













5個小時,我們將800個微服務遷移到了云端
9 月 16 日晚上,我們將 FINN 的生產環境從本地數據中心遷移到了谷歌云平臺(GCP)。這意味著要遷移一個高流量的網站,該網站由一個復雜的分布式系統支持,由 800 多個應用程序、145 個數據庫和 16TB 數據組成。我們在夜間有規劃的停機時間窗口,但這一窗口越小越好。我們是怎么做的?請繼續閱讀本文!
關于將 FINN.no 移出我們的數據中心,并遷移到云平臺中的內部討論始于多年前。此后,我們一直在嘗試各種云技術和云提供商。當我們在 2016 年選擇 Kubernetes 作為平臺時,我們的指導思想就是在云平臺中運行 FINN。
從很久前開始,我們在思想上已經準備好將系統遷移到云端了,但一直沒有制定真正實現這一目標的策略或計劃。我們產品的某些部件早在 1998 年就開始使用了,因此遷移它們是一項艱巨的任務。但是,隨著數據中心愈加不堪重負、對更靈活解決方案的需求,以及我們去年成功將 Sybase 從 Solaris 遷移到 Linux 的經驗,都給了我們很多動力來認真考慮這一計劃。
我們從 2019 年 1 月開始評估各家云提供商。候選名單包括 AWS、Google Cloud、IBM Cloud 和 Azure。我們參加了很多研討會、會議和電話會議,評估了自行管理服務以及將我們的服務托管于其他云提供商等許多選項,最終我們決定采用“多云”方案,而選擇 GCP 作為我們大多數服務的首選項。該方案最終于 2019 年 8 月中旬被 Schibsted 批準。
1. 準備工作
遷移即將進行,我們必須制定一個計劃,將我們擁有的一切轉移到 GCP,同時保持 FINN 的正常運行。我們決定逐步遷移,使開發人員能夠隨著時間的推移遷移服務。但是,時間過得真快,我們意識到可用時間越來越少。基礎架構的惡化、現有數據中心計劃中的網絡翻新以及資源的匱乏,使我們很難看到逐步遷移的成功前景。全球疫情大流行也讓工作變得更困難了。我們被迫做出一些艱難的決定。
2020 年 6 月,我們了解到,我們需要采取更直接的方法,并確定向 GCP 迅速切換的日期。我們將目標日期定為 9 月 15 日,并獲得了 FINN 管理小組批準,準許 FINN.no 停機一晚。7 月,云平臺遷移被設置為 FINN 的第一要務;這意味著所有團隊必須完成他們負責的所有與云平臺遷移相關的工作,然后才能進行其他計劃的任務。是時候該去(遠程)工作了。
當我們決定放棄逐步遷移,決定快速切換時,擺在我們面前的艱巨任務就開始出現了。我們必須準備一個平臺,使我們能夠在一夜之間移動 800 多個應用、145 個數據庫、超過 16TB 的數據以及 183 個虛擬機。FINN 的基礎架構團隊已經為云平臺遷移做了很長時間的準備,但是這個決定使我們重新集中精力。現在,我們必須堅定地確定優先級,在必要時花時間深入探索技術,且始終保持目標清晰。在某些情況下,這意味著我們需要改變甚至放棄我們曾經投入大量時間的一些解決方案。
從夏天結束的那一刻起,我們就努力使這一計劃取得成功。我們必須對我們需要花時間要做的事情和必須等待的事情做出艱難的選擇。但是我們盡量不走捷徑,堅持我們的原則,例如基礎設施即代碼。隨著遷移日越來越近以及工作量的增加,我們的信心也隨之增加。
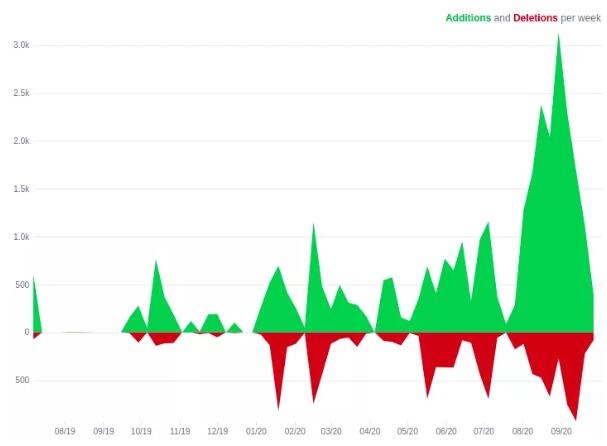
該圖顯示了隨著切換時間的臨近,我們用于維護 FINN 基礎架構的一個存儲庫的更改頻率不斷增長
對 FINN.no 的更改通常每天實行約 350 次。在切換前的最后 24 小時,我們決定建議使用“發行凍結”,這意味著那些既不能解決實時生產問題,又不能解決與云平臺遷移有關的更改應等到第二天。切換的前一天,更改頻率降低到一半左右,并且在云平臺切換開始前幾分鐘,最后一個產品部署到了我們的原有內部基礎架構中。
2. 云平臺切換
9 月 15 日 23:00 時,基礎架構團隊聚在一起(在線),準備就緒并檢查切換前檢查清單。由于每個人都在不同的地理位置,因此我們依靠詳細的運行手冊和視頻會議進行協作。對 FINN.no 的更改通常在不停機的情況下進行部署,站點停機是 1 級嚴重事件。不過,這不是一個正常的星期二晚上。午夜時分,我們將用戶重定向到靜態后備頁面后關閉了 FINN.no。半小時后,我們關閉了本地 Kubernetes 集群中的所有應用程序。

轉換期間在 FINN.no 上顯示的靜態后備頁面
然后我們準備遷移數據。Kafka 是我們微服務架構的基礎之一。每天大約有 20 億條消息(平均每秒 30,000 條)通過我們的 Kafka 集群,其穩定性對于 FINN 的正常運轉至關重要。Kafka 小組遷移了我們的 Kafka 群集,該團隊暫時以“延伸集群”配置運行該集群,將我們的本地數據中心和云平臺作為單個集群。我們提前幾周仔細計劃和實施了延伸集群配置。Kafka 中的主題在切換前一周已復制到 GCP 的 broker 中,而 GCP 的 broker 在轉換過程中成為主 broker。
需要持久存儲的服務通常使用我們的 25 個 PostgreSQL 集群之一或我們的 Sybase 集群。我們通過預先在 GCP 中設置數據庫副本,并在切換過程中所有應用程序停止后切換主數據庫來遷移這些數據庫集群。在切換當天的 01:35,Kafka 以及我們所有的 PostgreSQL 和 Sybase 數據庫都運行在了 GCP 中。
移動持久數據后,我們觸發了所有應用程序到新的 Google Container Engine(GKE)集群的部署。到 02:30,所有 800 個應用程序(超過 1500 個 Kubernetes 的 pod)都已部署到 GKE。至此,我們當晚只遇到了一些小的問題和延誤,并已經準備好進行內部測試。
在切換之夜前,我們在所有領域的遷移準備和測試計劃方面都做得非常出色,當午夜測試開始,看到綠燈亮起,我們的基礎架構團隊感到非常欣慰。對平臺所有不同部分的自組織測試的效果甚至超出了我們的想象!
經過所有團隊的良好團隊合作,修復了一些應用部署、損壞的數據庫表和其他一些小問題之后,云平臺中的 FINN 于 04:43 啟用,沒有發生重大事故。
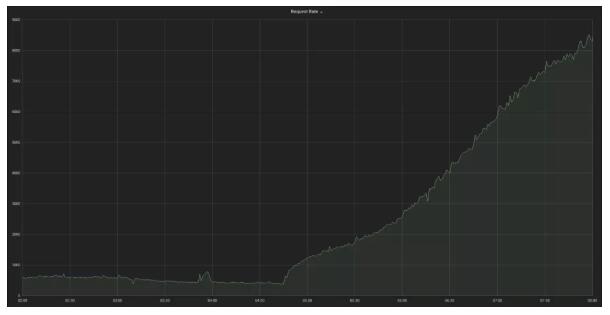
在 FINN.no 在云平臺中于 04:43 啟用后,通過某個負載均衡器的請求的速率增長曲線
我們為能夠成功進行云平臺切換而感到自豪!
沒有 FINN Technology 的優秀人才,遷移不可能成功。我們在組織的各個部門都得到支持,當行動號召到來時,每個人都加入進來并做了應做的部分工作。在準備階段,開發團隊一直在努力處理防火墻、網絡路由和負載平衡器,發現我們新的 GCP 基礎架構中的問題,并與基礎架構團隊合作解決這些問題。在切換之夜的前幾個星期,我們在工作時間還針對開發環境進行了轉換演習。這次“排演”使我們充滿信心,相信我們可以在指定的停機時間窗口內執行轉換,幫助我們發現和糾正工具方面的問題,并且對于完善生產切換的運行手冊非常有幫助。這兩件事都有助于將風險降低到可接受的水平。
由于我們的遷移工作有一個硬期限,因此許多系統必須采用直接遷移方式進行移動。當我們稍微適應云環境時,我們期待將基礎架構的這些部分也變得更加云原生化。












