算法工程師日常,訓練的模型翻車了怎么辦?
大家好,今天和大家聊一個算法工程師的職場日常——模型翻車。
我們都知道算法工程師的工作重點就是模型訓練,很多人每天的工作就是做特征、調參數(shù)然后訓練模型。所以對于算法工程師而言,最經常遇到的問題就是模型翻車了,好容易訓練出來的模型結果效果還很差。很多剛入門的小白遇上這種情況都會一籌莫展,不知道究竟是哪里出了問題。
所以今天就和大家簡單分享一下,我個人總結出來的一點簡單經驗,遇到這種情況的時候,我們應該怎么處理。
檢查樣本
整個模型訓練結果不好的排查過程可以遵守一個由大到小,由淺入深的順序。也就是說我們先從整體上、宏觀上進行排查,再去檢查一些細節(jié)的內容。
很多小白可能會有點愣頭青,上來就去檢查特征的細節(jié),而忽略了整體的檢查。導致后來花費了很多時間,才發(fā)現(xiàn)原來是樣本的比例不對或者是樣本的數(shù)量不對這種很容易發(fā)現(xiàn)的問題。不僅會浪費時間,而且給老板以及其他人的觀感不好。
所以我們先從整體入手,先檢查一下正負樣本的比例,檢查一下訓練樣本的數(shù)量。和往常的實驗相比有沒有什么變化,這種檢查往往比較簡單,可能幾分鐘就能有一個結果。如果發(fā)現(xiàn)了問題最好,沒發(fā)現(xiàn)問題也不虧,至少也算是排除了一部分原因。
檢查完了樣本的比例以及數(shù)量之后,我們接下來可以檢查一下特征的分布,看看是不是新做的特征有一些問題。這里面可能出現(xiàn)的問題就很多了,比如如果大部分特征是空的,那有兩種情況。一種是做特征的代碼有問題,可能藏著bug。還有一種是這個特征本身就很稀疏,只有少部分樣本才有值。根據(jù)我的經驗,如果特征過于稀疏,其實效果也是很差的,甚至可能會起反效果,加了還不如不加。
另外一種可能出現(xiàn)的問題就是特征的值域分布很不均勻,比如80%的特征小于10,剩下的20%最多可以到100w。這樣分布極度不平衡的特征也會拉垮模型的效果,比較好的方式對它進行分段,做成分桶特征。一般情況下特征的問題很容易通過查看分布的方法調查出來。
查看訓練曲線
很多新手評判模型的標準就是最后的一個結果,比如AUC或者是準確率,而忽略了模型在整個訓練過程當中的變化。這其實也不是一個很好的習慣,會丟失很多信息,也會忽略很多情況。
比較推薦的就是要習慣使用tensorboard來查看模型訓練的過程,tensorboard基本上現(xiàn)在主流的深度學習框架都有。通過它我們可以看到一些關鍵指標在訓練過程當中的變化,它最主要的功能就是幫助我們發(fā)現(xiàn)過擬合或者是欠擬合的情況。
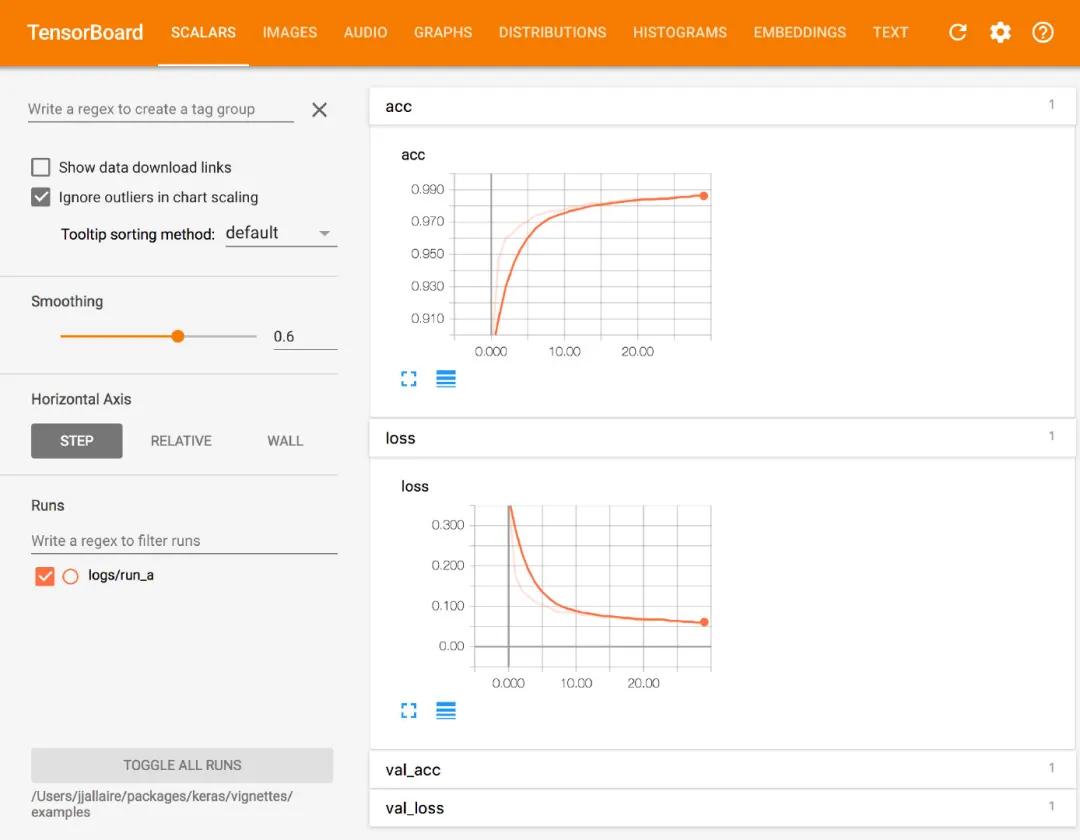
我們經常遇到的一種情況就是在原本的特征集當中,模型沒有任何問題,但是我們一旦加入了一些新的特征之后,效果就開始拉垮。我們查看日志發(fā)現(xiàn)模型訓練結束之前的這一段時間里AUC或者是其他指標還是在上漲的,就誤以為沒有問題。其實很有可能模型在中途陷入過過擬合當中,只是由于訓練時間比較長,所以被忽視了。
很多人經常吃這個虧,尤其是新手。浪費了很多時間沒有發(fā)現(xiàn)問題,其實打開tensorboard一看就知道,模型中途過擬合或者是欠擬合了,那么我們針對性地就可以采取一些措施進行補救。
參數(shù)檢查
除了上面兩者之外,還有一個排查的點就是參數(shù)。
這里的參數(shù)并不只局限于模型的訓練參數(shù),比如學習率、迭代次數(shù)、batch_size等等。也包含一些模型本身的參數(shù),像是embedding初始化的方差,embedding的size等等。
舉個簡單的例子,很多人實現(xiàn)的embedding的初始化用的是默認初始化,默認的方式方差是1。這個方差對于很多場景來說其實是有些偏大了,尤其是一些深度比較大的神經網絡,很容易出現(xiàn)梯度爆炸,很多時候我們把它調到0.001之后,效果往往都會有所提升。
雖然說模型的結構才是主體,參數(shù)只是輔助的,但這并不表示參數(shù)不會影響模型的效果。相反,有的時候影響還不小,我們不能忽視。當然要做到這一點,我們不僅需要知道每一個參數(shù)對應的意義,也需要了解模型的結構,以及模型運行的原理,這樣才能對參數(shù)起到的效果和意義有所推測。不然的話,只是生搬硬套顯然也是不行的。
場景思考
上面提到的三點都還算是比較明顯的,接下來和大家聊聊一點隱藏得比較深的,這也是最考驗一個算法工程師功底的。
很多時候在某一個場景上效果很好的模型,換了一個場景效果就不好了,或者是一些很管用的特征突然就不管用了。這也許并不是因為有隱藏的bug,可能只是單純地模型水土不服,對于當前的場景不太適合。
拿推薦場景舉個例子,比如在首頁的推薦當中,由于我們沒有任何額外輸入的信息,只能根據(jù)用戶歷史的行為偏好來進行推薦。這個時候我們就會額外地關注用戶歷史行為和當前商品的信息的交叉和重疊的部分,著重把這些信息做成特征。但如果同樣的特征遷移到商品詳情頁下方的猜你喜歡當中去,可能就不是非常合適。
原因也很簡單,詳情頁下方的猜你喜歡召回的商品基本上都是同一類別甚至是同款商品,這就意味著這些商品本身的信息當中有大部分都是一樣或者是高度相似的。既然這些信息是高度相似的,模型很難從這些差異化很小的特征當中學到關鍵信息,那么自然也就很難獲得同樣的效果。這并非是特征或者是模型出了什么問題,可能就是單純地場景不合適。
對于場景與特征以及模型之間的理解和思考才是最考驗一個算法工程師能力和經驗的部分,新人的注意力往往關注不到這個方面,更多地還是局限在特征和模型本身。有的時候,我們的思維不能順著一條線毫無阻礙地往下走,也需要經常停下來反思一下,我這么思考有沒有忽略什么問題。
本文轉載自微信公眾號「TechFlow」,可以通過以下二維碼關注。轉載本文請聯(lián)系TechFlow公眾號。