













程序員修神之路--緩存架構不夠好,系統容易癱瘓
- 緩存能大幅度提高系統性能,也能大幅度提高系統癱瘓幾率
- 怎么樣防止緩存系統被穿透?
- 緩存的雪崩是不是可以完全避免?
前幾篇文章我們介紹了緩存的優勢以及數據一致性的問題,在一個面臨高并發系統中,緩存幾乎成了每個架構師應對高流量的首沖解決方案,但是,一個好的緩存系統,除了和數據庫一致性問題之外,還存在著其他問題,給整體的系統設計引入了額外的復雜性。而這些復雜性問題的解決方案也直接了影響系統的穩定性,最常見的比如緩存的命中率問題,在一個高并發系統中,核心功能的緩存命中率一般要保持在90%以上甚至更高,如果低于這個命中率,整個系統可能就面臨著隨時被峰值流量擊垮的可能,這個時候我們就需要優化緩存的使用方式了。
如果按照傳統的緩存和DB的流程,一個請求到來的時候,首先會查詢緩存中是否存在,如果緩存中不存在則去查詢對應的數據庫。假如系統每秒的請求量為10000,而緩存的命中率為60%,則每秒穿透到數據庫的請求數為4000,對于關系型數據庫mysql來說,每秒4000的請求量對于分了一主三從的Mysql數據庫架構來說也已經足夠大了,再加上主從的同步延遲等諸多因素,這個時候你的mysql已經行走在down機邊緣了。
“緩存的最終目的,是在保證請求低延遲的情況下,盡最大努力提高系統的吞吐量
那緩存系統可能會影響系統崩潰的原因有那些呢?
緩存穿透
“緩存穿透是指:當一個請求到來的時候,在緩存中沒有查找到對應的數據(緩存未命中),業務系統不得不從數據庫(這里其實可以籠統的成為后端系統)中加載數據
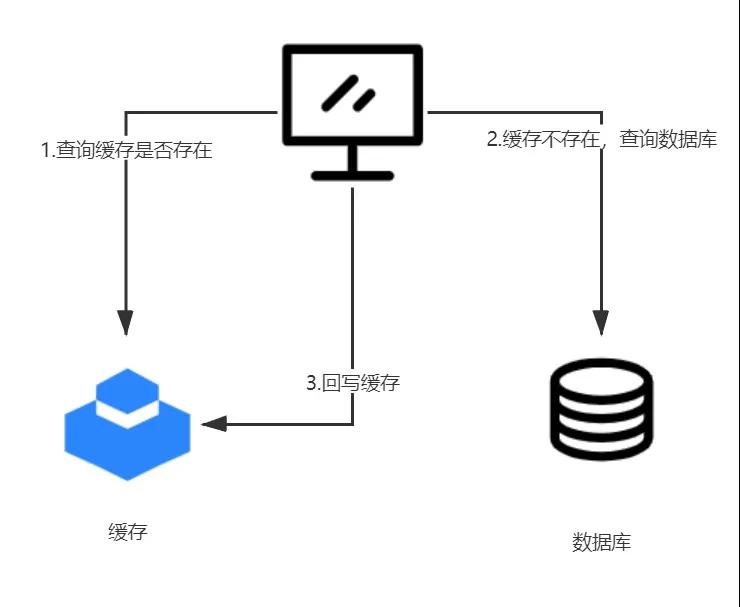
緩存穿透
發生緩存穿透的原因根據場景分為兩種:
請求的數據在緩存和數據中都不存在
當數據在緩存和數據庫都不存在的時候,如果按照一般的緩存設計,每次請求都會到數據庫查詢一次,然后返回不存在,這種場景下,緩存系統幾乎沒有起任何作用。在正常的業務系統中,發生這種情況的概率比較小,就算偶爾發生,也不會對數據庫造成根本上的壓力。
最可怕的是出現一些異常情況,比如系統中有死循環的查詢或者被黑客攻擊的時候,尤其是后者,他會故意偽造大量的請求來讀取不存在的數據而造成數據庫的down機,最典型的場景為:如果系統的用戶id是連續遞增的int型,黑客很容易偽造用戶id來模擬大量的請求。
請求的數據在緩存中不存在,在數據庫中存在
這種場景一般屬于業務的正常需求,因為緩存系統的容量一般是有限制的,比如我們最常用的Redis做為緩存,就受到服務器內存大小的限制,所以所有的業務數據不可能都放入緩存系統中,根據互聯網數據的二八規則,我們可以優先把訪問最頻繁的熱點數據放入緩存系統,這樣就能利用緩存的優勢來抗住主要的流量來源,而剩余的非熱點數據,就算是有穿透數據庫的可能性,也不會對數據庫造成致命壓力。
換句話說,每個系統發生緩存穿透是不可避免的,而我們需要做的是盡量避免大量的請求發生穿透,那怎么解決緩存穿透問題呢?解決緩存的穿透問題本質上是要解決怎么樣攔截請求的問題,一般情況下會有以下幾種方案:
回寫空值
當請求的數據在數據庫中不存在的時候,緩存系統可以把對應的key寫入一個空值,這樣當下次同樣的請求就不會直接穿透數據庫,而直接返回緩存中的空值了。這種方案是最簡單粗暴的,但是要注意幾點:
- 當有大量的空值被寫入緩存系統中,同樣會占用內存,不過理論上不會太多,完全取決于key的數量。而且根據緩存淘汰策略,可能會淘汰正常的數據緩存項
- 空值的過期時間應該短一些,比如正常的數據緩存過期時間可能為2小時,可以考慮空值的過期時間為10分鐘,這樣做一是為了盡快釋放服務器的內存空間,二是如果業務產生相應的真實數據,可以讓緩存的空值快速失效,盡快做到緩存和數據庫一致。
- //獲取用戶信息
- public static UserInfo GetUserInfo(int userId)
- {
- //從緩存讀取用戶信息
- var userInfo = GetUserInfoFromCache(userId);
- if (userInfo == null)
- {
- //回寫空值到緩存,并設置緩存過期時間為10分鐘
- CacheSystem.Set(userId, null,10);
- }
- return userInfo;
- }
布隆過濾器
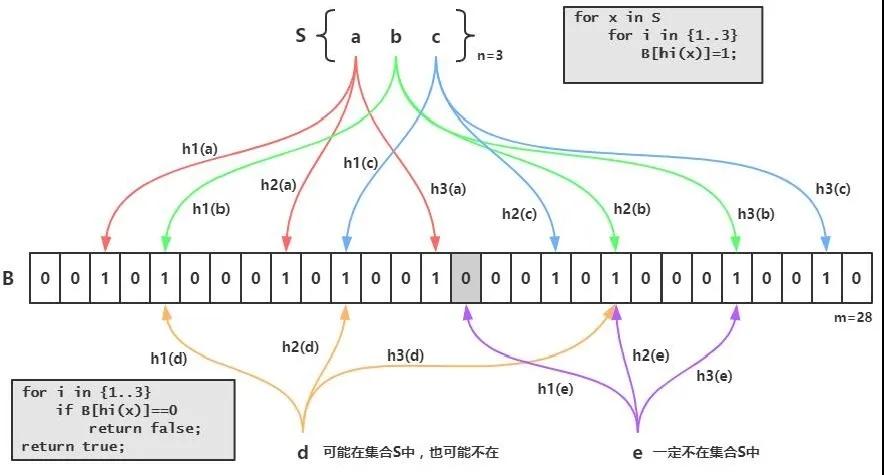
“布隆過濾器:將所有可能存在的數據哈希到一個足夠大的 bitmap 中,一個一定不存在的數據會被這個bitmap攔截掉,從而避免了對底層存儲系統的查詢壓力
布隆過濾器有幾個很大的優勢
- 占用內存非常小
- 對于判斷一個數據不存在百分百正確
由于布隆過濾器基于hash算法,所以在時間復雜度上是O(1),在應對高并發的場景下非常合適,不過使用布隆過濾器要求系統在產生數據的時候需要在布隆過濾器同時也寫入數據,而且布隆過濾器也不支持刪除數據,因為多個數據可能會重用同一個位置。
image
緩存雪崩
“緩存雪崩是指緩存中數據大批量同時過期,造成查詢數據庫數據量巨大,引起數據庫壓力過大導致系統崩潰。
與緩存穿透現象不同,緩存穿透是指緩存中不存在數據而造成會對數據庫造成大量查詢,而緩存雪崩是因為緩存中存在數據,但是同時大量過期造成。但是本質上是一樣的,都是對數據庫造成了大量的請求。
無論是穿透還是雪崩都面臨著同樣的數據會有多個線程同時請求,同時查詢數據庫,同時回寫緩存的一致性問題。舉例來說,當多個線程同時請求用戶id為1的用戶,這個時候緩存正好失效,那這多個線程同時會查詢數據庫,然后同時會回寫緩存,最可怕的是,這個回寫的過程中,另外一個線程更新了數據庫,就造成了數據不一致,這個問題在之前的文章中著重講過,大家一定要注意。
同樣的數據會被多個線程產生多個請求是產生雪崩的一個原因,針對這種情況的解決方案是把多個線程的請求順序化,使其只有一個線程會產生對數據庫的查詢操作,比如最常見的鎖機制(分布式鎖機制),現在最常見的分布式鎖是用redis來實現,但是redis實現分布式鎖也有一定的坑。
多個緩存key同時失效的場景是產生雪崩的主要原因,針對這樣的場景一般可以利用以下幾種方案來解決
設置不同過期時間
給緩存的每個key設置不同的過期時間是最簡單的防止緩存雪崩的手段,整體思路是給每個緩存的key在系統設置的過期時間之上加一個隨機值,或者干脆是直接隨機一個值,有效的平衡key批量過期時間段,消掉單位之間內過期key數量的峰值。
- public static int SetUserInfo(int userId)
- {
- //讀取用戶信息
- var userInfo = GetUserInfoFromDB(userId);
- if (userInfo != null)
- {
- //回寫到緩存,并設置緩存過期時間為隨機時間
- var cacheExpire = new Random().Next(1, 100);
- CacheSystem.Set(userId, userInfo, cacheExpire);
- return cacheExpire;
- }
- return 0;
- }
后臺單獨線程更新
這種場景下,可以把緩存設置為永不過期,緩存的更新不是由業務線程來更新,而是由專門的線程去負責。當緩存的key有更新時候,業務方向mq發送一個消息,更新緩存的線程會監聽這個mq來實時響應以便更新緩存中對應的數據。不過這種方式要考慮到緩存淘汰的場景,當一個緩存的key被淘汰之后,其實也可以向mq發送一個消息,以達到更新線程重新回寫key的操作。
緩存的可用性和擴展性
和數據庫一樣,緩存系統的設計同樣需要考慮高可用和擴展性。雖然緩存系統本身的性能已經比較高了,但是對于一些特殊的高并發的熱點數據,還是會遇到單機的瓶頸。舉個栗子:假如某個明星出軌了,這個信息數據會緩存在某個緩存服務器的節點上,大量的請求會到達這個服務器節點,當到達一定程度的時候同樣會發生down機的情況。類似于數據庫的主從架構,緩存系統也可以復制多分緩存副本到其他服務器上,這樣就可以將應用的請求分散到多個緩存服務器上,緩解由于熱點數據出現的單點問題。
和數據庫主從一樣,緩存的多個副本也面臨著數據的一致性問題,同步延遲問題,還有主從服務器相同key的過期時間問題。
至于緩存系統的擴展性同樣的道理,也可以利用“分片”的原則,利用一致性哈希算法將不同的請求路由到不同的緩存服務器節點,來達到水平擴展的要求,這一點和應用的水平擴展道理一樣。
寫在最后
通過以上可以看出,無論是應用服務器的高可用架構還是數據庫的高可用架構,還是緩存的高可用其實道理都是類似的,當我們掌握了其中一種就很容易的擴展到任何場景中。如果這篇文章對你有多幫助,請分享給身邊的朋友,最后歡迎大家留言寫下你們在日常開發中用到的其他關于緩存高可用,可擴展性,以及防止穿透和雪崩的方案,讓我們一起進步!!
本文轉載自微信公眾號「架構師修行之路」,可以通過以下二維碼關注。轉載本文請聯系架構師修行之路公眾號。
















