MySQL GTID的混合問題修復和思考
這幾天做一個跨機房實時遷移的操作,碰到一個有些奇怪的問題,記錄一下。
整體服務是在兩個機房對等部署,然后通過級聯復制的方式串起來。
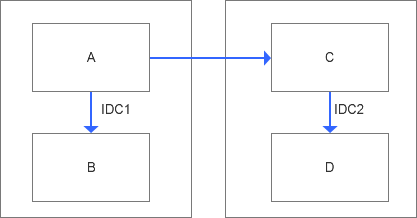
實際切換前,節點B因為是從庫,是很容易摘除的,所以整體的部署架構僅剩下A,C,D
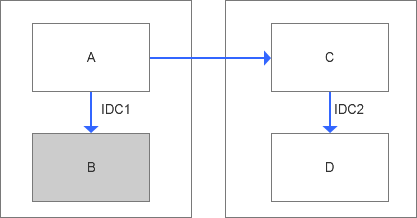
同時在切換前,為了保證整個業務訪問域名的可用性,會臨時開啟雙主復制,這個階段能夠最大程度保證數據的完整性。當然這里會有兩種模式,一種是最大保護模式,最大保護模式意味著數據只能從一個入口寫入,如果雙寫很可能會數據沖突,第二種是最大可用模式,也就意味著整個過程數據在兩邊始終可以寫入。這個模式的選用和具體的業務特點有關(讀多寫少,讀多寫多等)。
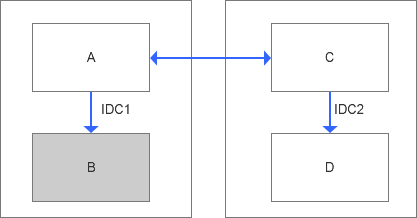
所以A和C之間的雙主配置就顯得尤其重要,也是整個平滑切換數據完整性的基礎。
目前A,C,D節點的GTID基本信息如下:
A: show master status
Executed_Gtid_Set: A:1-222717169,B:1-697
C:show slave status
Executed_Gtid_Set: A:1-222716771,B:1-700
D:show slave status
Executed_Gtid_Set: A:1-222716771,B:1-700
這個數據表達的含義比較深刻,那就是在數據鏈中,存在已被摘除的節點B的GTID信息,而從C,D的GTID相關信息可以看到,B中是丟失了一個數據事務的(當然這個過程不是真正的數據變化,和操作不規范有關)
所以在這種情況下如果要配置雙主,需要解決的就是B相關GTID的差異,一種是直接抹去B的痕跡,這個過程需要在C,D上面可操作,但是實際復制雙主的時候又會出問題。
如果把GTID當做一種數據血緣的角度會發現,整個GTID真是一個很有靈性的設計。假設紅色是A的數據血緣,綠色是B的數據血緣。
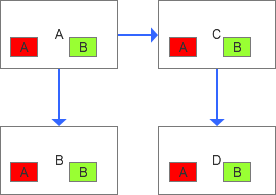
舍棄了B之后,A,C開啟了雙主,整個數據血緣就是如下的狀態了:
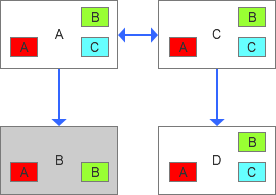
所以整個復制拓撲中的任何數據變化都能夠有理有據的追溯,這是GTID設計很有價值的一件事情。
關于修復方式,也比較清晰,那就是把C和D的數據血緣B的部分做下“回退”,如下:
A: show master status
Executed_Gtid_Set: A:1-222717169,B:1-697
C:show slave status
Executed_Gtid_Set: A:1-222716771,B:1-697
D:show slave status
Executed_Gtid_Set: A:1-222716771,B:1-697
按照這種模式來一次修改C和D,整個雙向復制就能夠很快構建起來了。
回置GTID的原理可以參考如下的圖,通過gtid_purged可以間接實現裁剪。
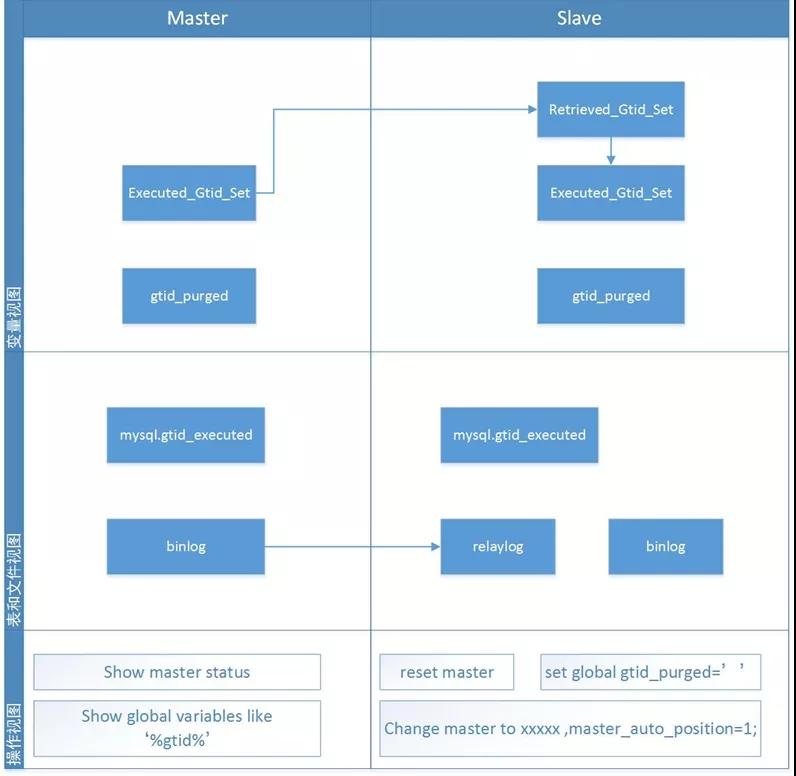
C端修復的步驟如下:
1)stop slave;
2)show slave status\G
3)reset master;
切記是在Slave端執行,這個階段的目的就是要重新配置GTID的校準值。這個時候mysql.gtid_executed應該就是空的了。
4)重置GTID_purged值
- SET @@GLOBAL.GTID_PURGED='A:1-222716771,B:1-697';
5)刪除從庫的復制配置
- reset slave all;
6)配置復制關系
CHANGE MASTER TO MASTER_USER='dba_repl', MASTER_PASSWORD='xxxx' , MASTER_HOST='xxxxx',MASTER_PORT=xxxx,MASTER_AUTO_POSITION = 1;
7)重啟Slave節點,查看狀態
- start slave;
- show slave status\G
修復好之后,這部分打算是寫一個巡檢GTID和修復的腳本邏輯,能夠把這部分的管理做得更細致一些。
本文轉載自微信公眾號「楊建榮的學習筆記」,可以通過以下二維碼關注。轉載本文請聯系楊建榮的學習筆記公眾號。