低代碼機器學習工具
機器學習有潛力幫助解決企業和整個世界范圍內的各種問題。通常,要開發機器學習模型并將該模型部署到可以在操作上使用的狀態,需要對編程有深入的了解,并且需要充分了解其背后的算法。
這將機器學習的使用限制在一小部分人中,因此也限制了可以解決的問題數量。
幸運的是,在過去的幾年中,涌現了許多庫和工具,這些庫和工具減少了模型開發所需的代碼量,或者在某些情況下完全消除了代碼開發。 這為非數據科學家(如分析師)發揮了利用機器學習功能的潛力,并允許數據科學家更快地對模型進行原型制作。
這是一些我最喜歡的用于機器學習的低代碼工具。
PyCaret
PyCaret是Python的包裝器,用于流行的機器學習庫,例如Scikit-learn和XGBoost。 它使僅需幾行代碼就能將模型開發為可部署狀態。
可以通過pip安裝Pycaret。 有關更詳細的安裝說明,請參閱PyCaret文檔。
- pip install pycaret
PyCaret具有公共數據集的存儲庫,可以使用pycaret.datasets模塊直接安裝。 完整列表可在此處找到,但出于本教程的目的,我們將使用一個非常簡單的數據集來解決稱為"葡萄酒"數據集的分類任務。
PyCaret庫包含一組模塊,用于解決所有常見的機器學習問題,其中包括:
- 分類。
- 回歸。
- 聚類。
- 自然語言處理。
- 關聯規則挖掘。
- 異常檢測。
要創建分類模型,我們需要使用pycaret.classification模塊。 創建模型非常簡單。 我們只需調用將Model ID作為參數的create_model()函數即可。 您可以在此處找到支持的型號及其對應ID的完整列表。 或者,您可以在導入適當的模塊后運行以下代碼以查看可用模型的列表。
- from pycaret.classification import *
- models()
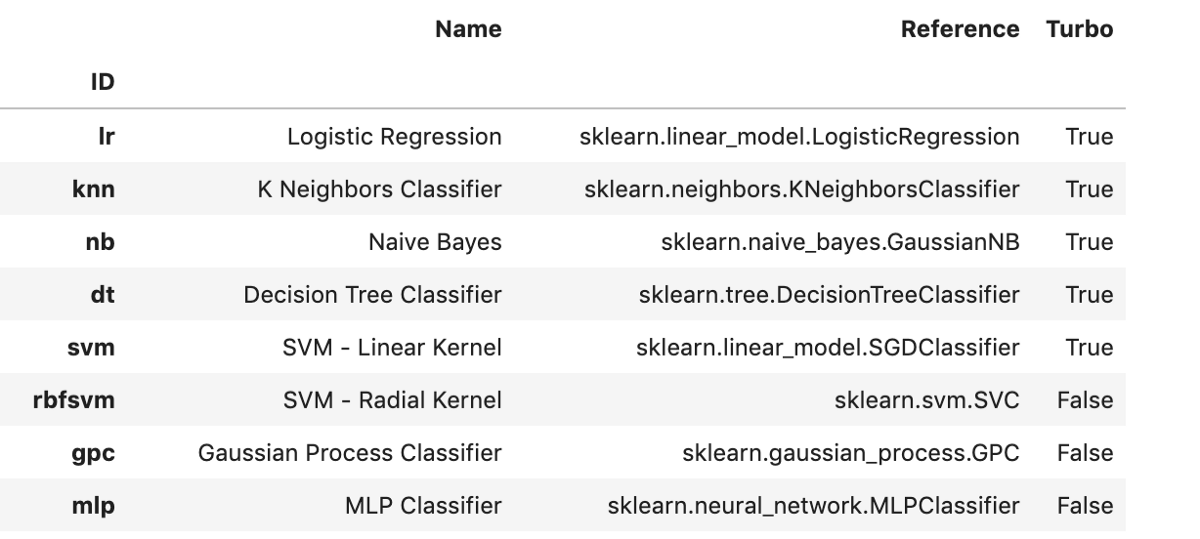 > A snapshot of models available for classification. Image by Author.
> A snapshot of models available for classification. Image by Author.
在調用create_model()之前,您首先需要調用setup()函數來為您的機器學習實驗指定適當的參數。 在這里,您可以指定諸如測試序列拆分的大小以及是否在實驗中實施交叉驗證之類的內容。
- from pycaret.classification import *
- rf = setup(datadata = data,
- target = 'type',
- train_size=0.8)
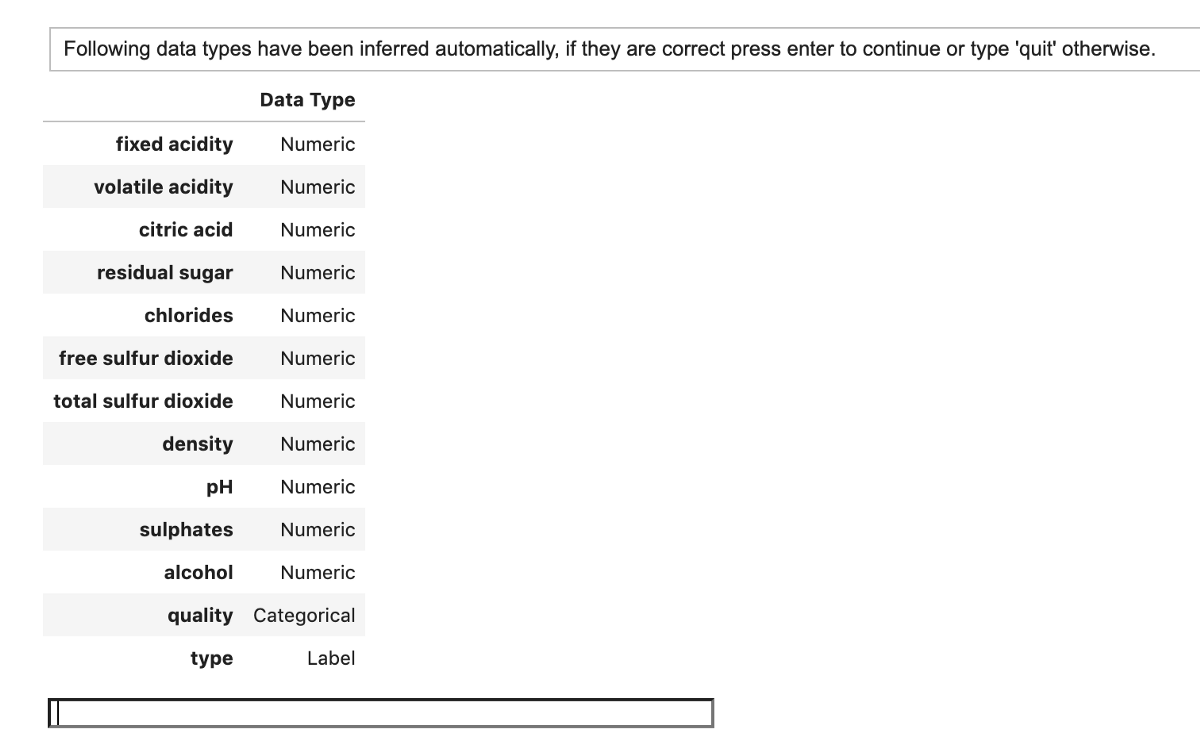
- rf_model = create_model('rf')
create_model()函數將自動推斷數據類型并使用默認方法處理這些數據類型。 運行create_model()時,您將收到以下輸出,其中顯示了推斷的數據類型。
> Image by Author.
PyCaret將使用一組默認的預處理技術來處理諸如分類變量和估算缺失值之類的事情。 但是,如果您需要更定制的數據解決方案,則可以在模型設置中將它們指定為參數。 在下面的示例中,我更改了numeric_imputation參數以使用中位數。
- from pycaret.classification import *
- rf = setup(datadata = data,
- target = 'type',
- numeric_imputation='median')
- rf_model = create_model('rf')
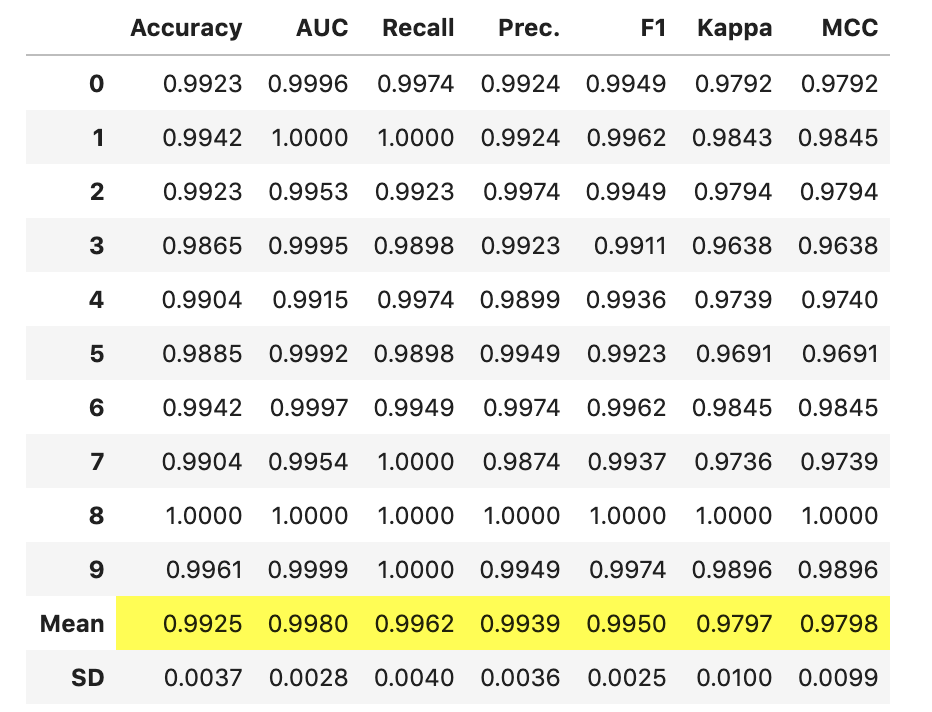
對參數滿意后,請按Enter鍵,模型將最終確定并顯示性能結果網格。
> Image by Author.
PyCaret還具有plot_model()函數,該函數顯示模型性能的圖形表示。
- plot_model(rf_model)
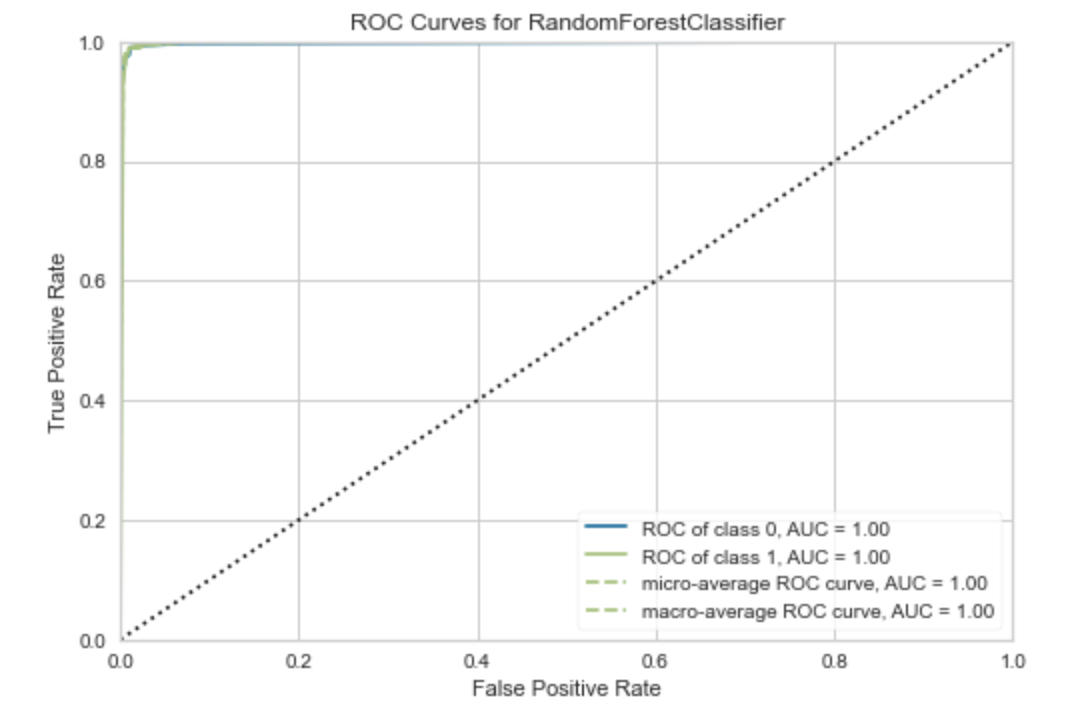
> Image by Author.
本教程剛剛展示了使用PyCaret庫進行模型訓練的基礎。 還有更多功能和模塊可提供完整的低碼機器學習解決方案,包括功能工程,模型調整,持久性和部署。
BigQuery ML
Google在2018年發布了一個名為BigQuery ML的新工具。 BigQuery是Google的云數據倉庫解決方案,旨在為數據分析師和科學家提供快速訪問大量數據的途徑。 BigQuery ML是一種工具,可讓僅使用SQL從BigQuery數據倉庫直接開發機器學習模型。
自從發布以來,BigQueryML已經發展到可以支持大多數常見的機器學習任務,包括分類,回歸和聚類。 您甚至可以導入自己的Tensforflow模型以在工具中使用。
根據我自己的經驗,BigQueryML是用于加速模型原型制作的極其有用的工具,并且還可以用作基于生產的系統來解決簡單的問題。
為了簡要介紹該工具,我將使用稱為成人收入數據集的數據集來說明如何在BigQueryML中建立和評估邏輯回歸分類模型。
該數據集可以在UCI機器學習存儲庫中找到,我正在使用以下Python代碼以CSV文件的形式下載。
- url_data = 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data'
- column_names = ['age', 'workclass', 'fnlwgt', 'education', 'educational-num','marital-status',
- 'occupation', 'relationship', 'race', 'gender','capital-gain', 'capital-loss',
- 'hours-per-week', 'native-country','income']
- adults_data = pd.read_csv(url_data, names=column_names)
- adults_data.to_csv('adults_data.csv')
這是一個腳本,用于下載數據并導出為CSV文件。
如果您還沒有Google Cloud Platform(GCP)帳戶,則可以在此處創建一個。 最初注冊時,您將獲得$ 300的免費信用額度,足以試用以下示例。
進入GCP后,從下拉菜單導航至BigQuery網絡用戶界面。 如果您是第一次使用GCP,則需要創建一個項目并使用BigQuery進行設置。 Google快速入門指南在此處提供了很好的概述。
我先前下載的CSV文件可以直接上傳到GCP中以創建表格。

> Image by Author.
您可以通過單擊邊欄中的表名稱并選擇預覽來檢查表中的數據。 現在,成人的數據就是BigQuery中的數據。
> Image by Author.
要針對這些數據訓練模型,我們只需編寫一個SQL查詢,該查詢從表中選擇所有內容(*),將目標變量(收入)重命名為label,并添加邏輯以創建名為" adults_log_reg"的邏輯回歸模型。
有關所有模型選項,請參見此處的文檔。
- CREATE MODEL `mydata.adults_log_reg`
- OPTIONS(model_type='logistic_reg') AS
- SELECT *,
- ad.income AS label
- FROM
- `mydata.adults_data` ad
如果我們單擊現在將出現在數據表旁邊的側欄中的模型,則可以看到對訓練效果的評估。
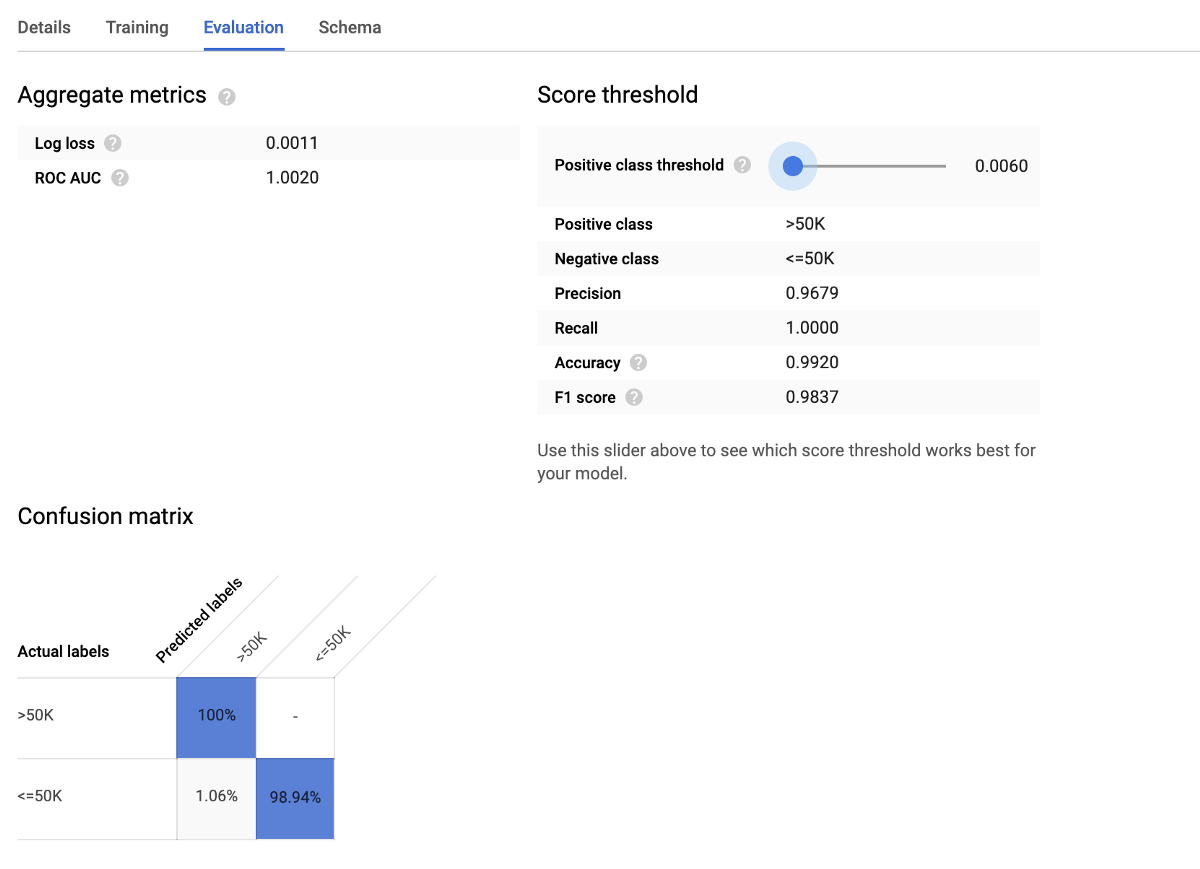
> Image by Author.
現在我們可以使用模型使用ML.PREDICT函數進行預測。
Fastai
眾所周知,諸如Tensorflow之類的流行深度學習框架具有陡峭的學習曲線,對于初學者或非數據科學家而言,可能很難起步并運行它。 fastai庫提供了一個高級API,使您可以用幾行簡單的代碼來訓練神經網絡。
Fastai與Pytorch一起使用,因此您需要先安裝這兩個庫,然后才能使用它。
- pip install pytorch
- pip install fastai
fastai庫具有用于處理結構化數據和非結構化數據(例如文本或圖像)的模塊。 在本教程中,我們將使用fastai.tabular.all模塊來解決我們之前使用的葡萄酒數據集的分類任務。
類似于PyCaret,fastai將通過嵌入層對非數字數據類型執行預處理。 為了準備數據,我們使用TabularDataLoaders幫助器函數。 在這里,我們具體說明了數據框的名稱,列的數據類型以及我們要模型執行的預處理步驟。
要訓練神經網絡,我們只需使用tabular_learner()函數,如下所示。
- dl = TabularDataLoaders.from_df(data, y_names="type",
- cat_names = ['quality'],
- cont_names = ['fixed acidity', 'volatile acidity',
- 'citric acid', 'residual sugar',
- 'chlorides', 'free sulfur dioxide',
- 'total sulfur dioxide', 'density',
- 'pH', 'sulphates', 'alcohol'],
- procs = [Categorify, FillMissing, Normalize])
運行此代碼后,將顯示性能指標。

> Image by Author.
要使用模型進行預測,您可以簡單地使用learning.predict(df.iloc [0])。