ML Ops:數據質量是關鍵
ML Ops 是 AI 領域中一個相對較新的概念,可解釋為「機器學習操作」。如何更好地管理數據科學家和操作人員,以便有效地開發、部署和監視模型?其中數據質量至關重要。
本文將介紹 ML Ops,并強調數據質量在 ML Ops 工作流中的關鍵作用。
ML Ops 的發展彌補了機器學習與傳統軟件工程之間的差距,而數據質量是 ML Ops 工作流的關鍵,可以加速數據團隊,并維護對數據的信任。
什么是 ML Ops
ML Ops 這個術語從 DevOps 演變而來。
DevOps 是一組過程、方法與系統的統稱,用于促進開發(應用程序 / 軟件工程)、技術運營和質量保障(QA)部門之間的溝通、協作與整合。DevOps 旨在重視軟件開發人員(Dev)和 IT 運維技術人員(Ops)之間溝通合作的文化、運動或慣例。透過自動化軟件交付和架構變更的流程,來使得構建、測試、發布軟件能夠更加地快捷、頻繁和可靠。
而 MLOps 基于可提高工作流效率的 DevOps 原理和做法,例如持續集成、持續交付和持續部署。ML Ops 將這些原理應用到機器學習過程,其目標是:
- 更快地試驗和開發模型
- 更快地將模型部署到生產環境
- 質量保證
DevOps 的常用示例是使用多種工具對代碼進行版本控制,如 git、代碼審查、持續集成(CI,即頻繁地將代碼合并到共享主線中)、自動測試和持續部署(CD,即自動將代碼合并到生產環境)。
在應用于機器學習時,ML Ops 旨在確保模型輸出質量的同時,加快機器學習模型的開發和生產部署。但是,與軟件開發不同,ML 需要處理代碼和數據:
- 機器學習始于數據,而數據來源不同,需要用代碼對不同來源數據進行清洗、轉換和存儲。
- 然后,將處理好的數據提供給數據科學家,數據科學家進行代碼編寫,完成特征工程、開發、訓練和測試機器學習模型,最終將這些模型部署到生產環境中。
- 在生產中,ML 模型是以代碼的形式存在的,輸入數據同樣可以從各種來源獲取,并創建用于輸入產品和業務流程的輸出數據。
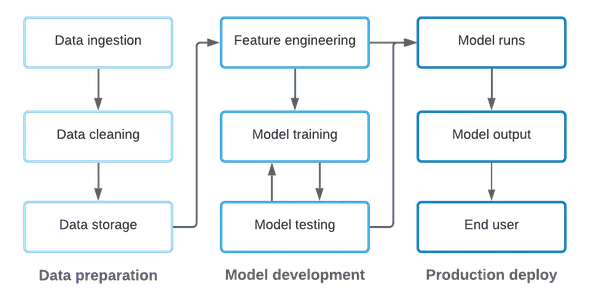
雖然上文的描述對該過程進行了簡化,但是仍然可以看出代碼和數據在 ML 環境中是緊密耦合的,而 ML Ops 需要兼顧兩者。
具體來說,這意味著 ML Ops 包含以下任務:
- 對用于數據轉換和模型定義的代碼進行版本控制;
- 在投入生產之前,對所獲取的數據和模型代碼進行自動測試;
- 在穩定且可擴展的環境中將模型部署到生產中;
- 監控模型性能和輸出。
數據測試和文檔記錄如何適配 ML Ops?
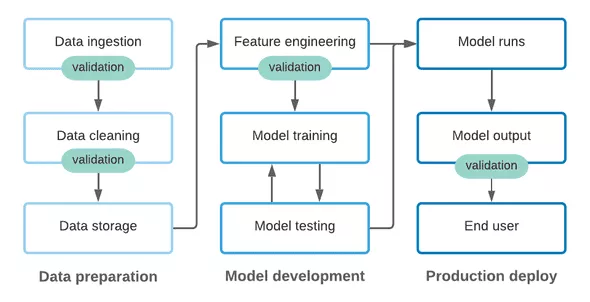
ML Ops 旨在加速機器學習模型的開發和生產部署,同時確保模型輸出的質量。當然,對于數據質量人員來說,要實現 ML 工作流中各個階段的加速和質量,數據測試和文檔記錄是非常重要的:
- 在利益相關者方面,質量差的數據會影響他們對系統的信任,從而對基于該系統做出決策產生負面影響。甚至更糟的是,未引起注意的數據質量問題可能導致錯誤的結論,并糾正這些問題又會浪費很多時間。
- 在工程方面,急于修復下游消費者注意到的數據質量問題,是消耗團隊時間并緩慢侵蝕團隊生產力和士氣的頭號問題之一。
- 此外,數據文檔記錄對于所有利益相關者進行數據交流、建立數據合同至關重要。
下文將從非常抽象的角度介紹 ML pipeline 中的各個階段,并討論數據測試和文檔記錄如何適應每個階段。
1. 數據獲取階段
即使是在數據集處理的早期階段,從長遠來看,對數據進行質量檢查和文檔記錄可以極大地加速操作。對于工程師來說,可靠的數據測試非常重要,可以使他們安全地對數據獲取 pipeline 進行更改,而不會造成不必要的問題。同時,當從內部和外部上游來源獲取數據時,為了確保數據出現未預料的更改,在獲取階段進行數據驗證是非常重要的。
2. 模型開發
本文將特征工程、模型訓練和模型測試作為核心模型開發流程的一部分。在這個不斷迭代的過程中,圍繞數據轉換代碼和支持數據科學家的模型輸出提供支持,因此在一個地方進行更改不會破壞其他地方的內容。
在傳統的 DevOps 中,通過 CI/CD 工作流進行持續的測試,可以快速地找出因代碼修改而引入的任何問題。更進一步,大多數軟件工程團隊要求開發人員不僅要使用現有的測試來測試代碼,還要在創建新功能時添加新的測試。同樣,運行測試以及編寫新的測試應該是 ML 模型開發過程的一部分。
3. 在生產中運行模型
與所有 ML Ops 一樣,在生產環境中運行的模型依賴于代碼和輸入數據,來產生可靠的結果。與數據獲取階段類似,我們需要保護數據輸入,以避免由于代碼更改或實際數據更改而引起的不必要問題。同時,我們還應該圍繞模型輸出進行一些測試,以確保模型繼續滿足我們的期望。
尤其是在具有黑盒 ML 模型的環境中,建立和維護質量標準對于模型輸出至關重要。同樣地,在共享區域記錄模型的預期輸出可以幫助數據團隊和利益相關者定義和傳達「數據合同」,從而增加 ML pipeline 的透明度和信任度。
原文鏈接:https://greatexpectations.io/blog/ml-ops-data-quality/
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】