













新一代的鍵值存儲 KVell · SOSP 2019
本文要介紹的是 2019 年 SOSP 期刊中的論文 —— KVell: the Design and Implementation of a Fast Persistent Key-Value Store[^1],該論文實現的 KVell 是為現代 SSD 開發的鍵值存儲系統,與使用 LSM 樹(Log-structured merge-tree)或者 B 樹的主流鍵值存儲不同,KVell 為了充分利用新設備的性能并降低 CPU 的開銷使用了完全不同的設計。
作為軟件工程師,我們直接與硬件打交道的概率其實很少,大多數時間都會通過操作系統以和 POSIX 間接操作不同的硬件。雖然看起來過去 10 年磁盤等存儲硬件的演變與更新非常緩慢,但是實際上:
- 磁盤遠比 10 年前要快得多;
- 磁盤的隨機和順序 I/O 性能差距變小;
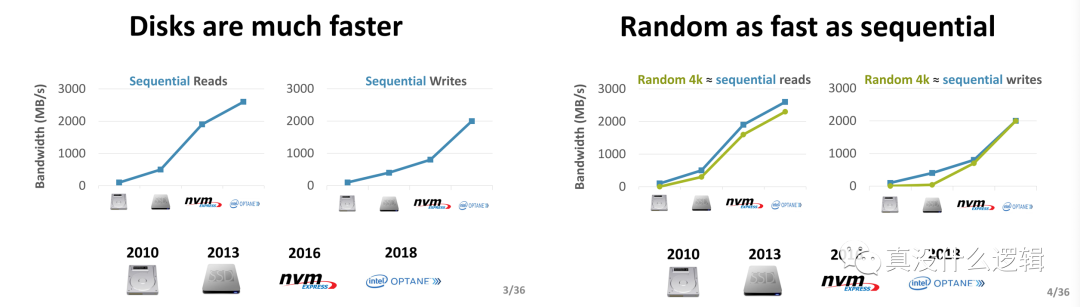
圖 1 - 磁盤的演進[^2]
磁盤性能和特性的演進使得在過去很多鍵值存儲成立的設計變得無效,例如:隨機 I/O 的速度遠遠慢于順序 I/O,很多數據庫為了減少隨機 I/O 的次數會使用特定的數據結構并犧牲一些 CPU 計算資源,但是在最新的硬件上已經沒有太多的必要了。
KVell 的論文中不止提到了目前主流鍵值存儲在新存儲設備上各種問題,還給出了最新的設計原則、實現方式以及對性能的評估。我們在這里不會面面俱到的介紹論文中全部的內容,主要會分析主流鍵值存儲的問題以及最新的設計原則,其余的內容各位讀者可以在論文中自行探索。
實現問題
目前的大多數的鍵值存儲系統都會使用 LSM 樹或者 B 樹作為主要的數據結構存儲數據,這兩種不同的數據結構適合用于不同類型的工作負載:
LSM 樹:適合寫密集型的負載;
B 樹:適合讀密集型的負載;
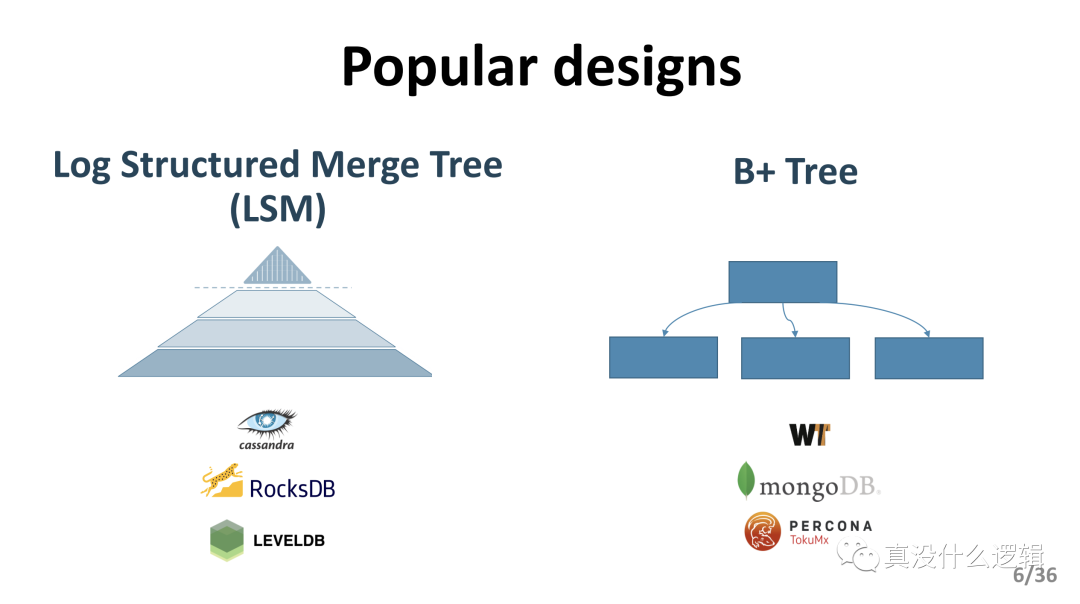
圖 2 - LSM 和 B 樹
RocksDB 和 Cassandra 等數據庫都使用 LSM 樹,而 MongoDB 以及其他的數據庫都會使用 B 樹和它的變種。雖然這兩者設計在過去都有著優異的表現,不過這兩種設計在 NVMe SSD 這種較新的硬件上表現地并不好,CPU 成為了瓶頸并導致嚴重的性能波動。
LSM 樹
LSM 樹是為寫密集型負載特別優化的數據結構,在 LSM 樹中,我們使用內存緩存接收所有的寫操作并將變更批量寫入磁盤,內存緩存中的數據會被后臺線程合并到持久存儲里的樹形結構中。
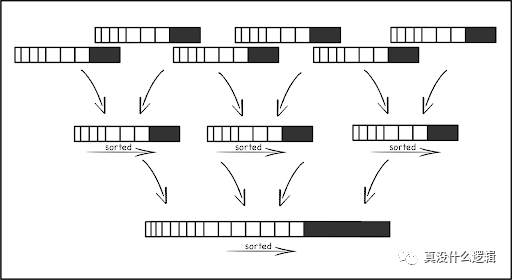
圖 3 - LSM 樹
磁盤中的數據結構包含多個層級,每個層級都會包含多個不可變的、排序后的文件,同一個層級中文件的鍵范圍也不會有重疊。為了保證上述特性,LSM 引入了 CPU 和 I/O 密集的操作 — 壓縮,如上圖所示,壓縮會將多個低層級的文件合并成更高層級的文件,保證鍵值對的順序并刪掉其中重復的鍵。這也使得 CPU 在新的存儲設備上已經成為 LSM 樹的主要瓶頸,這種設計讓我們在舊設備上花費 CPU 時間保證數據的順序并降低掃描操作順序訪問磁盤時的延遲。
除了 CPU 成為瓶頸之外,使用 LSM 樹的鍵值存儲的負載在數據壓縮時會受到顯著的影響,論文中的數據表示 RocksDB 在壓縮期間的性能可能會降低一個數量級,雖然有一些技術可以緩解數據壓縮的影響,但是這些方法在高端的 SSD 上卻并不適用。
B 樹
B+ 樹只在葉節點存儲鍵值對數據,內部的節點只包含用于路由的鍵,每個葉節點都包含一組排序后的鍵值對,所有的葉節點會組成方便掃描的鏈表。最先進的 B+ 樹為了實現優異的性能都會依賴緩存,大多數的寫操作也都會先寫入提交日志再寫入緩存,當緩存中的數據被驅逐時,B+ 樹中的信息才會被更新。
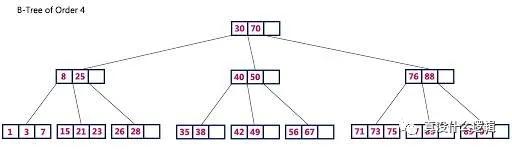
圖 4 - B 樹
B+ 樹中有兩種操作可以持久化其中的數據,也就是檢查點(Checkpoint)和驅逐(Eviction);其中,前者是按照固定頻率觸發的,當日志的大小達到了特定的閾值后才會觸發,這樣可以保證提交日志的大小在固定范圍內,而驅逐會從緩存向樹中寫入臟數據,它也會在緩存達到特定閾值時觸發寫入。
這種設計更容易受到同步(Synchronization)額外開銷的影響,論文在測試中發現只有 18% 的時間用于處理客戶端的請求,而其他時間都用于不同的等待,內核中 75% 的時間都在等待 futex 和 yield 等函數調用。
當內存中數據的驅逐不能快速完成時,B 樹的性能也會受到影響,論文中的數據表示 WiredTiger 的吞吐量會在延遲期間從 120 Kops/s 降低到 8.5Kops/s,這種巨大的影響持續幾秒鐘的時間才會恢復。
設計原則
為了利用新存儲設備的特性并減少鍵值存儲的 CPU 開銷,我們在現代 SSD 上開發的 KVell 會遵循如下所示的設計原則提高鍵值存儲的性能:
- 不共享數據:所有的數據結構都分片存儲在不同的 CPU 上,所有的 CPU 也就不需要在執行計算時同步數據;
- 磁盤中的數據不排序、內存中的索引排序:在磁盤上存儲未經排序的數據,避免昂貴的重排操作;
- 減少系統調用、而不是順序 I/O:因為現代 SSD 上的隨機 I/O 和順序 I/O 有著相似的性能,所以減少批處理 I/O 能夠降低 CPU 的額外開銷;
- 不需要提交日志:不在內存中緩存數據的更新,避免不必要的 I/O 操作;
不共享數據
在多線程的軟件系統中,稍微有常識的人都知道不同線程之間同步數據會對性能帶來比較大的影響,讓多個線程之間不共享數據就可以避免上述的同步開銷,減少線程等待帶來的性能損失。
圖 5 - 不共享數據的設計
為了實現這一目標,KVell 的每個線程都會處理一組特定鍵的操作并維護這些鍵相關的私有數據結構:
- 輕量級的、內存中的 B 樹索引 — 存儲了鍵在持久存儲的位置;
- I/O 隊列 — 負責從持久存儲中快速讀取或者寫入數據;
- 空閑列表 — 內存中的用于存儲鍵值對的硬盤塊;
- 頁面緩存 — 使用內部的頁面緩存,不依賴于操作系統;
鍵值存儲的大多數操作都只是對單個鍵的增刪改查,這些操作都不需要多線程之間的數據同步,只有遍歷鍵值的掃描才需要不同線程之間同步內存中的 B 樹索引。
磁盤不排序
因為 KVell 不會在磁盤上按照順序排序數據,所以鍵值對在磁盤中初始位置就是它的最終位置,這種不排序的方式不僅可以減少插入項目的額外開銷,而且可以消除磁盤維護操作帶來的 CPU 開銷。
無序的鍵值對雖然可以降低寫操作的開銷,但是也會影響掃描時的性能,不過根據論文中的測試,掃描的操作在遇到中等大小的負載以及大鍵值對時不會被明顯地影響,所以這個結果在多數情況下是可以接受的。
減少系統調用
在 KVell 中,所有的操作都會在磁盤中執行隨機的讀寫,所以它不會浪費 CPU 時間將隨機 I/O 轉換成順序 I/O。與 LSM 鍵值對類似,KVell 會將 I/O 請求批量轉發給磁盤,它的主要目的是減少系統調用的次數,即 CPU 的額外開銷。有效地鍵值存儲應該向磁盤發出足夠的請求保證磁盤擁有足夠的工作,但是不應該發出過多的工作影響磁盤的性能并帶來較高的延遲。
移除提交日志
KVell 不會依賴提交日志決定數據是否被系統持久化,它只會在更新寫入到磁盤的最終位置時確認更新,一旦更新被工作線程提交,它會在下一批 I/O 請求中處理。提交日志的作用其實是將隨機 I/O 變成順序 I/O,解決崩潰帶來的一致性影響,但是因為今天的隨機 I/O 與順序 I/O 已經有著類似的性能,所以提交日志在鍵值存儲中已經失去了過去的作用,移除提交日志可以減少磁盤帶寬的占用。
總結
KVell 作為基于最新硬件的鍵值存儲系統,它在特定場景下有著非常優異的性能表現,論文中給出了它與主流的鍵值存儲在不同負載下的吞吐量對比,其中 YCSB A、YCSB B、YCSB C 和 YCSDN E 分別是寫密集型、讀密集型、只讀和掃描密集型地任務,從中我們可以看出,在除了掃描密集型地任務之外的其他負載中,KVell 的表現都遠好于 RocksDB 等主流鍵值存儲:
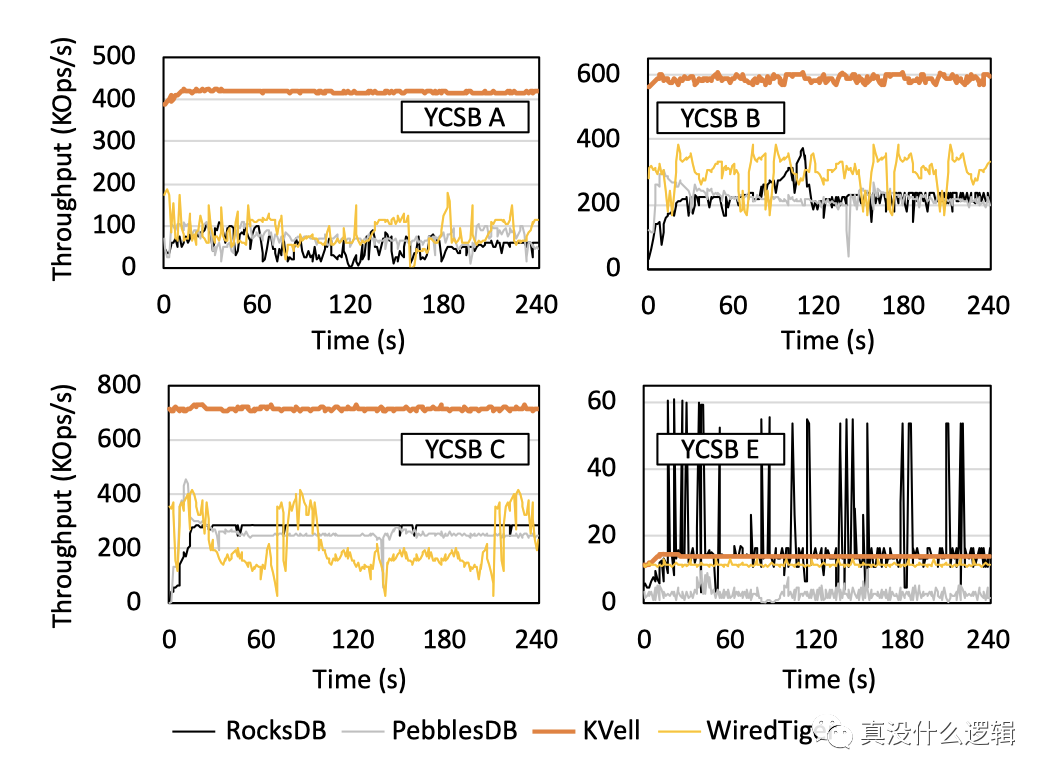
圖 6 - KVell 吞吐量對比
作為軟件工程師,雖然說操作系統為我們提供了操作硬件的標準接口,使得我們不用于硬件直接接觸,可以將更多的精力放到軟件上,但是我們仍然要時刻牢記硬件對軟件系統的諸多影響和限制并用發展的眼光看待硬件的進步,也只有軟硬件結合才能帶來極致的性能。
本文轉載自微信公眾號「真沒什么邏輯」,可以通過以下二維碼關注。轉載本文請聯系真沒什么邏輯公眾號。

















