2020數據庫選型攻略:專用VS多模
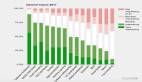
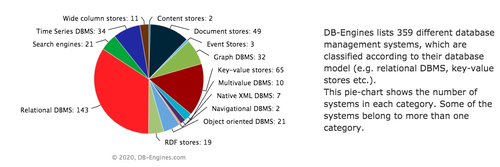
數據庫選型越來越難,據DB-Engines數據庫流行度排行榜顯示,目前全球有多達359個開源和商業的數據庫。
從應用類型看,有OLTP事務型數據庫,有OLAP分析型數據庫,還有HTAP混合型數據庫。
從存儲方式看,有關系型數據庫和非關系型數據庫(NoSQL)之分。而NoSQL數據庫又依據支持的數據模型不同,分為鍵值數據庫、文檔數據庫,列式數據庫,圖形數據庫等。
如果從架構類型看,又分Share Everything、Share Storage、Share Nothing。
數據庫市場百花齊放雖然給企業帶來了更多選擇,但也導致選型變得更加困難。
專用 VS 多模
關于專用數據庫與多模數據庫之爭,由來已久。其中,AWS屬于專用數據庫派,認為數據庫就應該像汽車一樣,不同的汽車解決不同的運輸需求,不同數據庫去解決不同場景需求,而不是通過關系數據庫來一刀切。
因此,AWS提供的數據庫產品組合多達十幾種。
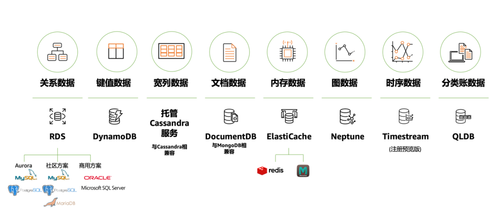
AWS 數據庫服務一覽圖
而甲骨文、微軟、SAP則屬于“瑞士軍刀”派,即多模數據庫派。通過擴展其SQL查詢功能或添加功能(如R或Python支持)來實現多模功能。
去年,DeveloperWeek一組調查數據顯示。有將近一半受訪者實際上使用了不止一種數據庫來支持其業務應用程序,而不是單個數據庫!使用多個數據庫的比例為44.3%,使用一個數據庫的比例為55.7%。雖然看起來使用一個數據庫的比例還是更多,但不能忽略一點,多數據庫的使用在過去10年出現了爆炸式增長。
數據顯示,75.6%的多數據庫類型組合使用了SQL和NoSQL數據庫。這進一步說明,對于許多企業來說,并不能一刀切。
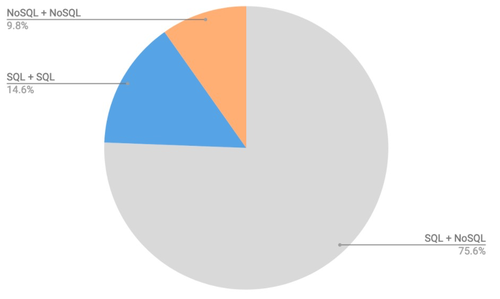
圖片及數據來源:ScaleGrid
顯然,數據格式、應用場景紛繁復雜,很多需求已經不是單一數據庫能解決的。同時,微服務架構的崛起,也在推動企業不同業務場景采用不同的數據庫,如果選擇不當,會導致服務的性能上不去。
因此,選型時不要將企業的數據庫限制在一種數據庫上,相互補充才能填補數據庫需求的空白。
選型要點
1. 業務場景
任何脫離業務場景需求的數據庫選型都是耍流氓。
數據庫選型的決定性因素是結合業務應用場景,分析目前已有的需求和未來可能會出現的新需求,來考量選擇何種數據庫。
業務用數據庫來做什么?分析還是交易?或者兩者兼而有之?業務要處理什么樣的數據?對數據庫性能需求是什么?
如果是傳統的ERP、CRM、財務等企業內部應用,需要事務完整性,保證ACID事務,那么,毫無疑問,關系型數據庫是最佳選擇。如果業務要做物聯網數據采集和監控,需要高頻、實時、持續的寫入,那么,時序數據庫是正確的選擇。
業務要處理什么樣的數據?結構化?半結構化?非結構化數據?決定需要支持的數據模型。原則上“什么數據模型,就用什么庫。”
如果你要存儲和處理的是圖片、音頻、視頻等非結構化數據,那么,NoSQL數據庫會是最佳選擇。進一步來說,業務要存儲游戲場景中的角色信息、經驗道具信息、好友排名等信息,而這些信息一般都和 ID(鍵)掛鉤,那么,鍵值數據庫是個很好的選擇。
業務需要處理的多大的數據規模、并發吞吐量、響應時間需求是什么?決定了對數據庫的性能需求。
如果業務是秒殺,春節火車票等,有超高峰值業務,那么,分布式數據庫會是一個不錯的選擇。
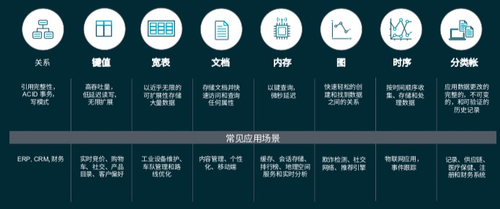
常見的數據類型和應用場景(圖片來源:AWS)
不清楚什么業務場景下應該選用哪種數據庫系統的,可以參考上圖。
2. 可運維性
有種說法,數據庫選型不考慮可運維性的都應該槍斃。雖然說法夸張,但也有其道理,畢竟,數據庫買來最后是DBA來運維,DBA的意見不能忽視。
自身團隊技術儲備如何?選型要考慮現有開發、運維人員的技能,盡量選擇學習曲線短的。
數據庫選型,很多人會忽略生態,一個好的數據庫不僅自身強大,周邊生態完善很重要。與周邊上下游產品的兼容性,配套軟件、工具、技術人才等都對可運維性產生極大影響。
每一種數據庫都不簡單,掌握都需要一個過程。數據庫發生問題,如何快速定位并解決問題?如果有個活躍的用戶社區,DBA會有信心很多。
如果選擇了一種數據庫,但招不到DBA,一旦人員流失,讓數據庫處于無人維護的境地,那也挺要命的。
良好的工具生態可以節省企業的開發及運維人員投入。例如:遷移工具,AWS DMS早在2016年3月就已推出,可以讓用戶輕松地將其數據庫遷移過來,同時避免停機。事實證明該服務很受歡迎,AWS官方數據顯示,截止到目前,DMS已經幫助20萬個數據庫進行遷移。
如果你選擇的是云數據庫,那么,有Serverless(無服務器)模式的云數據庫會讓運維更輕松,以AWS為例,Amazon Aurora Serverless,Amazon DynamoDB,Amazon TimeStream,Amazon Keyspaces,這些都是無服務器版本的數據庫,數據庫可以根應用程序需求來自動啟動、關閉以及擴展或縮減,而無需管理任何數據庫實例,能極大降低數據庫管理的工作量。因為,手動管理數據庫容量需要占用寶貴的時間,也可能導致數據庫資源的使用效率低下。
3. 成本
數據庫選型不僅要考慮部署數據庫的硬件資源成本、軟件成本、服務成本和人力成本,還要考慮隱形的成本,比如遷移成本、維護成本、學習成本,運營成本等。
隨著開源數據庫的流行,存在一種選型誤區,認為開源數據庫省錢。其實,開源數據庫未必就比商業數據庫成本低,雖然沒有License費用,但對技術團隊要求很高,對于一般傳統行業是玩不轉的,如果你的技術團隊不具備這種能力,還不如商用數據庫更省心甚至省錢。
如果想在兩者中取得平衡,那么,一些結合了新技術新硬件的新興數據庫可能是不錯的選擇。比如:AWS Aurora,既兼容主流的開源數據庫MySQL和PostgreSQL,又具備商業數據庫的性能優勢。用大白話說,就是既能省錢,性能又要優于開源數據庫。
分布式數據庫雖然很火,但也不要盲目趕時髦,要用對地方,要清楚什么場景適合分布式數據庫,什么場景不適合,否則,不僅達不到預期效果還更費錢。
寫在最后
雖然,數據庫領域各種新技術新概念不斷涌現,但還談不上誰替代誰。
目前,沒有萬能的數據庫,只有最合適的數據庫。數據庫選型還是要根據業務需求來選擇最合適的產品,切勿盲目趕時髦,去追新求熱。