從阿里大促中,我理出的CPU與Load異常排查思路
前言
大家都知道服務器在大促期間由于流量的增加勢必導致機器的cpu與load變高,本文將與大家一起鞏固cpu和load的概念,為今年各種大促做準備的同時也是增加自己的技能儲備。
不過cpu和load這塊真的還是很需要積累的,筆者經驗尚淺,感覺還是有許多寫得不到位或不恰當的地方,如果有錯誤,希望大家可以幫助指正。
一、top命令
既然說了cpu和load,那總需要監控吧,沒有監控就不知道cpu和load,后面的一切也就無從談起了。
top命令是最常見的查看cpu和load的命令,拿我自己虛擬機上裝的ubuntu系統執行一下top命令(默認3秒刷1次,-d可指定刷新時間):
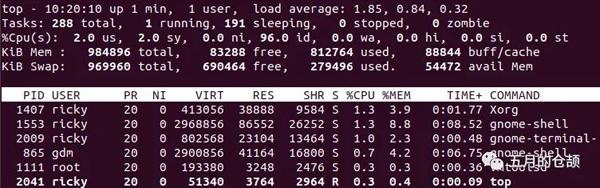
做了一張表格比較詳細地解釋了每一部分的含義,其中重要屬性做了標紅加粗:
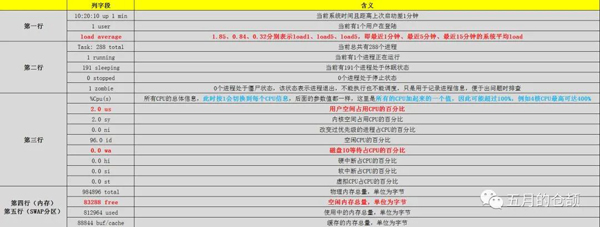
內存與SWAP輸出格式是一樣的,因此放在了一起寫。
二、cpu如何計算
當我們執行top命令的時候,看到里面的值(主要是cpu和load)是一直在變的,因此有必要簡單了解一下Linux系統中cpu的計算方式。
cpu分為系統cpu和進程、線程cpu,系統cpu的統計值位于/proc/stat下(以下的截圖未截全):

cpu、cpu0后面的這些數字都和前面的us、sy、ni這些對應,具體哪個對應哪個值不重要,感興趣的可以網上查一下文檔。
進程cpu的統計值位于/proc/{pid}/stat下:

線程cpu的統計值位于/proc/{pid}/task/{threadId}/stat下:

這里面的所有值都是從系統啟動時間到當前時間的一個值。因此,對于cpu的計算的做法是,采樣兩個足夠短的時間t1、t2:
- 將t1的所有cpu使用情況求和,得到s1;
- 將t2的所有cpu使用情況求和,得到s2;
- s2 - s1得到這個時間間隔內的所有時間totalCpuTime;
- 第一次的空閑idle1 - 第二次的空閑idle2,獲取采樣時間內的空閑時間;
- cpu使用率 = 100 * (totalCpuTime - idle) / totalCpuTime。
其他時間例如us、sy、ni都是類似的計算方式,總結起來說,cpu這個值反應的是某個采樣時間內的cpu使用情況。因此有時候cpu很高,但是打印線程堆棧出來發現高cpu的線程在查詢數據庫等待中,不要覺得奇怪,因為cpu統計的是采樣時間內的數據。
假設top觀察某段時間用戶空間cpu一直很高,那么意味著這段時間用戶的程序一直在占據著cpu做事情。
三、對load的理解
關于load的含義,其實有些文章把它跟行車過橋聯系在一起是比較恰當和好理解的:
一個單核的處理器可以形象得比喻成一條單車道,車輛依次行駛在這條單車道上,前車駛過之后后車才可以行駛。
如果前面沒有車輛,那么你順利通過;如果車輛眾多,那么你需要等待前車通過之后才可以通過。
因此,需要些特定的代號表示目前的車流情況,例如:
- 等于0.00,表示目前橋面上沒有任何的車流。實際上這種情況0.00和1.00之間是相同的,總而言之很通暢,過往的車輛可以絲毫不用等待的通過;
- 等于1.00,表示剛好是在這座橋的承受范圍內。這種情況不算糟糕,只是車流會有些堵,不過這種情況可能會造成交通越來越慢;
- 大于1.00,那么說明這座橋已經超出負荷,交通嚴重的擁堵。那么情況有多糟糕? 例如2.00的情況說明車流已經超出了橋所能承受的一倍,那么將有多余過橋一倍的車輛正在焦急的等待。
但是比喻終歸是比喻,從比喻中我們了解了,load表示的是系統的一個能力,但是我們卻不知道什么樣的任務會被歸到load的計算中。關于具體怎么樣的任務會被歸到load的計算中,可以使用man uptime命令看一下Linux對于load的解釋:
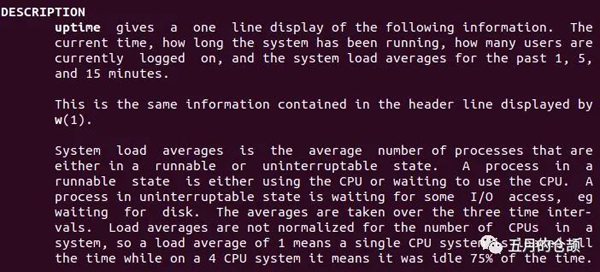
大致意思就是說,系統load是處于運行狀態或者不可中斷狀態的進程的平均數(標紅部分表示被算入load的內容)。一個處于運行狀態的進程表示正在使用cpu或者等待使用cpu,一個不可中斷狀態的進程表示正在等待IO,例如磁盤IO。load的平均值通過3個時間間隔來展示,就是我們看到的1分鐘、5分鐘、15分鐘,load值和cpu核數有關,單核cpu的load=1表示系統一直處在負載狀態,但是4核cpu的load=1表示系統有75%的空閑。
特別注意,load指的是所有核的平均值,這和cpu的值是有區別的。
還有一個重要的點是,查了資料發現,雖然上面一直強調的是"進程",但是進程中的線程數也是會被當作不同的進程來計算的,假如一個進程產生1000個線程同時運行,那運行隊列的長度就是1000,load average就是1000。
四、請求數和load的關系
之前我自己一直有個誤區:當成千上萬的請求過來,且在排隊的時候,后面的請求得不到處理,load值必然會升高。認真思考之后,這個觀點可真是大錯特錯,因此特別作為一段寫一下,和大家分享。
以Redis為例,我們都知道Redis是單線程模型的,這意味著同一時間可以有無數個請求過來,但是同一時間只有一個命令會被處理。
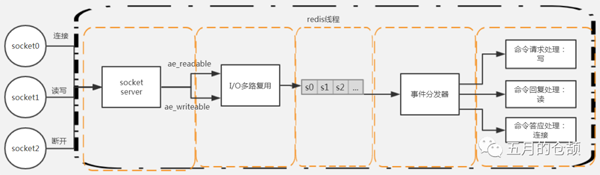
圖片來源:https://www.processon.com/view/5c2ddab0e4b0fa03ce89d14f
單獨的一條線程接到就緒的命令之后,會將命令轉給事件分發器,事件分發器根據命令的類型執行對應的命令處理邏輯。由于只有一條線程,只要后面排隊的命令足夠多到讓這條線程一個接一個不停地處理命令,那么load表現就等于1。
整個過程中,回看load這個值,它和請求數沒有任何關系,真正和load相關的是工作線程數量,main線程是工作線程、Timer是工作線程、GC線程也是工作線程,load是以線程/進程作為統計指標,無論請求數是多少,最終都需要線程去處理,而工作線程的處理性能直接決定了最終的load值。
舉個例子,假設一個服務中有一個線程池,線程池中線程數量固定為64:
- 正常來說一個任務執行時間為10ms,線程拿到任務10ms處理完,很快回歸線程池等待下一個任務到來,自然很少有處于運行狀態或者等待IO的線程,從一個統計周期來看load表現為很低;
- 某段時間由于系統問題,一個任務10s都處理不完,相當于線程一直在處理任務,在load的統計周期里面就體現出的值=64(不考慮這64條線程外的場景)。
因此,總而言之,搞清楚load值和請求數、線程數的關系非常重要,想清楚這些才能正確地進行下一步的工作。
五、load高、cpu高的問題排查思路
首先拋出一個觀點:cpu高不是問題,由cpu高引起的load高才是問題,load是判斷系統能力指標的依據。
為什么這么說呢,以單核cpu為例,當我們日常cpu在20%、30%的時候其實對cpu資源是浪費的,這意味著絕大多數時候cpu并沒有在做事,理論上來說一個系統極限cpu利用率可以達到100%,這意味著cpu完全被利用起來了處理計算密集型任務,例如for循環、md5加密、new對象等等。但是實際不可能出現這種情況,因為應用程序中不消耗cpu的IO不存在是幾乎不可能的,例如讀取數據庫或者讀取文件,因此cpu不是越高越好,通常75%是一個需要引起警戒的經驗值。
注意前面提到的是"引起警戒",意味著cpu高不一定是問題,但是需要去看一下,尤其是日常的時候,因為通常日常流量不大,cpu是不可能打到這么高的。如果只是普通的代碼中確實在處理正常業務那沒問題,如果代碼里面出現了死循環(例如JDK1.7中經典的HashMap擴容引發的死循環問題),那么幾條線程一直占著cpu,最后就會造成load的增高。
在一個Java應用中,排查cpu高的思路通常比較簡單,有比較固定的做法:
- ps -ef | grep java,查詢Java應用的進程pid;
- top -H -p pid,查詢占用cpu最高的線程pid;
- 將10進制的線程pid轉成16進制的線程pid,例如2000=0x7d0;
- jstack 進程pid | grep -A 20 '0x7d0',查找nid匹配的線程,查看堆棧,定位引起高cpu的原因。
網上有很多文章寫到這里就停了,實踐過程中并不是這樣。因為cpu是時間段內的統計值、jstack是一個瞬時堆棧只記錄瞬時狀態,兩個根本不是一個維度的事,因此完全有可能從打印出來的堆棧行號中看到代碼停留在以下地方:
- 不消耗cpu的網絡IO;
- for (int i = 0, size = list.size(); i < size; i++) {...};
- 調用native方法。
如果完全按照上面那一套步驟做的話碰到這種情況就傻眼了,冥思苦想半天卻不得其解,根本不明白為什么這種代碼會導致高cpu。針對可能出現的這種情況,實際排查問題的時候jstack建議打印5次至少3次,根據多次的堆棧內容,再結合相關代碼段進行分析,定位高cpu出現的原因,高cpu可能是代碼段中某個bug導致的而不是堆棧打印出來的那幾行導致的。
另外,cpu高的情況還有一種可能的原因,假如一個4核cpu的服務器我們看到總的cpu達到了100%+,按1之后觀察每個cpu的us,只有一個達到了90%+,其他都在1%左右(下圖只是演示top按1之后的效果并非真實場景):

這種情況下可以重點考慮是不是頻繁FullGC引起的。因為我們知道FullGC的時候會有Stop The World這個動作,多核cpu的服務器,除了GC線程外,在Stop The World的時候都是會掛起的,直到Stop The World結束。以幾種老年代垃圾收集器為例:
- Serial Old收集器,全程Stop The World;
- Parallel Old收集器,全程Stop The World;
- CMS收集器,它在初始標記與并發標記兩個過程中,為了準確標記出需要回收的對象,都會Stop The World,但是相比前兩種大大減少了系統停頓時間。
無論如何,當真正發生Stop The World的時候,就會出現GC線程在占用cpu工作而其他線程掛起的情況,自然表現也就為某個cpu的us很高而且他cpu的us很低。
針對FullGC的問題,排查思路通常為:
- ps -ef | grep java,查詢Java應用的進程pid;
- jstat -gcutil pid 1000 1000,每隔1秒打印一次內存情況共打印1000次,觀察老年代(O)、MetaSpace(MU)的內存使用率與FullGC次數;
- 確認有頻繁的FullGC的發生,查看GC日志,每個應用GC日志配置的路徑不同;
- jmap -dump:format=b,file=filename pid,保留現場;
- 重啟應用,迅速止血,避免引起更大的線上問題;
- dump出來的內容,結合MAT分析工具分析內存情況,排查FullGC出現的原因。
如果FullGC只是發生在老年代區,比較有經驗的開發人員還是容易發現問題的,一般都是一些代碼bug引起的。MetaSpace發生的FullGC經常會是一些詭異、隱晦的問題,很多和引入的第三方框架使用不當有關或者就是第三方框架有bug導致的,排查起來就很費時間。
那么頻繁FullGC之后最終會導致load如何變化呢?這個我沒有驗證過和看過具體數據,只是通過理論分析,如果所有線程都是空閑的,只有GC線程在一直做FullGC,那么load最后會趨近于1。但是實際不可能,因為如果沒有其他線程在運行,怎么可能導致頻繁FullGC呢。所以,在其他線程處理任務的情況下Stop The World之后,cpu掛起,任務得不到處理,更大可能的是load會一直升高。
最后順便提一句,前面一直在講FullGC,頻繁的YoungGC也是會導致load升高的,之前看到過的一個案例是,Object轉xml,xml轉Object,代碼中每處都new XStream()去進行xml序列化與反序列化,回收速度跟不上new的速度,YoungGC次數陡增。
六、load高、cpu低的問題排查思路
關于load的部分,我們可以看到會導致load高的幾個因素:
- 線程正在使用cpu;
- 線程正在等待使用cpu;
- 線程在執行不可被打斷的IO操作。
既然cpu不高,load高,那么線程要么在進行io要么在等待使用cpu。不過對于后者"等待使用cpu"我這里存疑,比如線程池里面10個線程,任務來的很慢,每次只會用到1個線程,那么9個線程都是在等待使用cpu,但是這9個線程明顯是不會占據系統資源的,因此我認為自然也不會消耗cpu,所以這個點不考慮。
因此,在cpu不高的情況下假如load高,大概率io高才是罪魁禍首,它導致的是任務一直在跑,遲遲處理不完,線程無法回歸線程池中。首先簡單講講磁盤io,既然wa表示的是磁盤io等待cpu的百分比,那么我們可以看下wa確認下是不是磁盤io導致的:

如果是,那么按照cpu高同樣的方式打印一下堆棧,查看文件io的部分進行分析,排查原因,例如是不是多線程都在讀取本地一個超大的文件到內存。
磁盤io導致的load高,我相信這畢竟是少數,因為Java語言的特點,應用程序更多的高io應當是在處理網絡請求,例如:
- 從數據庫中獲取數據;
- 從Redis中獲取數據;
- 調用Http接口從支付寶獲取數據;
- 通過dubbo獲取某服務中的數據。
針對這種情況,我覺得首先我們應該對整個系統架構的依賴比較熟悉,例如我畫一個草圖:
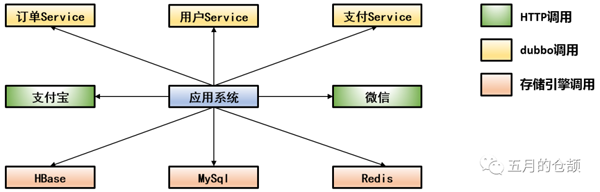
對依賴方的調用任何一個出現比較高的耗時都會增加自身系統的load,出現load高的建議排查方式為:
- 查日志,無論是HBase、MySql、Redis調用還是通過http、dubbo調用接口,調用超時,拿連接池中的連接超時,通常都會有錯誤日志拋出來,只要系統里面沒有捕獲異常之后不打日志直接吞掉一般都能查到相關的異常;
- 對于dubbo、http的調用,建議做好監控埋點,輸出接口名、方法入參(控制大小)、是否成功、調用時長等必要參數,有些時候可能沒有超時,但是調用2秒、3秒一樣會導致load升高,所以這種時候需要查看方法調用時長進行下一步動作。
如果上面的步驟還是沒用或者沒有對接口調用做埋點,那么還是萬能的打印堆棧吧,連續打印五次十次,看一下每次的堆棧是否大多都指向同一個接口的調用,網絡io的話,堆棧的最后幾行一般都有at java.net.SocketInputStream.read(SocketInputStream.java:129)。
七、Java應用load高的幾種原因總結
前面說了這么多,這里總結一下load高可能的一些原因:
- 死循環或者不合理的大量循環操作,如果不是循環操作,按照現代cpu的處理速度來說處理一大段代碼也就一會會兒的事,基本對能力無消耗;
- 頻繁的YoungGC;
- 頻繁的FullGC;
- 高磁盤IO;
- 高網絡IO。
系統load高通常都是由于某段發布的代碼有bug或者引入某些第三方jar而又使用不合理導致的,因此注意首先區分load高,是由于cpu高導致的還是io高導致的,根據不同的場景采取不同定位問題的方式。
當束手無策時,jstack打印堆棧多分析分析吧,或許能靈光一現能找到錯誤原因。
結語
先有理論,把理論想透了,實戰碰到問題的時候才能頭腦清楚。
坦白講,cpu和load高排查是一個很偏實戰的事情,這方面我還也有很長一條路需要走,身邊在這塊經驗比我豐富的同事多得很。很多人問過我,項目比較簡單,根本沒有這種線上問題需要我去排查怎么辦?這個問題只能說,平時多積累、多實戰是唯一途徑,假如沒有實戰機會,那么推薦三種方式:
- 自己通過代碼模擬各種異常,例如FullGC、死鎖、死循環,然后利用工具去查,可能比較簡單,但是萬丈高樓平地起,再復雜的東西都是由簡單的變化過來的;
- 多上服務器上敲敲top、sar、iostat這些命令,熟記每個命令的作用及輸出參數的含義;
- 去網上找一下其他人處理FullGC、CPU高方法的文章,站在巨人的肩膀上,看看前人走過的路,總結記錄一些實用的點。
當真的有實戰機會來的時候把握住,即使是同事排查的問題,也可以在事后搞清楚問題的來龍去脈,久而久之自然這方面的能力就會提高上去。