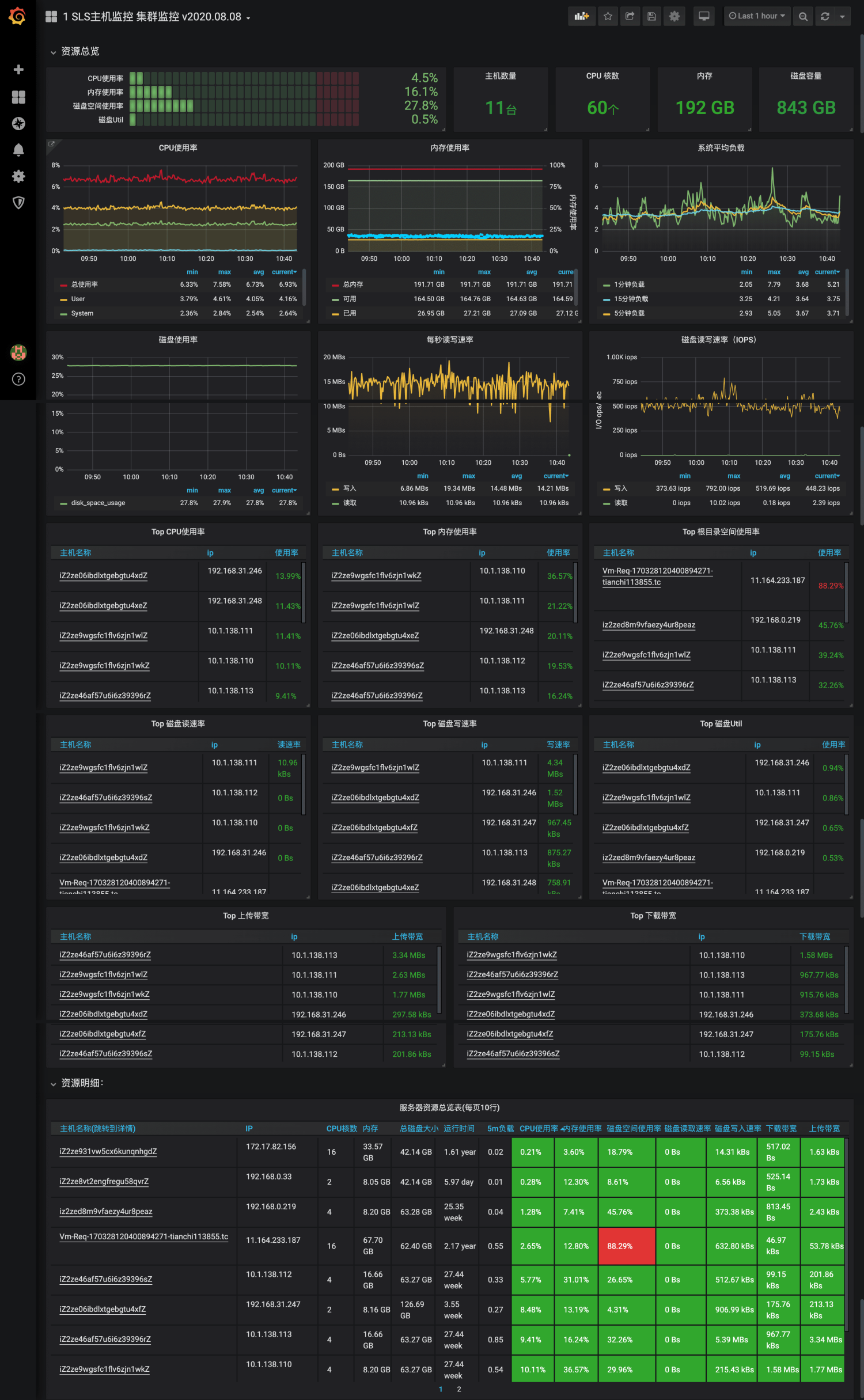
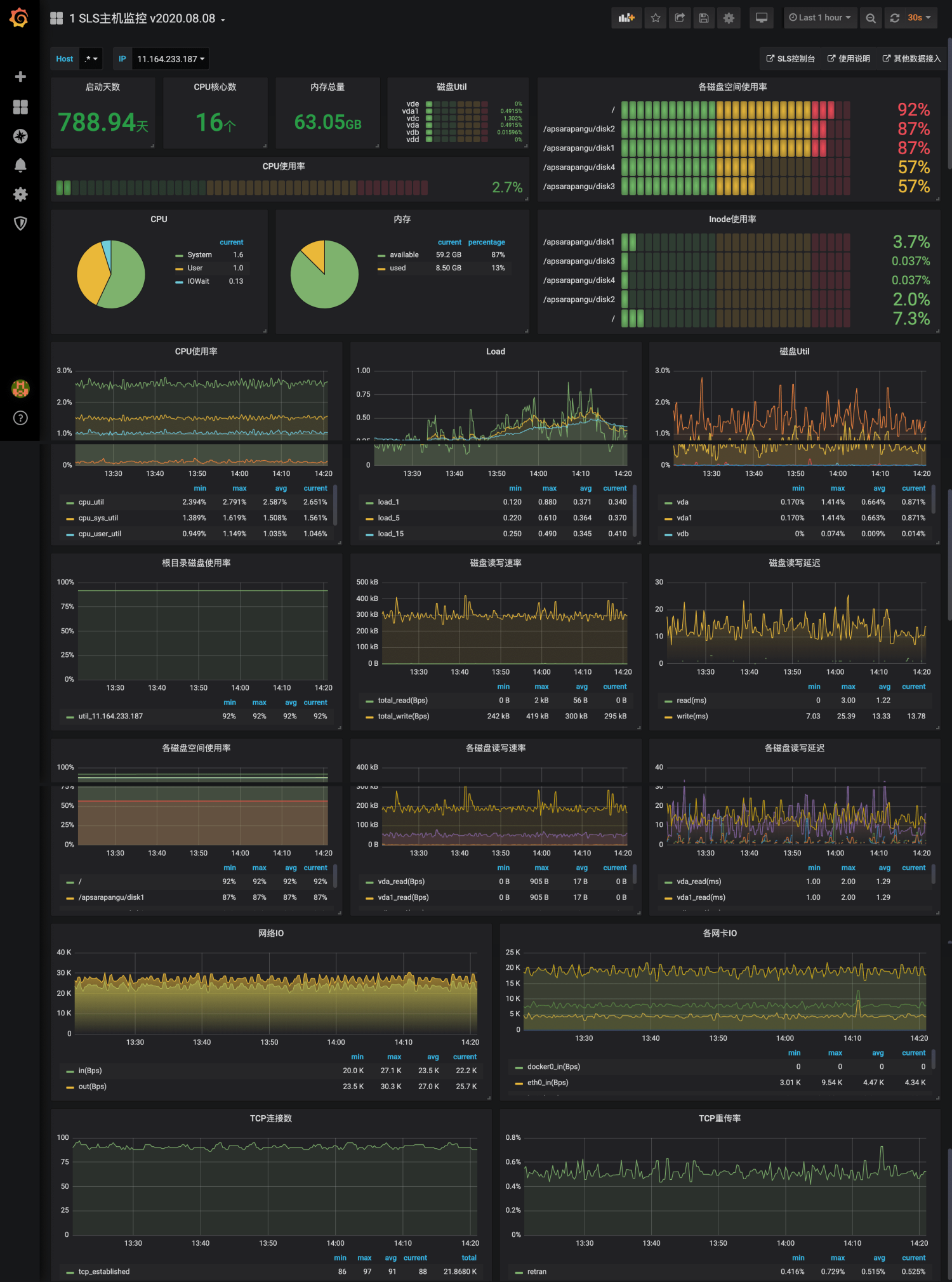
監控數據分析與告警配置
作為一個合格的運維人員,僅僅配置完炫酷的監控儀表盤還不夠,還需要對集群設置好足夠的告警項并能在需要排查問題的時候利用監控數據分析的語法快速定位問題。這些本質上都是對集群的指標進行一些計算和統計。
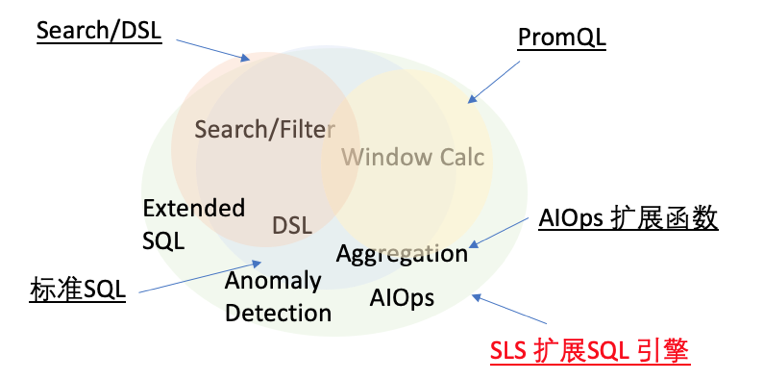
SLS時序數據支持SQL、PromQL以及SQL+PromQL等多種查詢方式,PromQL查詢語言相對更加簡潔,SQL能夠實現的語義更加強大。而主機的監控數據相對比較簡單,建議使用PromQL或SQL+PromQL的方式。
下面介紹幾個在告警、分析中經常會用到的幾個統計方式:
- 計算所有機器的某個指標平均值,例如平均CPU
- 查找某個指標最高的N臺機器,比如查找內存占用最高的5臺機器
- 查找某個指標超過X的機器,比如找到1分鐘網絡流量超過10M的機器
- 計算某臺機器的某個指標相對某個時間點的變化,比如計算某臺機器磁盤使用率相比1天前的變化
這些用PromQL實現起來非常容易,可以在Grafana的Explore頁面直接調試:
- 平均CPU: avg(cpu_util)
- 查找內存占用最高的5臺機器:topk(5, mem_util)
- 找出1分鐘網絡流量超過10M的機器:(sum_over_time(net_in[1m]) + sum_over_time(net_out[1m])) > (10*1024*1024)
- 計算某臺機器磁盤使用率相比1天前的變化:disk_util{hostname="iZ2ze06ibdlxtgebgtu4xdZ"} - disk_util{hostname="iZ2ze06ibdlxtgebgtu4xdZ"} offset 1d
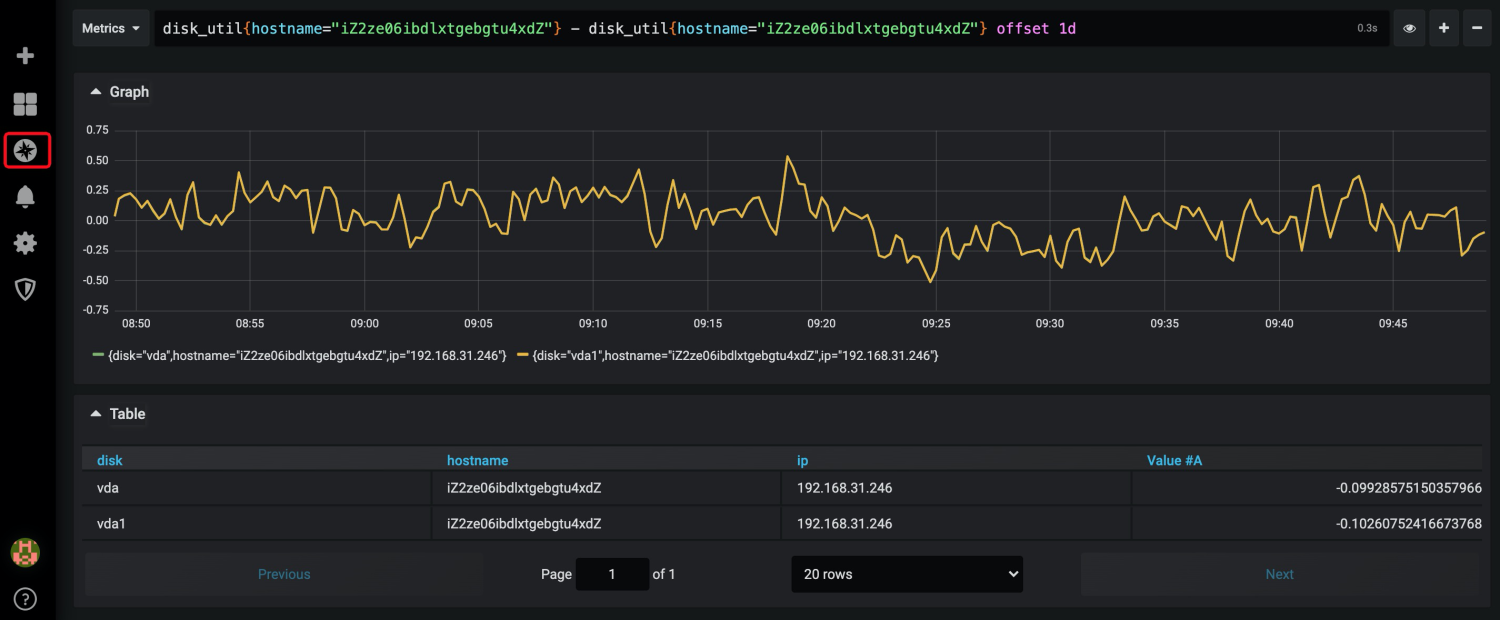
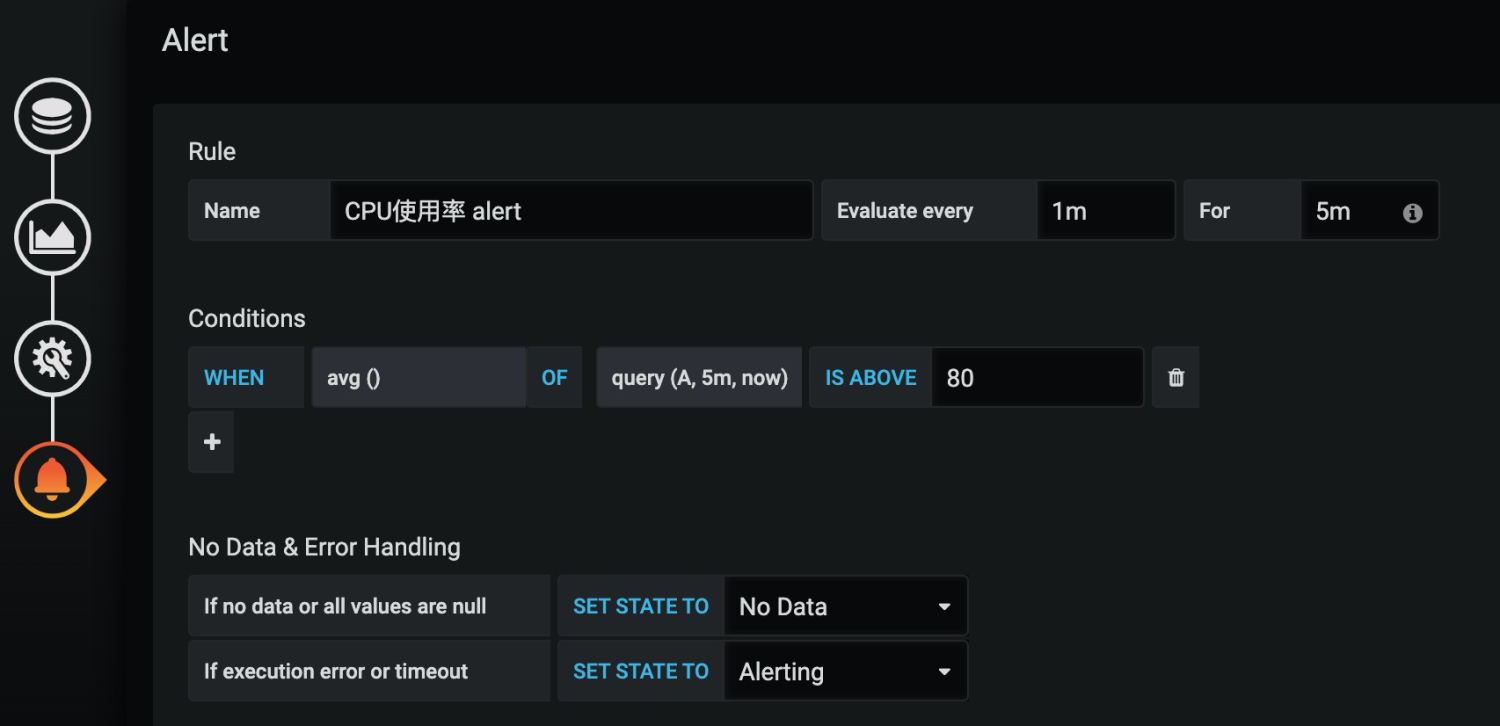
而告警也可以直接在Grafana上配置,可以在集群監控的Dashboard上直接配置告警,例如下面是配置CPU集群平均CPU超限的告警,告警規則是:每分鐘計算最近5分鐘內的集群CPU平均利用率,如果連續5分鐘超過80%則觸發告警。
總結
服務的基礎指標監控是我們監控運維領域最基礎的工作之一,構造公司IT的全方位監控還有很多工作要做,例如中間件監控、云產品監控、應用監控、業務監控等,而這些利用SLS的日志和時序存儲功能都可以很容易的實現,其他相關的實現我們會在后續文章中給大家呈現。